 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-STPA: Adapting System-Theoretic Hazard Analysis for Safety-Critical Reinforcement Learning
Apr 16, 2026As reinforcement learning (RL) deployments expand into safety-critical domains, existing evaluation methods fail to systematically identify hazards arising from the black-box nature of neural network enabled policies and distributional shift between training and deployment. This paper introduces Reinforcement Learning System-Theoretic Process Analysis (RL-STPA), a framework that adapts conventional STPA's systematic hazard analysis to address RL's unique challenges through three key contributions: hierarchical subtask decomposition using both temporal phase analysis and domain expertise to capture emergent behaviors, coverage-guided perturbation testing that explores the sensitivity of state-action spaces, and iterative checkpoints that feed identified hazards back into training through reward shaping and curriculum design. We demonstrate RL-STPA in the safety-critical test case of autonomous drone navigation and landing, revealing potential loss scenarios that can be missed by standard RL evaluations. The proposed framework provides practitioners with a toolkit for systematic hazard analysis, quantitative metrics for safety coverage assessment, and actionable guidelines for establishing operational safety bounds. While RL-STPA cannot provide formal guarantees for arbitrary neural policies, it offers a practical methodology for systematically evaluating and improving RL safety and robustness in safety-critical applications where exhaustive verification methods remain intractable.
