 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBroad Area Search and Detection of Surface-to-Air Missile Sites Using Spatial Fusion of Component Object Detections from Deep Neural Networks
Mar 23, 2020

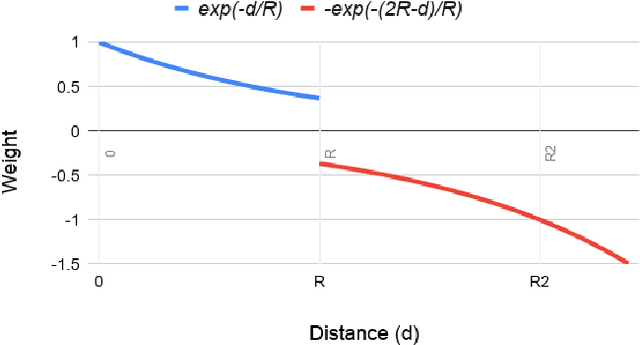
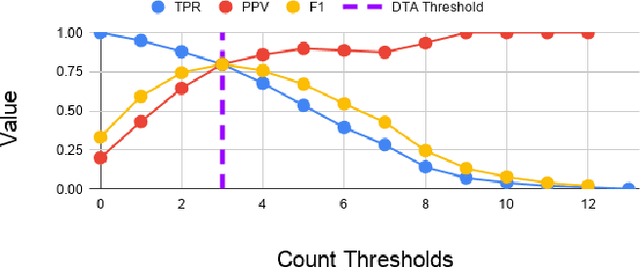
Here we demonstrate how Deep Neural Network (DNN) detections of multiple constitutive or component objects that are part of a larger, more complex, and encompassing feature can be spatially fused to improve the search, detection, and retrieval (ranking) of the larger complex feature. First, scores computed from a spatial clustering algorithm are normalized to a reference space so that they are independent of image resolution and DNN input chip size. Then, multi-scale DNN detections from various component objects are fused to improve the detection and retrieval of DNN detections of a larger complex feature. We demonstrate the utility of this approach for broad area search and detection of Surface-to-Air Missile (SAM) sites that have a very low occurrence rate (only 16 sites) over a ~90,000 km^2 study area in SE China. The results demonstrate that spatial fusion of multi-scale component-object DNN detections can reduce the detection error rate of SAM Sites by $>$85% while still maintaining a 100% recall. The novel spatial fusion approach demonstrated here can be easily extended to a wide variety of other challenging object search and detection problems in large-scale remote sensing image datasets.
Introducing Fuzzy Layers for Deep Learning
Feb 21, 2020


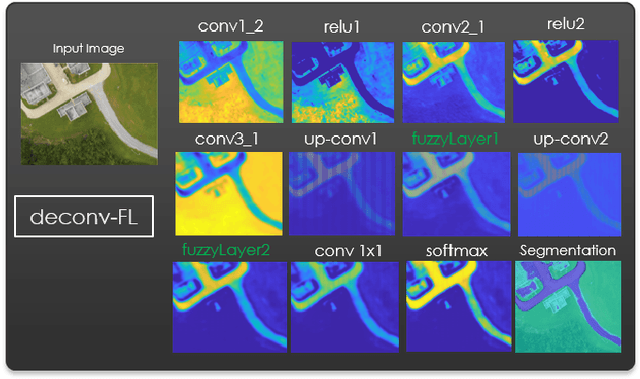
Many state-of-the-art technologies developed in recent years have been influenced by machine learning to some extent. Most popular at the time of this writing are artificial intelligence methodologies that fall under the umbrella of deep learning. Deep learning has been shown across many applications to be extremely powerful and capable of handling problems that possess great complexity and difficulty. In this work, we introduce a new layer to deep learning: the fuzzy layer. Traditionally, the network architecture of neural networks is composed of an input layer, some combination of hidden layers, and an output layer. We propose the introduction of fuzzy layers into the deep learning architecture to exploit the powerful aggregation properties expressed through fuzzy methodologies, such as the Choquet and Sugueno fuzzy integrals. To date, fuzzy approaches taken to deep learning have been through the application of various fusion strategies at the decision level to aggregate outputs from state-of-the-art pre-trained models, e.g., AlexNet, VGG16, GoogLeNet, Inception-v3, ResNet-18, etc. While these strategies have been shown to improve accuracy performance for image classification tasks, none have explored the use of fuzzified intermediate, or hidden, layers. Herein, we present a new deep learning strategy that incorporates fuzzy strategies into the deep learning architecture focused on the application of semantic segmentation using per-pixel classification. Experiments are conducted on a benchmark data set as well as a data set collected via an unmanned aerial system at a U.S. Army test site for the task of automatic road segmentation, and preliminary results are promising.
