 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALICO: Conversational Agent Localization via Synthetic Data Generation
Dec 06, 2024We present CALICO, a method to fine-tune Large Language Models (LLMs) to localize conversational agent training data from one language to another. For slots (named entities), CALICO supports three operations: verbatim copy, literal translation, and localization, i.e. generating slot values more appropriate in the target language, such as city and airport names located in countries where the language is spoken. Furthermore, we design an iterative filtering mechanism to discard noisy generated samples, which we show boosts the performance of the downstream conversational agent. To prove the effectiveness of CALICO, we build and release a new human-localized (HL) version of the MultiATIS++ travel information test set in 8 languages. Compared to the original human-translated (HT) version of the test set, we show that our new HL version is more challenging. We also show that CALICO out-performs state-of-the-art LINGUIST (which relies on literal slot translation out of context) both on the HT case, where CALICO generates more accurate slot translations, and on the HL case, where CALICO generates localized slots which are closer to the HL test set.
Knowledge Distillation Transfer Sets and their Impact on Downstream NLU Tasks
Oct 11, 2022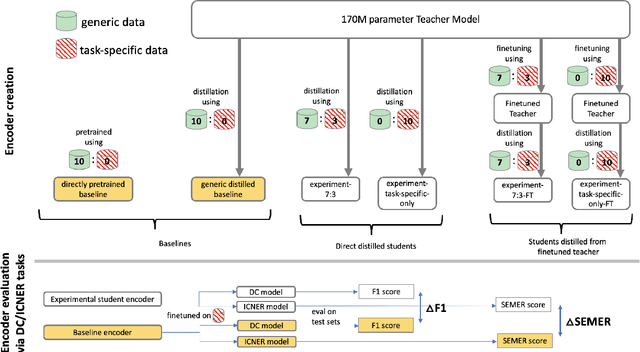
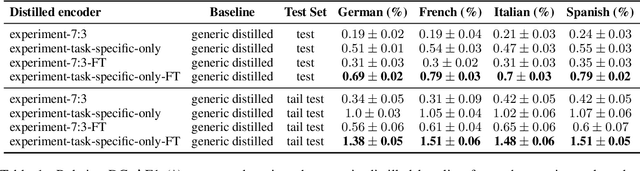
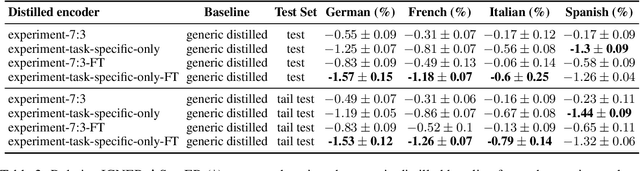
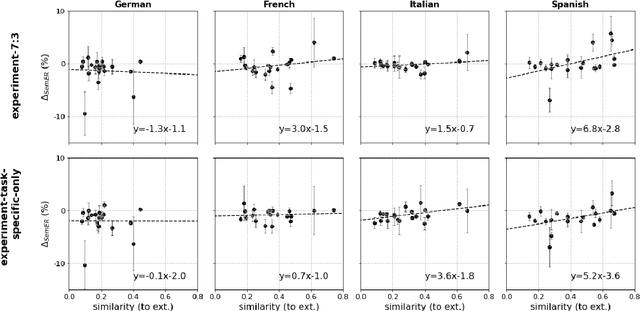
Teacher-student knowledge distillation is a popular technique for compressing today's prevailing large language models into manageable sizes that fit low-latency downstream applications. Both the teacher and the choice of transfer set used for distillation are crucial ingredients in creating a high quality student. Yet, the generic corpora used to pretrain the teacher and the corpora associated with the downstream target domain are often significantly different, which raises a natural question: should the student be distilled over the generic corpora, so as to learn from