 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Cooperation in Language Games with Bayesian Inference and the Cognitive Hierarchy
Dec 16, 2024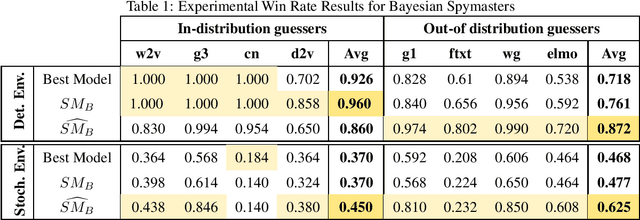
In two-player cooperative games, agents can play together effectively when they have accurate assumptions about how their teammate will behave, but may perform poorly when these assumptions are inaccurate. In language games, failure may be due to disagreement in the understanding of either the semantics or pragmatics of an utterance. We model coarse uncertainty in semantics using a prior distribution of language models and uncertainty in pragmatics using the cognitive hierarchy, combining the two aspects into a single prior distribution over possible partner types. Fine-grained uncertainty in semantics is modeled using noise that is added to the embeddings of words in the language. To handle all forms of uncertainty we construct agents that learn the behavior of their partner using Bayesian inference and use this information to maximize the expected value of a heuristic function. We test this approach by constructing Bayesian agents for the game of Codenames, and show that they perform better in experiments where semantics is uncertain
Approximate Estimation of High-dimension Execution Skill for Dynamic Agents in Continuous Domains
Aug 20, 2024In many real-world continuous action domains, human agents must decide which actions to attempt and then execute those actions to the best of their ability. However, humans cannot execute actions without error. Human performance in these domains can potentially be improved by the use of AI to aid in decision-making. One requirement for an AI to correctly reason about what actions a human agent should attempt is a correct model of that human's execution error, or skill. Recent work has demonstrated successful techniques for estimating this execution error with various types of agents across different domains. However, this previous work made several assumptions that limit the application of these ideas to real-world settings. First, previous work assumed that the error distributions were symmetric normal, which meant that only a single parameter had to be estimated. In reality, agent error distributions might exhibit arbitrary shapes and should be modeled more flexibly. Second, it was assumed that the execution error of the agent remained constant across all observations. Especially for human agents, execution error changes over time, and this must be taken into account to obtain effective estimates. To overcome both of these shortcomings, we propose a novel particle-filter-based estimator for this problem. After describing the details of this approximate estimator, we experimentally explore various design decisions and compare performance with previous skill estimators in a variety of settings to showcase the improvements. The outcome is an estimator capable of generating more realistic, time-varying execution skill estimates of agents, which can then be used to assist agents in making better decisions and improve their overall performance.
Adapting to Teammates in a Cooperative Language Game
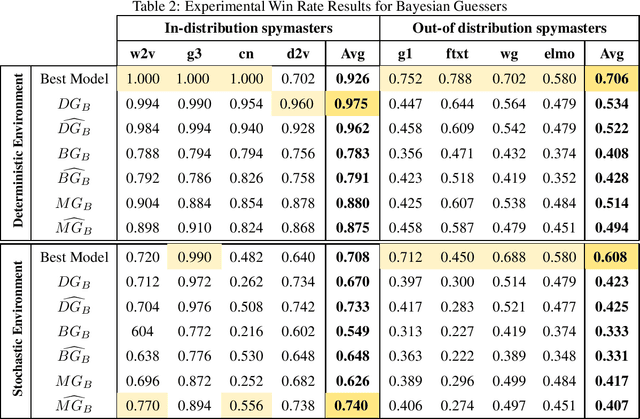
Feb 26, 2024The game of Codenames has recently emerged as a domain of interest for intelligent agent design. The game is unique due to the way that language and coordination between teammates play important roles. Previous approaches to designing agents for this game have utilized a single internal language model to determine action choices. This often leads to good performance with some teammates and inferior performance with other teammates, as the agent cannot adapt to any specific teammate. In this paper we present the first adaptive agent for playing Codenames. We adopt an ensemble approach with the goal of determining, during the course of interacting with a specific teammate, which of our internal expert agents, each potentially with its own language model, is the best match. One difficulty faced in this approach is the lack of a single numerical metric that accurately captures the performance of a Codenames team. Prior Codenames research has utilized a handful of different metrics to evaluate agent teams. We propose a novel single metric to evaluate the performance of a Codenames team, whether playing a single team (solitaire) game, or a competitive game against another team. We then present and analyze an ensemble agent which selects an internal expert on each turn in order to maximize this proposed metric. Experimental analysis shows that this ensemble approach adapts to individual teammates and often performs nearly as well as the best internal expert with a teammate. Crucially, this success does not depend on any previous knowledge about the teammates, the ensemble agents, or their compatibility. This research represents an important step to making language-based agents for cooperative language settings like Codenames more adaptable to individual teammates.
Measuring Conflict in a Multi-Source Environment as a Normal Measure
Mar 12, 2018
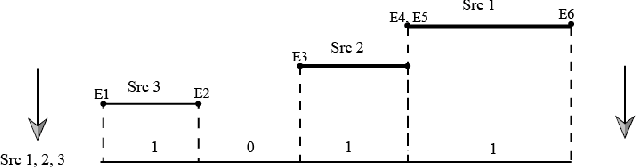

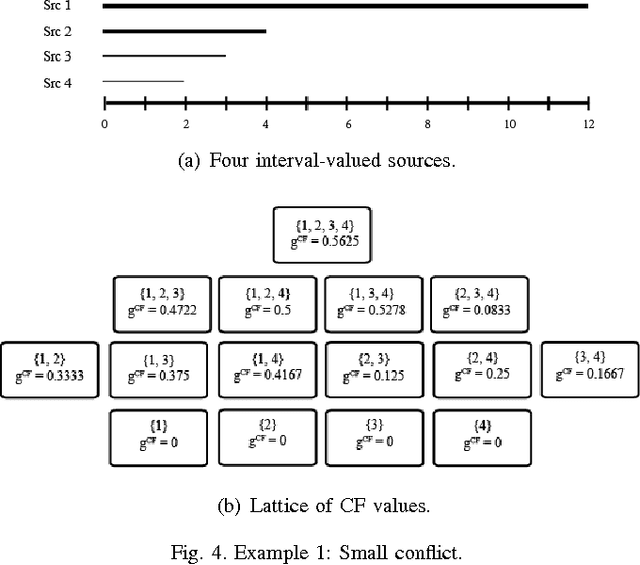
In a multi-source environment, each source has its own credibility. If there is no external knowledge about credibility then we can use the information provided by the sources to assess their credibility. In this paper, we propose a way to measure conflict in a multi-source environment as a normal measure. We examine our algorithm using three simulated examples of increasing conflict and one experimental example. The results demonstrate that the proposed measure can represent conflict in a meaningful way similar to what a human might expect and from it we can identify conflict within our sources.
* 4 pages, 8 figures, conference paper