 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswering Questions in Stages: Prompt Chaining for Contract QA
Oct 09, 2024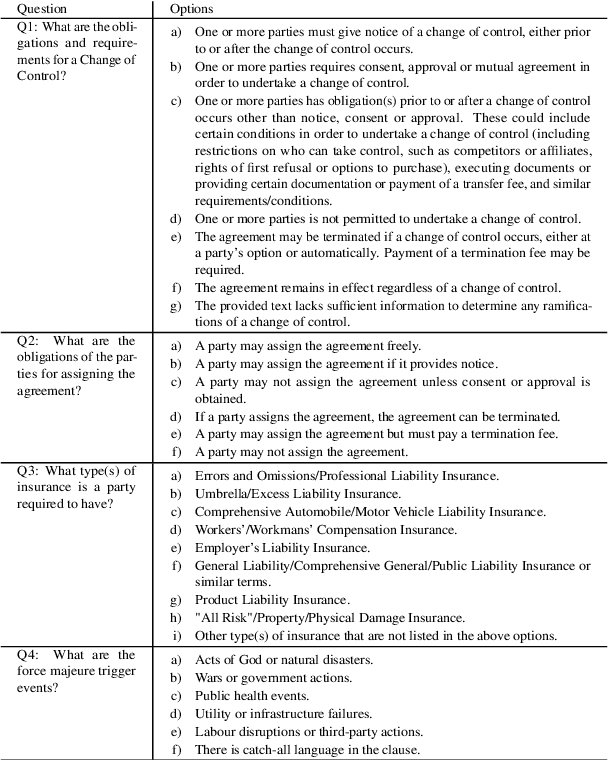


Finding answers to legal questions about clauses in contracts is an important form of analysis in many legal workflows (e.g., understanding market trends, due diligence, risk mitigation) but more important is being able to do this at scale. Prior work showed that it is possible to use large language models with simple zero-shot prompts to generate structured answers to questions, which can later be incorporated into legal workflows. Such prompts, while effective on simple and straightforward clauses, fail to perform when the clauses are long and contain information not relevant to the question. In this paper, we propose two-stage prompt chaining to produce structured answers to multiple-choice and multiple-select questions and show that they are more effective than simple prompts on more nuanced legal text. We analyze situations where this technique works well and areas where further refinement is needed, especially when the underlying linguistic variations are more than can be captured by simply specifying possible answers. Finally, we discuss future research that seeks to refine this work by improving stage one results by making them more question-specific.
A Search for Prompts: Generating Structured Answers from Contracts
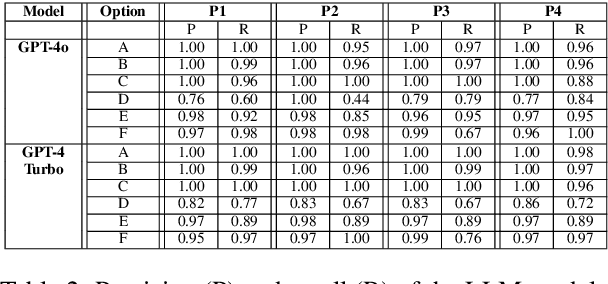
Oct 16, 2023In many legal processes being able to action on the concrete implication of a legal question can be valuable to automating human review or signalling certain conditions (e.g., alerts around automatic renewal). To support such tasks, we present a form of legal question answering that seeks to return one (or more) fixed answers for a question about a contract clause. After showing that unstructured generative question answering can have questionable outcomes for such a task, we discuss our exploration methodology for legal question answering prompts using OpenAI's \textit{GPT-3.5-Turbo} and provide a summary of insights. Using insights gleaned from our qualitative experiences, we compare our proposed template prompts against a common semantic matching approach and find that our prompt templates are far more accurate despite being less reliable in the exact response return. With some additional tweaks to prompts and the use of in-context learning, we are able to further improve the performance of our proposed strategy while maximizing the reliability of responses as best we can.