high-quality teacher predictions, or over the downstream task corpora to align with finetuning? Our study investigates this trade-off using Domain Classification (DC) and Intent Classification/Named Entity Recognition (ICNER) as downstream tasks. We distill several multilingual students from a larger multilingual LM with varying proportions of generic and task-specific datasets, and report their performance after finetuning on DC and ICNER. We observe significant improvements across tasks and test sets when only task-specific corpora is used. We also report on how the impact of adding task-specific data to the transfer set correlates with the similarity between generic and task-specific data. Our results clearly indicate that, while distillation from a generic LM benefits downstream tasks, students learn better using target domain data even if it comes at the price of noisier teacher predictions. In other words, target domain data still trumps teacher knowledge.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022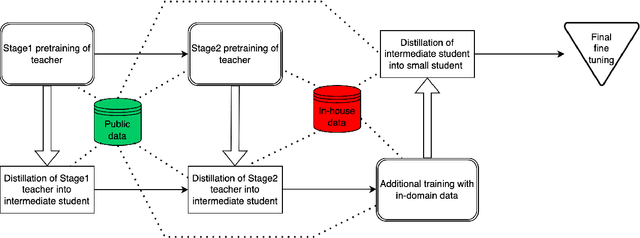
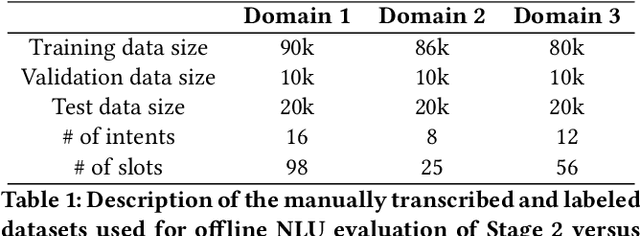
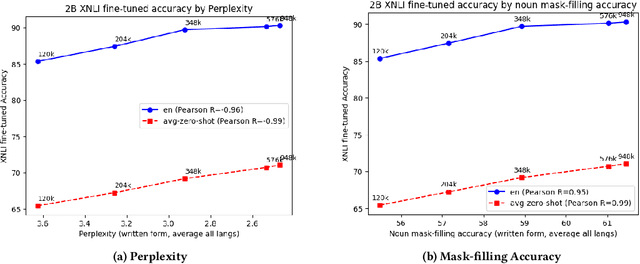
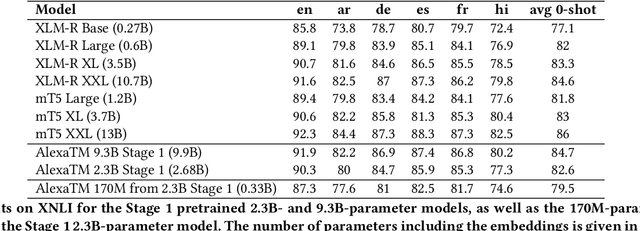
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
Deep Learning Hyperspectral Image Classification Using Multiple Class-based Denoising Autoencoders, Mixed Pixel Training Augmentation, and Morphological Operations
Jul 11, 2018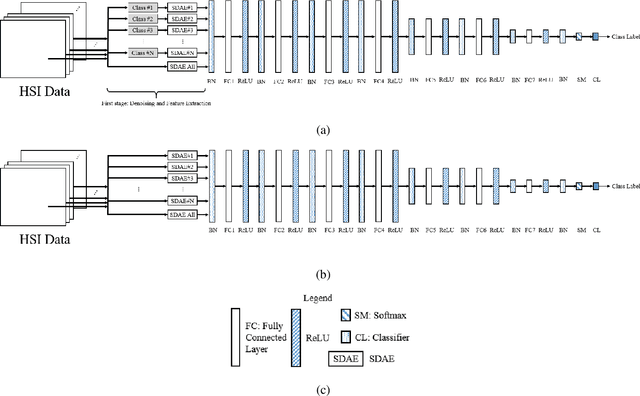
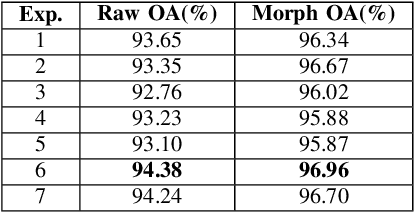

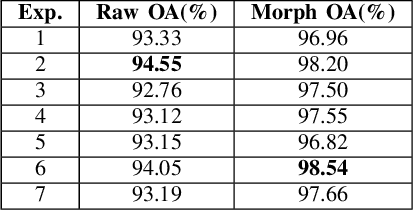
Herein, we present a system for hyperspectral image segmentation that utilizes multiple class--based denoising autoencoders which are efficiently trained. Moreover, we present a novel hyperspectral data augmentation method for labelled HSI data using linear mixtures of pixels from each class, which helps the system with edge pixels which are almost always mixed pixels. Finally, we utilize a deep neural network and morphological hole-filling to provide robust image classification. Results run on the Salinas dataset verify the high performance of the proposed algorithm.