Evaluating the Impact of Underwater Image Enhancement on Object Detection Performance: A Comprehensive Study
Nov 26, 2024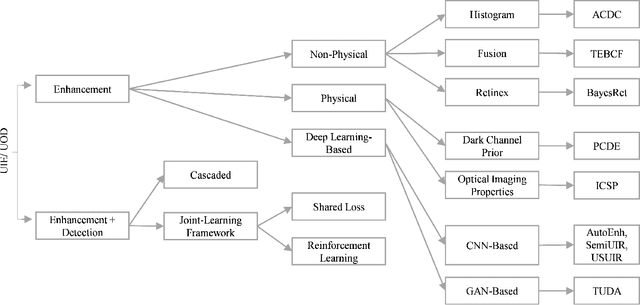
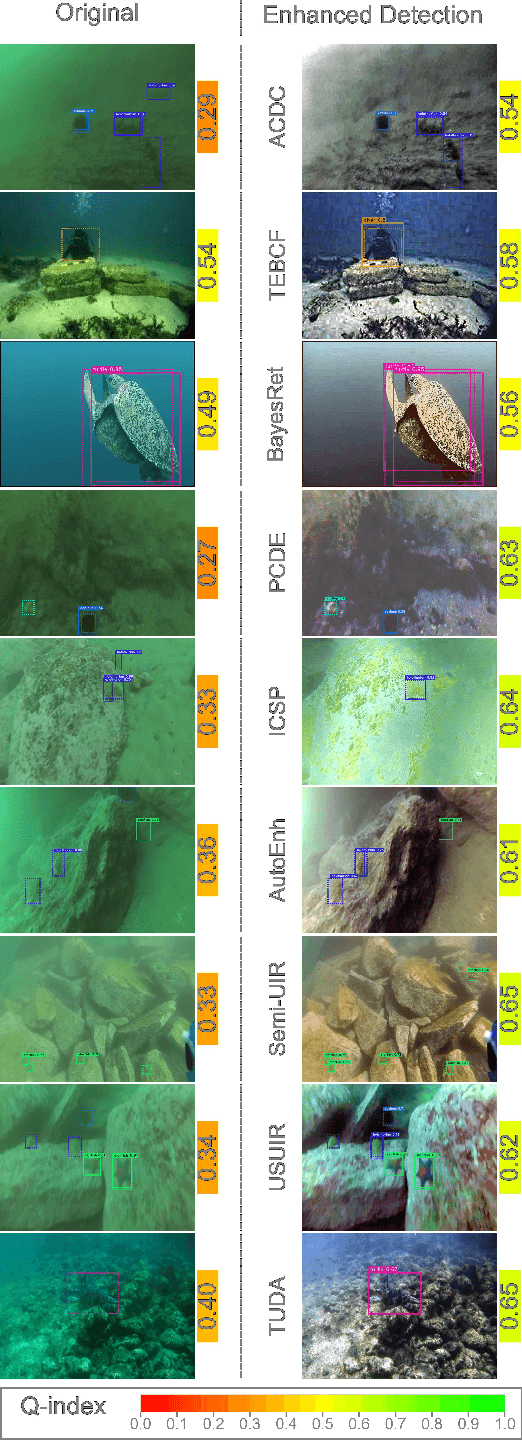

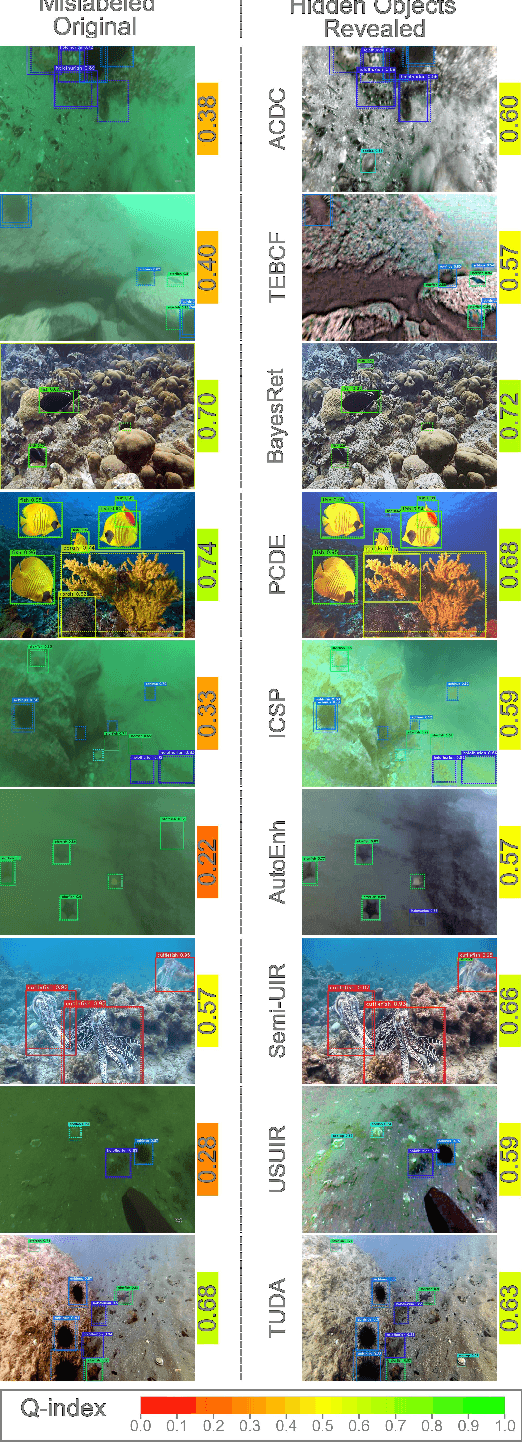
Underwater imagery often suffers from severe degradation that results in low visual quality and object detection performance. This work aims to evaluate state-of-the-art image enhancement models, investigate their impact on underwater object detection, and explore their potential to improve detection performance. To this end, we selected representative underwater image enhancement models covering major enhancement categories and applied them separately to two recent datasets: 1) the Real-World Underwater Object Detection Dataset (RUOD), and 2) the Challenging Underwater Plant Detection Dataset (CUPDD). Following this, we conducted qualitative and quantitative analyses on the enhanced images and developed a quality index (Q-index) to compare the quality distribution of the original and enhanced images. Subsequently, we compared the performance of several YOLO-NAS detection models that are separately trained and tested on the original and enhanced image sets. Then, we performed a correlation study to examine the relationship between enhancement metrics and detection performance. We also analyzed the inference results from the trained detectors presenting cases where enhancement increased the detection performance as well as cases where enhancement revealed missed objects by human annotators. This study suggests that although enhancement generally deteriorates the detection performance, it can still be harnessed in some cases for increased detection performance and more accurate human annotation.