* 6 pages, 4 figures, published in 2019 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE)
Deep Morphological Hit-or-Miss Transform Neural Network
Dec 04, 2019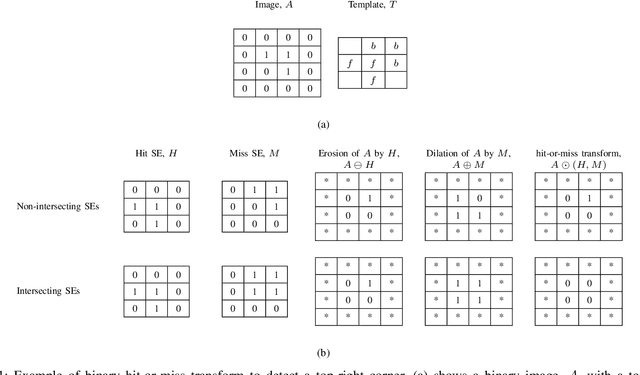
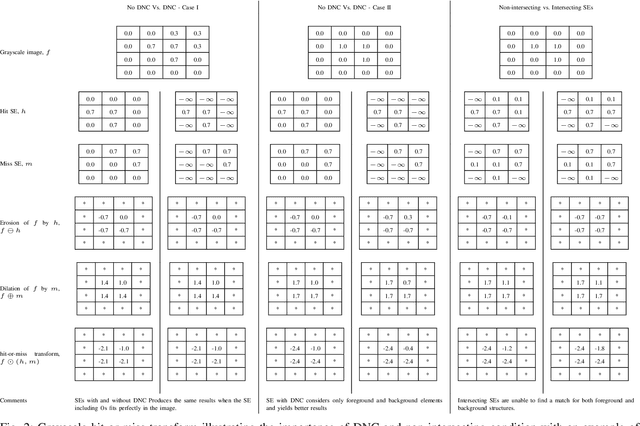


Neural networks have demonstrated breakthrough results in numerous application domains. While most architectures are built on the premise of convolution, alternative foundations like morphology are being explored for reasons like interpretability and its connection to the analysis and processing of geometric structures. Herein, we investigate new deep networks based on the morphological hit-or-miss transform. The hit-or-miss takes into account both foreground and background when measuring the fitness of a target shape in an image. We identify limitations of current hit-or-miss definitions, and we formulate an optimization problem to learn the transform. Our analysis shows that convolution, in fact, acts like a hit-miss transform through semantic interpretation of its filter differences. Analogous to the generalized hit-or-miss transform, we also introduce an extension of convolution and show that it outperforms conventional convolution on benchmark data sets. We conducted experiments on synthetic and benchmark data sets, and we show that the direct encoding hit-or-miss transform provides better interpretability on learned shapes consistent with objects whereas our morphologically inspired generalized convolution yields higher classification accuracy.