State-of-the-art and gaps for deep learning on limited training data in remote sensing
Jul 11, 2018Deep learning usually requires big data, with respect to both volume and variety. However, most remote sensing applications only have limited training data, of which a small subset is labeled. Herein, we review three state-of-the-art approaches in deep learning to combat this challenge. The first topic is transfer learning, in which some aspects of one domain, e.g., features, are transferred to another domain. The next is unsupervised learning, e.g., autoencoders, which operate on unlabeled data. The last is generative adversarial networks, which can generate realistic looking data that can fool the likes of both a deep learning network and human. The aim of this article is to raise awareness of this dilemma, to direct the reader to existing work and to highlight current gaps that need solving.
* arXiv admin note: text overlap with arXiv:1709.00308
LiDAR and Camera Detection Fusion in a Real Time Industrial Multi-Sensor Collision Avoidance System
Jul 11, 2018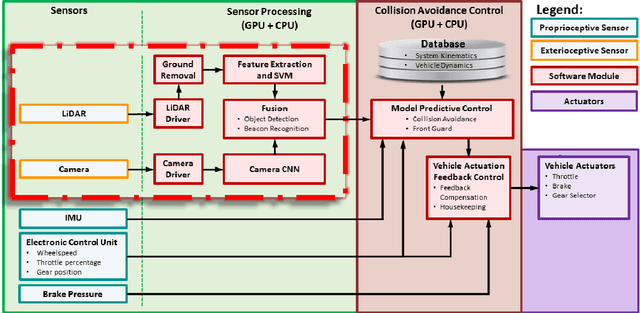

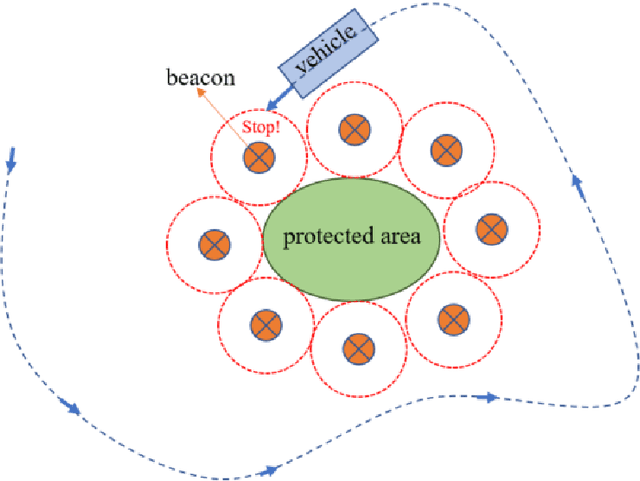
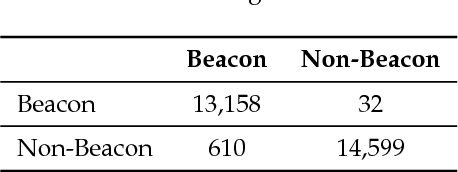
Collision avoidance is a critical task in many applications, such as ADAS (advanced driver-assistance systems), industrial automation and robotics. In an industrial automation setting, certain areas should be off limits to an automated vehicle for protection of people and high-valued assets. These areas can be quarantined by mapping (e.g., GPS) or via beacons that delineate a no-entry area. We propose a delineation method where the industrial vehicle utilizes a LiDAR {(Light Detection and Ranging)} and a single color camera to detect passive beacons and model-predictive control to stop the vehicle from entering a restricted space. The beacons are standard orange traffic cones with a highly reflective vertical pole attached. The LiDAR can readily detect these beacons, but suffers from false positives due to other reflective surfaces such as worker safety vests. Herein, we put forth a method for reducing false positive detection from the LiDAR by projecting the beacons in the camera imagery via a deep learning method and validating the detection using a neural network-learned projection from the camera to the LiDAR space. Experimental data collected at Mississippi State University's Center for Advanced Vehicular Systems (CAVS) shows the effectiveness of the proposed system in keeping the true detection while mitigating false positives.