Machine Learning for Shipwreck Segmentation from Side Scan Sonar Imagery: Dataset and Benchmark
Jan 25, 2024Open-source benchmark datasets have been a critical component for advancing machine learning for robot perception in terrestrial applications. Benchmark datasets enable the widespread development of state-of-the-art machine learning methods, which require large datasets for training, validation, and thorough comparison to competing approaches. Underwater environments impose several operational challenges that hinder efforts to collect large benchmark datasets for marine robot perception. Furthermore, a low abundance of targets of interest relative to the size of the search space leads to increased time and cost required to collect useful datasets for a specific task. As a result, there is limited availability of labeled benchmark datasets for underwater applications. We present the AI4Shipwrecks dataset, which consists of 24 distinct shipwreck sites totaling 286 high-resolution labeled side scan sonar images to advance the state-of-the-art in autonomous sonar image understanding. We leverage the unique abundance of targets in Thunder Bay National Marine Sanctuary in Lake Huron, MI, to collect and compile a sonar imagery benchmark dataset through surveys with an autonomous underwater vehicle (AUV). We consulted with expert marine archaeologists for the labeling of robotically gathered data. We then leverage this dataset to perform benchmark experiments for comparison of state-of-the-art supervised segmentation methods, and we present insights on opportunities and open challenges for the field. The dataset and benchmarking tools will be released as an open-source benchmark dataset to spur innovation in machine learning for Great Lakes and ocean exploration. The dataset and accompanying software are available at https://umfieldrobotics.github.io/ai4shipwrecks/.
Deep Convolutional Autoencoder for Assessment of Anomalies in Multi-stream Sensor Data
Feb 15, 2022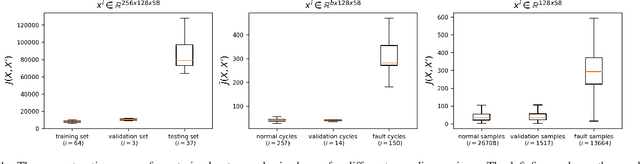
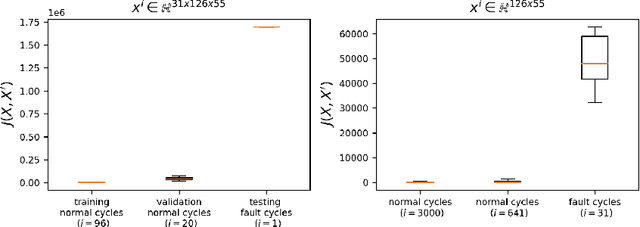
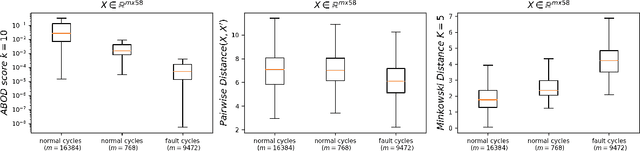
A fully convolutional autoencoder is developed for the detection of anomalies in multi-sensor vehicle drive-cycle data from the powertrain domain. Preliminary results collected on real-world powertrain data show that the reconstruction error of faulty drive cycles deviates significantly relative to the reconstruction of healthy drive cycles using the trained autoencoder. The results demonstrate applicability for identifying faulty drive-cycles, and for improving the accuracy of system prognosis and predictive maintenance in connected vehicles.
Machine learning method for light field refocusing
Mar 30, 2021

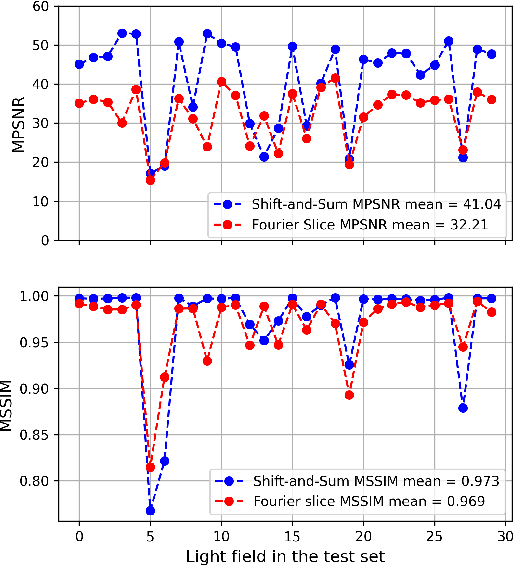

Light field imaging introduced the capability to refocus an image after capturing. Currently there are two popular methods for refocusing, shift-and-sum and Fourier slice methods. Neither of these two methods can refocus the light field in real-time without any pre-processing. In this paper we introduce a machine learning based refocusing technique that is capable of extracting 16 refocused images with refocusing parameters of \alpha=0.125,0.250,0.375,...,2.0 in real-time. We have trained our network, which is called RefNet, in two experiments. Once using the Fourier slice method as the training -- i.e., "ground truth" -- data and another using the shift-and-sum method as the training data. We showed that in both cases, not only is the RefNet method at least 134x faster than previous approaches, but also the color prediction of RefNet is superior to both Fourier slice and shift-and-sum methods while having similar depth of field and focus distance performance.