Recognizing Image Objects by Relational Analysis Using Heterogeneous Superpixels and Deep Convolutional Features
Aug 02, 2019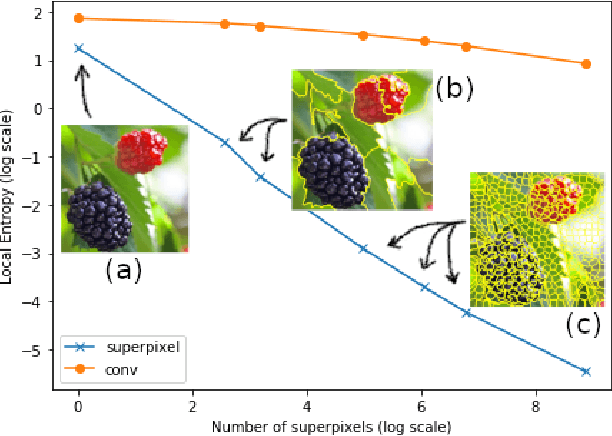



Superpixel-based methodologies have become increasingly popular in computer vision, especially when the computation is too expensive in time or memory to perform with a large number of pixels or features. However, rarely is superpixel segmentation examined within the context of deep convolutional neural network architectures. This paper presents a novel neural architecture that exploits the superpixel feature space. The visual feature space is organized using superpixels to provide the neural network with a substructure of the images. As the superpixels associate the visual feature space with parts of the objects in an image, the visual feature space is transformed into a structured vector representation per superpixel. It is shown that it is feasible to learn superpixel features using capsules and it is potentially beneficial to perform image analysis in such a structured manner. This novel deep learning architecture is examined in the context of an image classification task, highlighting explicit interpretability (explainability) of the network's decision making. The results are compared against a baseline deep neural model, as well as among superpixel capsule networks with a variety of hyperparameter settings.
Fusion of heterogeneous bands and kernels in hyperspectral image processing
May 22, 2019Hyperspectral imaging is a powerful technology that is plagued by large dimensionality. Herein, we explore a way to combat that hindrance via non-contiguous and contiguous (simpler to realize sensor) band grouping for dimensionality reduction. Our approach is different in the respect that it is flexible and it follows a well-studied process of visual clustering in high-dimensional spaces. Specifically, we extend the improved visual assessment of cluster tendency and clustering in ordered dissimilarity data unsupervised clustering algorithms for supervised hyperspectral learning. In addition, we propose a way to extract diverse features via the use of different proximity metrics (ways to measure the similarity between bands) and kernel functions. The discovered features are fused with $l_{\infty}$-norm multiple kernel learning. Experiments are conducted on two benchmark datasets and our results are compared to related work. These datasets indicate that contiguous or not is application specific, but heterogeneous features and kernels usually lead to performance gain.
Enabling Explainable Fusion in Deep Learning with Fuzzy Integral Neural Networks
May 10, 2019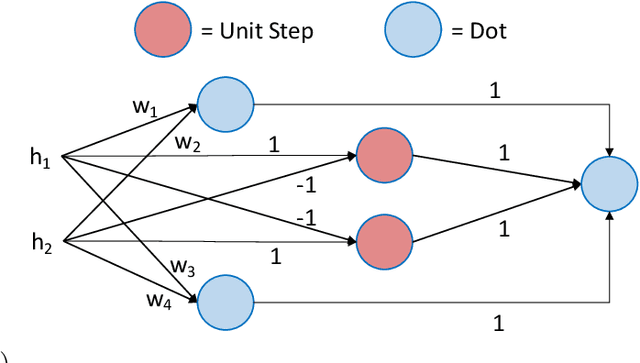
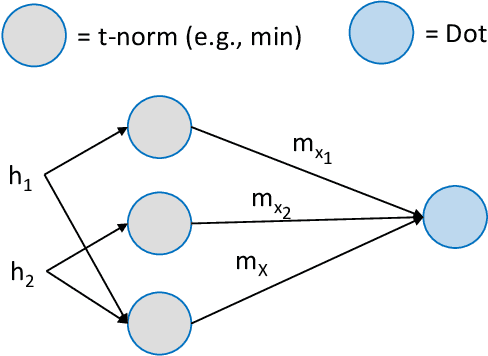
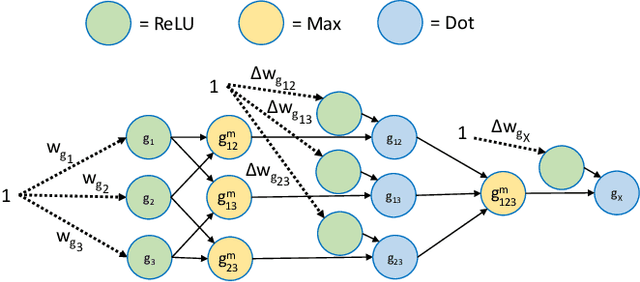
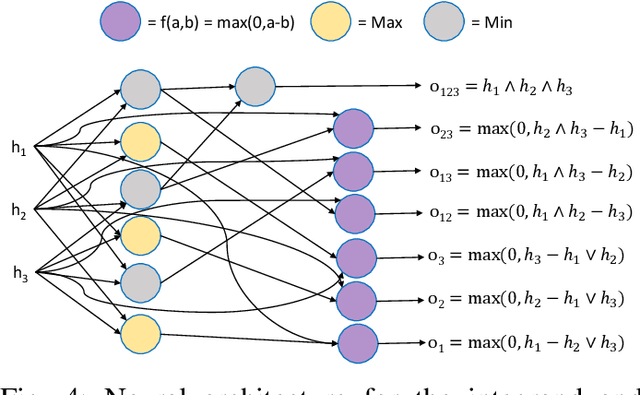