* 34 pages
Fusion of an Ensemble of Augmented Image Detectors for Robust Object Detection
Mar 17, 2018



A significant challenge in object detection is accurate identification of an object's position in image space, whereas one algorithm with one set of parameters is usually not enough, and the fusion of multiple algorithms and/or parameters can lead to more robust results. Herein, a new computational intelligence fusion approach based on the dynamic analysis of agreement among object detection outputs is proposed. Furthermore, we propose an online versus just in training image augmentation strategy. Experiments comparing the results both with and without fusion are presented. We demonstrate that the augmented and fused combination results are the best, with respect to higher accuracy rates and reduction of outlier influences. The approach is demonstrated in the context of cone, pedestrian and box detection for Advanced Driver Assistance Systems (ADAS) applications.
Onion-Peeling Outlier Detection in 2-D data Sets
Mar 12, 2018
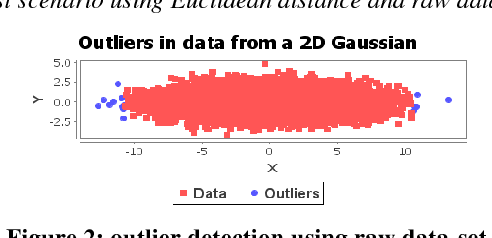
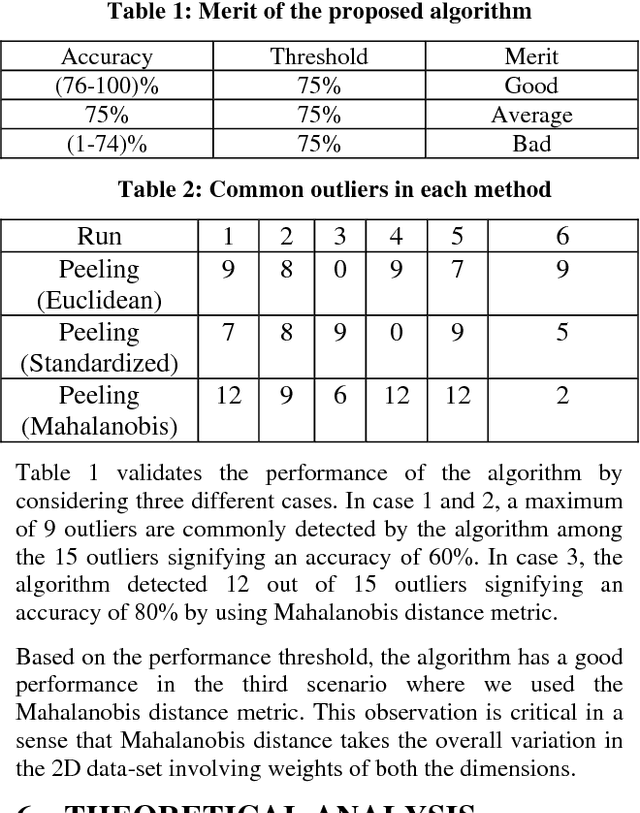
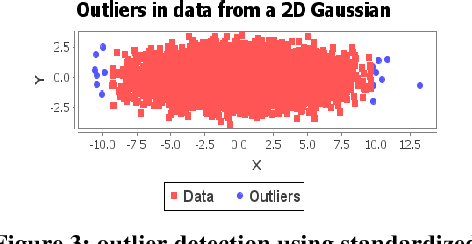
Outlier Detection is a critical and cardinal research task due its array of applications in variety of domains ranging from data mining, clustering, statistical analysis, fraud detection, network intrusion detection and diagnosis of diseases etc. Over the last few decades, distance-based outlier detection algorithms have gained significant reputation as a viable alternative to the more traditional statistical approaches due to their scalable, non-parametric and simple implementation. In this paper, we present a modified onion peeling (Convex hull) genetic algorithm to detect outliers in a Gaussian 2-D point data set. We present three different scenarios of outlier detection using a) Euclidean Distance Metric b) Standardized Euclidean Distance Metric and c) Mahalanobis Distance Metric. Finally, we analyze the performance and evaluate the results.