Light Field Compression by Residual CNN Assisted JPEG
Sep 30, 2020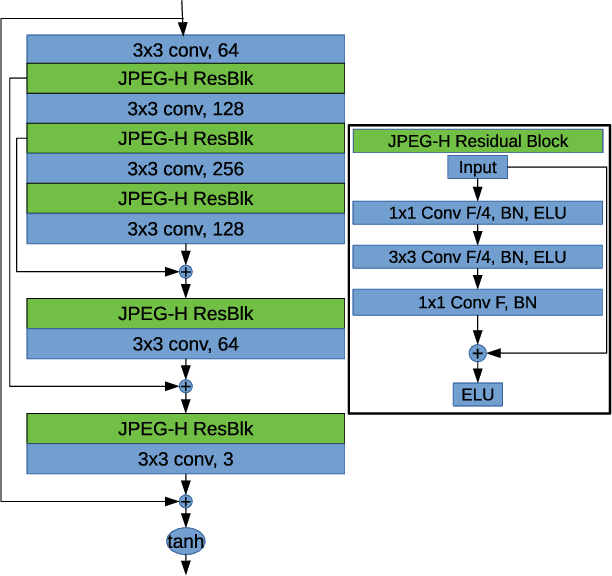

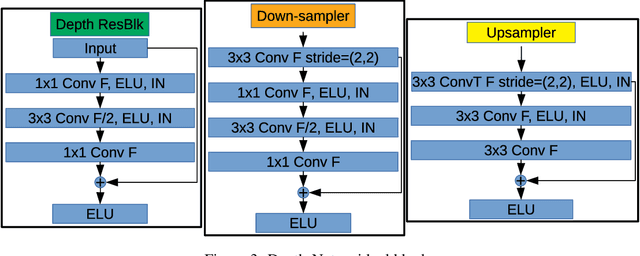
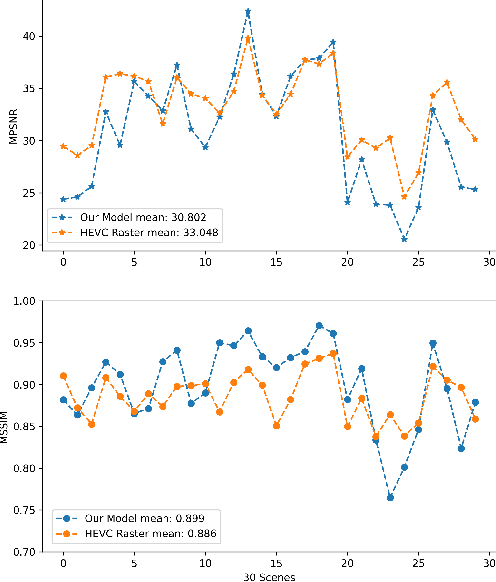
Light field (LF) imaging has gained significant attention due to its recent success in 3-dimensional (3D) displaying and rendering as well as augmented and virtual reality usage. Nonetheless, because of the two extra dimensions, LFs are much larger than conventional images. We develop a JPEG-assisted learning-based technique to reconstruct an LF from a JPEG bitstream with a bit per pixel ratio of 0.0047 on average. For compression, we keep the LF's center view and use JPEG compression with 50\% quality. Our reconstruction pipeline consists of a small JPEG enhancement network (JPEG-Hance), a depth estimation network (Depth-Net), followed by view synthesizing by warping the enhanced center view. Our pipeline is significantly faster than using video compression on pseudo-sequences extracted from an LF, both in compression and decompression, while maintaining effective performance. We show that with a 1\% compression time cost and 18x speedup for decompression, our methods reconstructed LFs have better structural similarity index metric (SSIM) and comparable peak signal-to-noise ratio (PSNR) compared to the state-of-the-art video compression techniques used to compress LFs.