Long-Term Memory Networks for Question Answering
Jul 06, 2017
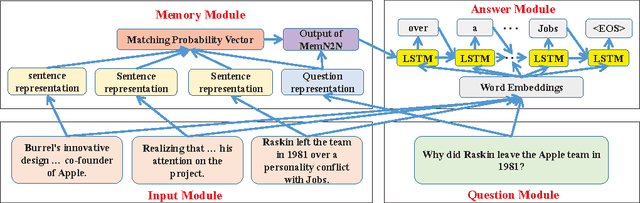

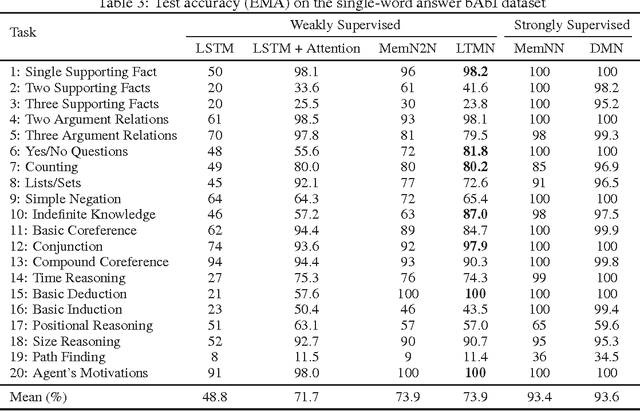
Question answering is an important and difficult task in the natural language processing domain, because many basic natural language processing tasks can be cast into a question answering task. Several deep neural network architectures have been developed recently, which employ memory and inference components to memorize and reason over text information, and generate answers to questions. However, a major drawback of many such models is that they are capable of only generating single-word answers. In addition, they require large amount of training data to generate accurate answers. In this paper, we introduce the Long-Term Memory Network (LTMN), which incorporates both an external memory module and a Long Short-Term Memory (LSTM) module to comprehend the input data and generate multi-word answers. The LTMN model can be trained end-to-end using back-propagation and requires minimal supervision. We test our model on two synthetic data sets (based on Facebook's bAbI data set) and the real-world Stanford question answering data set, and show that it can achieve state-of-the-art performance.
Dipole: Diagnosis Prediction in Healthcare via Attention-based Bidirectional Recurrent Neural Networks
Jun 19, 2017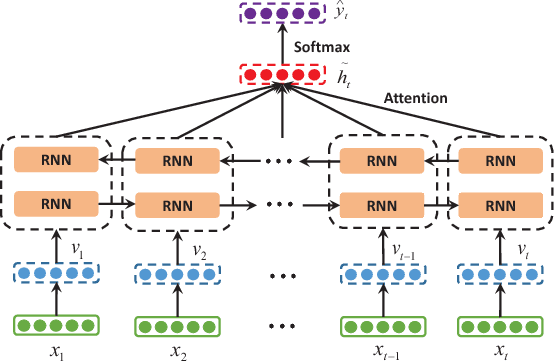
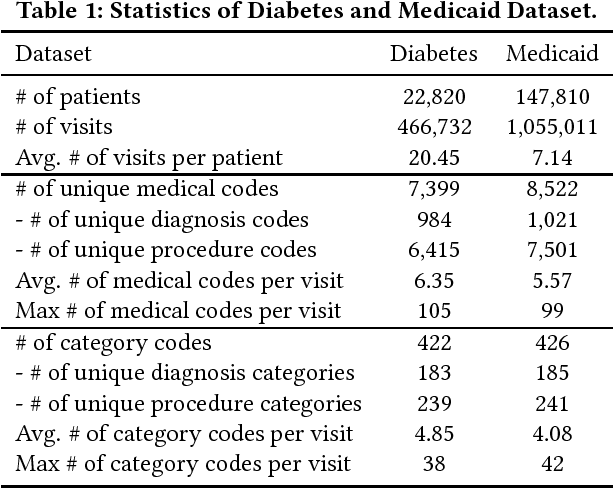
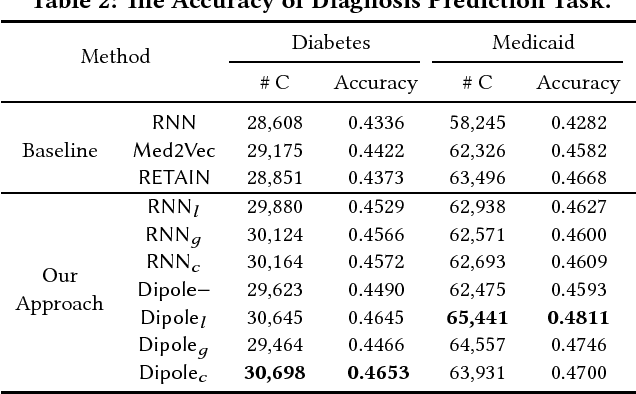
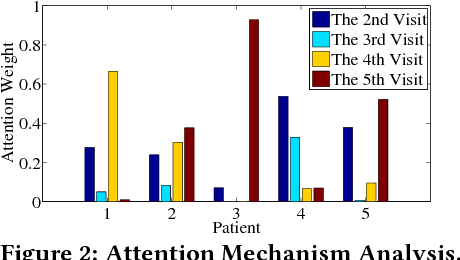
Predicting the future health information of patients from the historical Electronic Health Records (EHR) is a core research task in the development of personalized healthcare. Patient EHR data consist of sequences of visits over time, where each visit contains multiple medical codes, including diagnosis, medication, and procedure codes. The most important challenges for this task are to model the temporality and high dimensionality of sequential EHR data and to interpret the prediction results. Existing work solves this problem by employing recurrent neural networks (RNNs) to model EHR data and utilizing simple attention mechanism to interpret the results. However, RNN-based approaches suffer from the problem that the performance of RNNs drops when the length of sequences is large, and the relationships between subsequent visits are ignored by current RNN-based approaches. To address these issues, we propose {\sf Dipole}, an end-to-end, simple and robust model for predicting patients' future health information. Dipole employs bidirectional recurrent neural networks to remember all the information of both the past visits and the future visits, and it introduces three attention mechanisms to measure the relationships of different visits for the prediction. With the attention mechanisms, Dipole can interpret the prediction results effectively. Dipole also allows us to interpret the learned medical code representations which are confirmed positively by medical experts. Experimental results on two real world EHR datasets show that the proposed Dipole can significantly improve the prediction accuracy compared with the state-of-the-art diagnosis prediction approaches and provide clinically meaningful interpretation.