Information fusion is an essential part of numerous engineering systems and biological functions, e.g., human cognition. Fusion occurs at many levels, ranging from the low-level combination of signals to the high-level aggregation of heterogeneous decision-making processes. While the last decade has witnessed an explosion of research in deep learning, fusion in neural networks has not observed the same revolution. Specifically, most neural fusion approaches are ad hoc, are not understood, are distributed versus localized, and/or explainability is low (if present at all). Herein, we prove that the fuzzy Choquet integral (ChI), a powerful nonlinear aggregation function, can be represented as a multi-layer network, referred to hereafter as ChIMP. We also put forth an improved ChIMP (iChIMP) that leads to a stochastic gradient descent-based optimization in light of the exponential number of ChI inequality constraints. An additional benefit of ChIMP/iChIMP is that it enables eXplainable AI (XAI). Synthetic validation experiments are provided and iChIMP is applied to the fusion of a set of heterogeneous architecture deep models in remote sensing. We show an improvement in model accuracy and our previously established XAI indices shed light on the quality of our data, model, and its decisions.
State-of-the-art and gaps for deep learning on limited training data in remote sensing
Jul 11, 2018Deep learning usually requires big data, with respect to both volume and variety. However, most remote sensing applications only have limited training data, of which a small subset is labeled. Herein, we review three state-of-the-art approaches in deep learning to combat this challenge. The first topic is transfer learning, in which some aspects of one domain, e.g., features, are transferred to another domain. The next is unsupervised learning, e.g., autoencoders, which operate on unlabeled data. The last is generative adversarial networks, which can generate realistic looking data that can fool the likes of both a deep learning network and human. The aim of this article is to raise awareness of this dilemma, to direct the reader to existing work and to highlight current gaps that need solving.
* arXiv admin note: text overlap with arXiv:1709.00308
Fusion of an Ensemble of Augmented Image Detectors for Robust Object Detection
Mar 17, 2018



A significant challenge in object detection is accurate identification of an object's position in image space, whereas one algorithm with one set of parameters is usually not enough, and the fusion of multiple algorithms and/or parameters can lead to more robust results. Herein, a new computational intelligence fusion approach based on the dynamic analysis of agreement among object detection outputs is proposed. Furthermore, we propose an online versus just in training image augmentation strategy. Experiments comparing the results both with and without fusion are presented. We demonstrate that the augmented and fused combination results are the best, with respect to higher accuracy rates and reduction of outlier influences. The approach is demonstrated in the context of cone, pedestrian and box detection for Advanced Driver Assistance Systems (ADAS) applications.