* 6 pages, 4 figures, journal paper
Measuring Conflict in a Multi-Source Environment as a Normal Measure
Mar 12, 2018
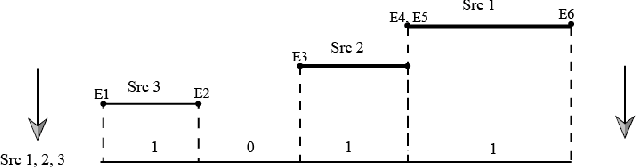

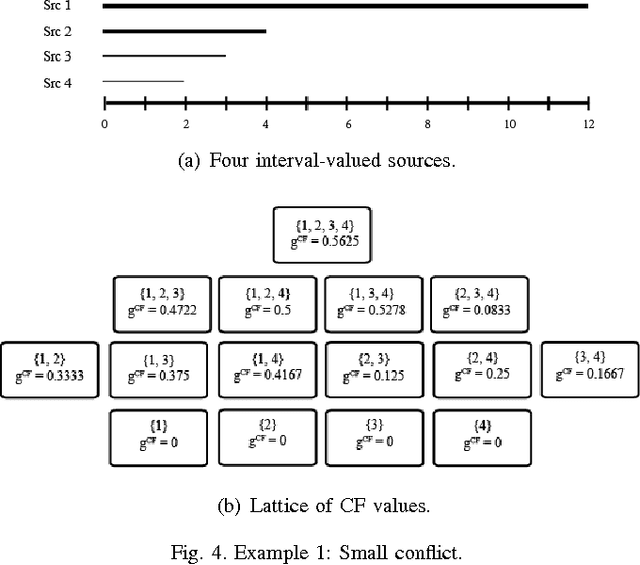
In a multi-source environment, each source has its own credibility. If there is no external knowledge about credibility then we can use the information provided by the sources to assess their credibility. In this paper, we propose a way to measure conflict in a multi-source environment as a normal measure. We examine our algorithm using three simulated examples of increasing conflict and one experimental example. The results demonstrate that the proposed measure can represent conflict in a meaningful way similar to what a human might expect and from it we can identify conflict within our sources.
* 4 pages, 8 figures, conference paper
Multi-Sensor Conflict Measurement and Information Fusion
Mar 12, 2018In sensing applications where multiple sensors observe the same scene, fusing sensor outputs can provide improved results. However, if some of the sensors are providing lower quality outputs, the fused results can be degraded. In this work, a multi-sensor conflict measure is proposed which estimates multi-sensor conflict by representing each sensor output as interval-valued information and examines the sensor output overlaps on all possible n-tuple sensor combinations. The conflict is based on the sizes of the intervals and how many sensors output values lie in these intervals. In this work, conflict is defined in terms of how little the output from multiple sensors overlap. That is, high degrees of overlap mean low sensor conflict, while low degrees of overlap mean high conflict. This work is a preliminary step towards a robust conflict and sensor fusion framework. In addition, a sensor fusion algorithm is proposed based on a weighted sum of sensor outputs, where the weights for each sensor diminish as the conflict measure increases. The proposed methods can be utilized to (1) assess a measure of multi-sensor conflict, and (2) improve sensor output fusion by lessening weighting for sensors with high conflict. Using this measure, a simulated example is given to explain the mechanics of calculating the conflict measure, and stereo camera 3D outputs are analyzed and fused. In the stereo camera case, the sensor output is corrupted by additive impulse noise, DC offset, and Gaussian noise. Impulse noise is common in sensors due to intermittent interference, a DC offset a sensor bias or registration error, and Gaussian noise represents a sensor output with low SNR. The results show that sensor output fusion based on the conflict measure shows improved accuracy over a simple averaging fusion strategy.
* 15 pages, 9 figures, conference paper