Deep Multimodal Representation Learning from Temporal Data
Apr 11, 2017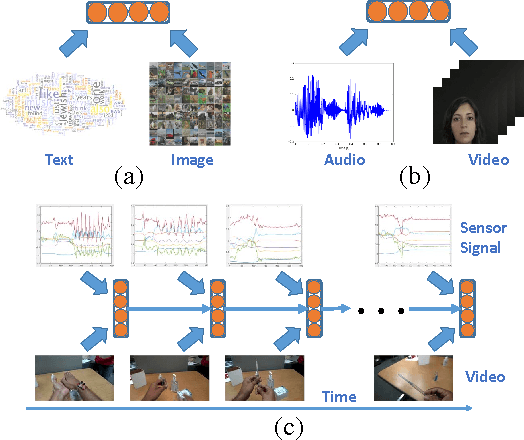
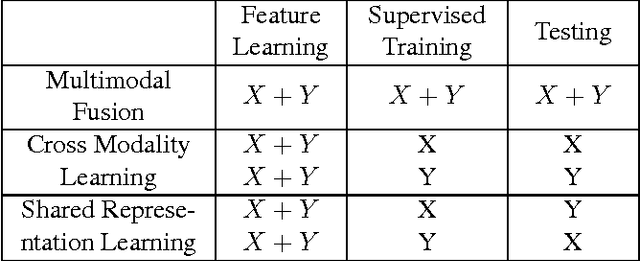
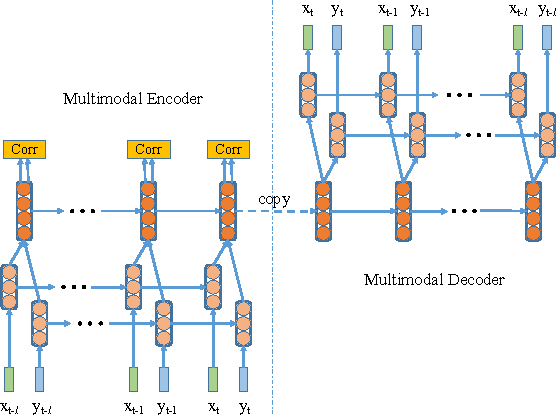

In recent years, Deep Learning has been successfully applied to multimodal learning problems, with the aim of learning useful joint representations in data fusion applications. When the available modalities consist of time series data such as video, audio and sensor signals, it becomes imperative to consider their temporal structure during the fusion process. In this paper, we propose the Correlational Recurrent Neural Network (CorrRNN), a novel temporal fusion model for fusing multiple input modalities that are inherently temporal in nature. Key features of our proposed model include: (i) simultaneous learning of the joint representation and temporal dependencies between modalities, (ii) use of multiple loss terms in the objective function, including a maximum correlation loss term to enhance learning of cross-modal information, and (iii) the use of an attention model to dynamically adjust the contribution of different input modalities to the joint representation. We validate our model via experimentation on two different tasks: video- and sensor-based activity classification, and audio-visual speech recognition. We empirically analyze the contributions of different components of the proposed CorrRNN model, and demonstrate its robustness, effectiveness and state-of-the-art performance on multiple datasets.