Enabling Explainable Fusion in Deep Learning with Fuzzy Integral Neural Networks
May 10, 2019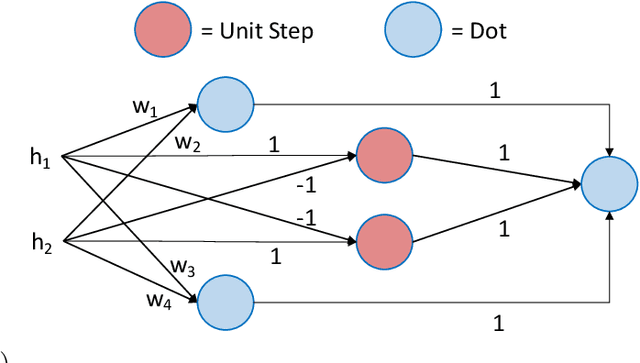
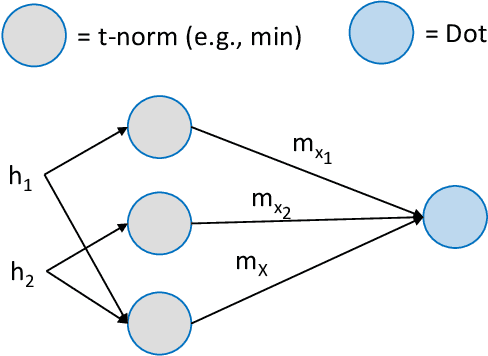
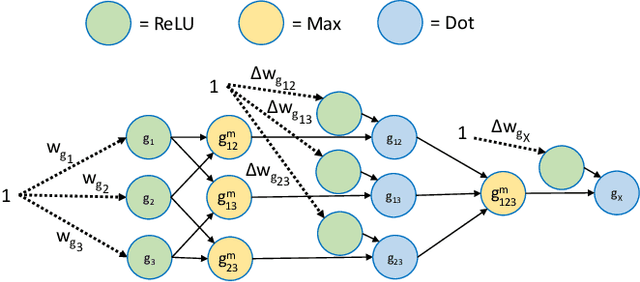
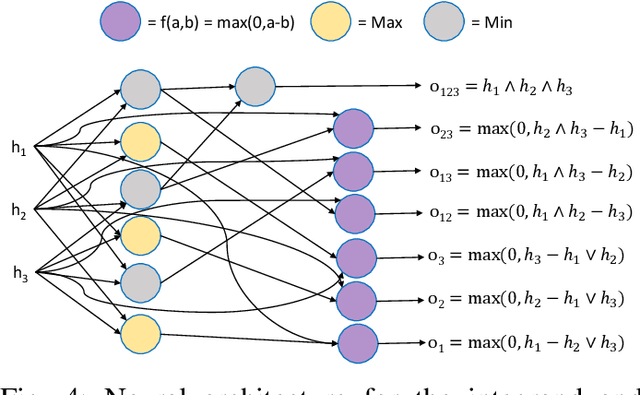
Information fusion is an essential part of numerous engineering systems and biological functions, e.g., human cognition. Fusion occurs at many levels, ranging from the low-level combination of signals to the high-level aggregation of heterogeneous decision-making processes. While the last decade has witnessed an explosion of research in deep learning, fusion in neural networks has not observed the same revolution. Specifically, most neural fusion approaches are ad hoc, are not understood, are distributed versus localized, and/or explainability is low (if present at all). Herein, we prove that the fuzzy Choquet integral (ChI), a powerful nonlinear aggregation function, can be represented as a multi-layer network, referred to hereafter as ChIMP. We also put forth an improved ChIMP (iChIMP) that leads to a stochastic gradient descent-based optimization in light of the exponential number of ChI inequality constraints. An additional benefit of ChIMP/iChIMP is that it enables eXplainable AI (XAI). Synthetic validation experiments are provided and iChIMP is applied to the fusion of a set of heterogeneous architecture deep models in remote sensing. We show an improvement in model accuracy and our previously established XAI indices shed light on the quality of our data, model, and its decisions.