Measuring Conflict in a Multi-Source Environment as a Normal Measure
Mar 12, 2018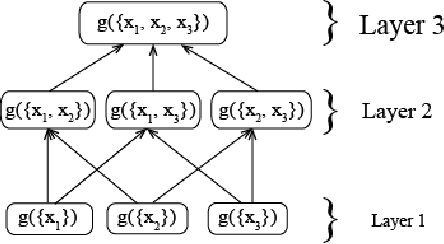
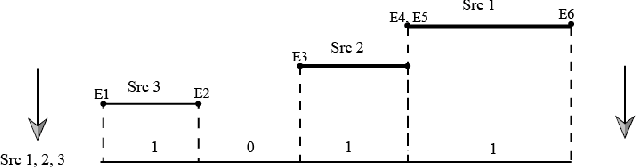

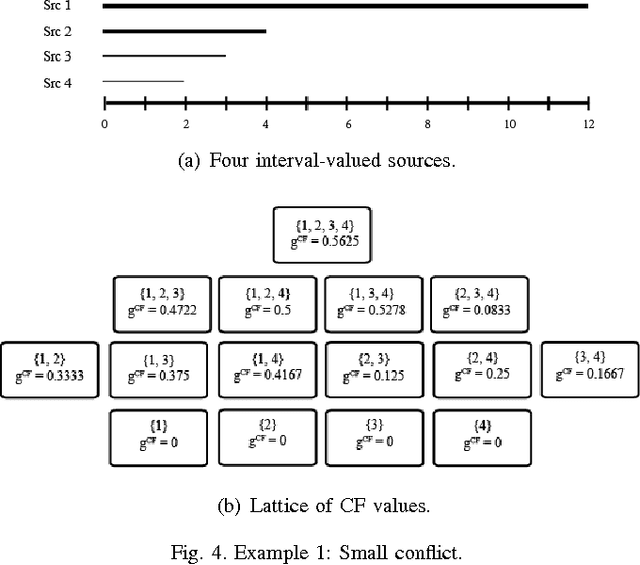
In a multi-source environment, each source has its own credibility. If there is no external knowledge about credibility then we can use the information provided by the sources to assess their credibility. In this paper, we propose a way to measure conflict in a multi-source environment as a normal measure. We examine our algorithm using three simulated examples of increasing conflict and one experimental example. The results demonstrate that the proposed measure can represent conflict in a meaningful way similar to what a human might expect and from it we can identify conflict within our sources.
* 4 pages, 8 figures, conference paper
Multi-Sensor Conflict Measurement and Information Fusion
Mar 12, 2018In sensing applications where multiple sensors observe the same scene, fusing sensor outputs can provide improved results. However, if some of the sensors are providing lower quality outputs, the fused results can be degraded. In this work, a multi-sensor conflict measure is proposed which estimates multi-sensor conflict by representing each sensor output as interval-valued information and examines the sensor output overlaps on all possible n-tuple sensor combinations. The conflict is based on the sizes of the intervals and how many sensors output values lie in these intervals. In this work, conflict is defined in terms of how little the output from multiple sensors overlap. That is, high degrees of overlap mean low sensor conflict, while low degrees of overlap mean high conflict. This work is a preliminary step towards a robust conflict and sensor fusion framework. In addition, a sensor fusion algorithm is proposed based on a weighted sum of sensor outputs, where the weights for each sensor diminish as the conflict measure increases. The proposed methods can be utilized to (1) assess a measure of multi-sensor conflict, and (2) improve sensor output fusion by lessening weighting for sensors with high conflict. Using this measure, a simulated example is given to explain the mechanics of calculating the conflict measure, and stereo camera 3D outputs are analyzed and fused. In the stereo camera case, the sensor output is corrupted by additive impulse noise, DC offset, and Gaussian noise. Impulse noise is common in sensors due to intermittent interference, a DC offset a sensor bias or registration error, and Gaussian noise represents a sensor output with low SNR. The results show that sensor output fusion based on the conflict measure shows improved accuracy over a simple averaging fusion strategy.
* 15 pages, 9 figures, conference paper