Scalable Kernel Clustering: Approximate Kernel k-means
Feb 16, 2014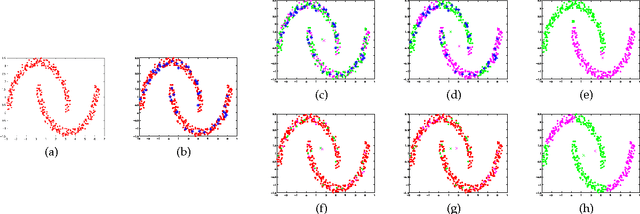
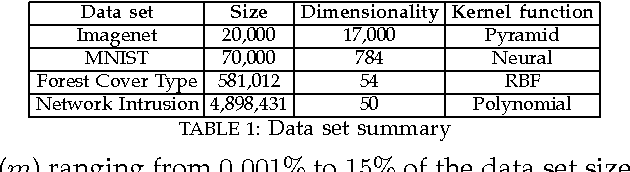
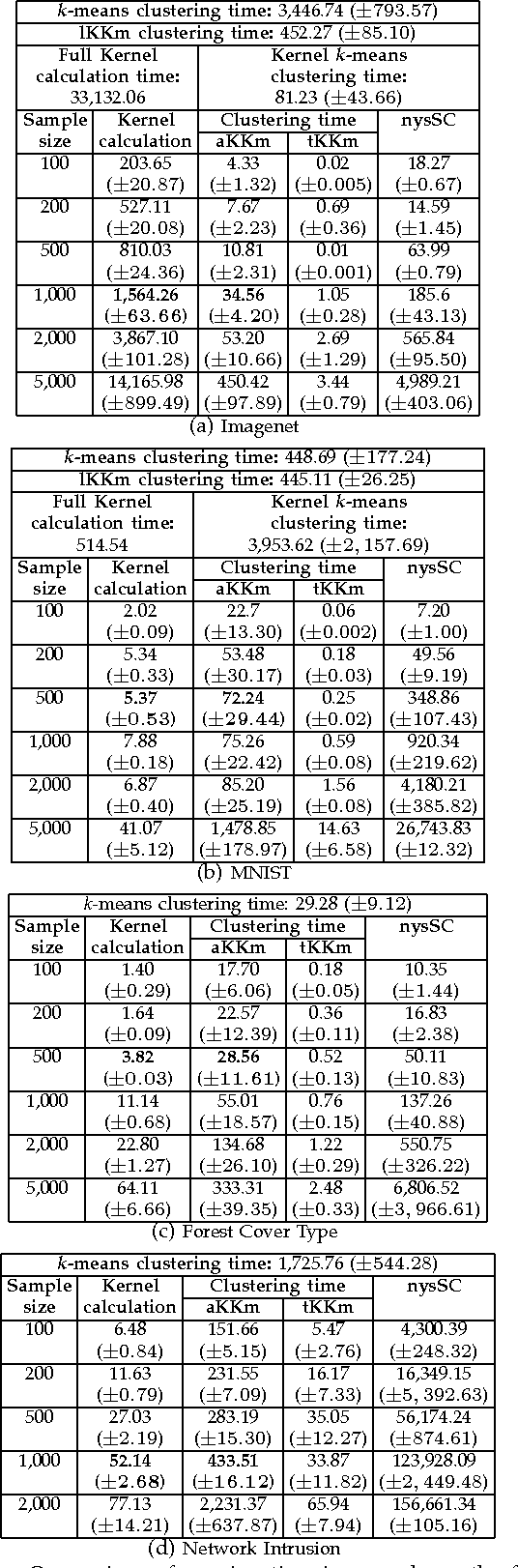
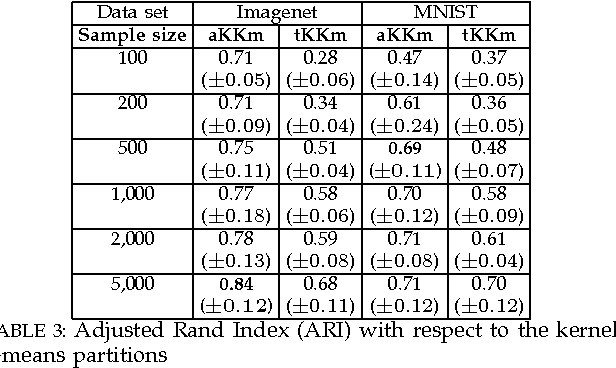
Kernel-based clustering algorithms have the ability to capture the non-linear structure in real world data. Among various kernel-based clustering algorithms, kernel k-means has gained popularity due to its simple iterative nature and ease of implementation. However, its run-time complexity and memory footprint increase quadratically in terms of the size of the data set, and hence, large data sets cannot be clustered efficiently. In this paper, we propose an approximation scheme based on randomization, called the Approximate Kernel k-means. We approximate the cluster centers using the kernel similarity between a few sampled points and all the points in the data set. We show that the proposed method achieves better clustering performance than the traditional low rank kernel approximation based clustering schemes. We also demonstrate that its running time and memory requirements are significantly lower than those of kernel k-means, with only a small reduction in the clustering quality on several public domain large data sets. We then employ ensemble clustering techniques to further enhance the performance of our algorithm.