Scalable Kernel Clustering: Approximate Kernel k-means
Feb 16, 2014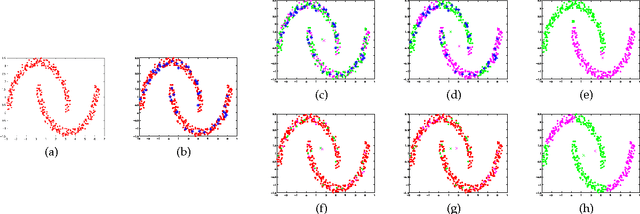
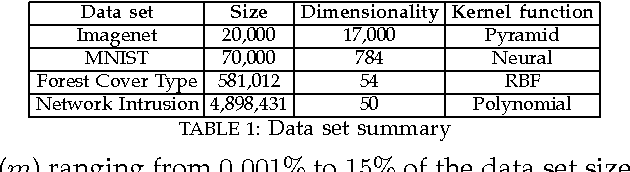
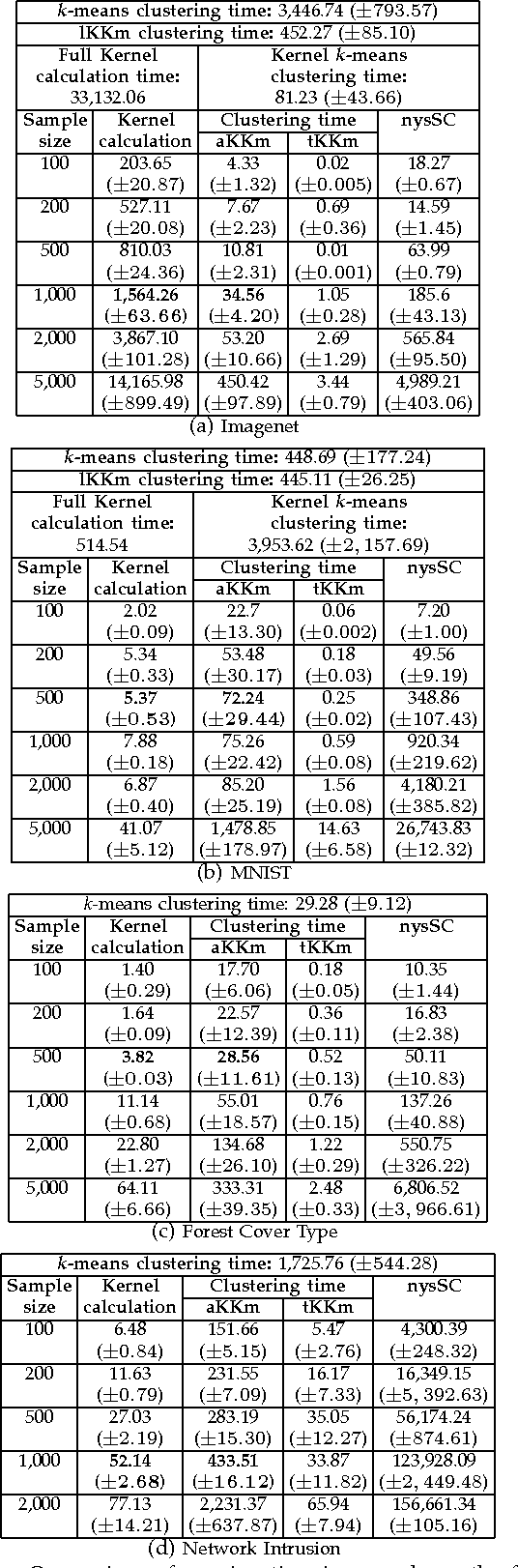
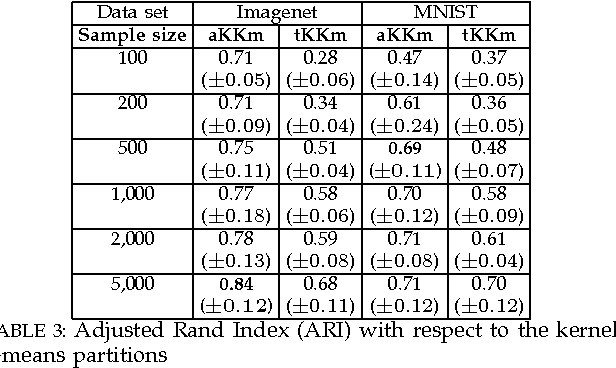
Kernel-based clustering algorithms have the ability to capture the non-linear structure in real world data. Among various kernel-based clustering algorithms, kernel k-means has gained popularity due to its simple iterative nature and ease of implementation. However, its run-time complexity and memory footprint increase quadratically in terms of the size of the data set, and hence, large data sets cannot be clustered efficiently. In this paper, we propose an approximation scheme based on randomization, called the Approximate Kernel k-means. We approximate the cluster centers using the kernel similarity between a few sampled points and all the points in the data set. We show that the proposed method achieves better clustering performance than the traditional low rank kernel approximation based clustering schemes. We also demonstrate that its running time and memory requirements are significantly lower than those of kernel k-means, with only a small reduction in the clustering quality on several public domain large data sets. We then employ ensemble clustering techniques to further enhance the performance of our algorithm.