 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyLingua: Margin-based Inter-class Transformer for Robust Cross-domain Language Detection
Dec 10, 2025Language identification is a crucial first step in multilingual systems such as chatbots and virtual assistants, enabling linguistically and culturally accurate user experiences. Errors at this stage can cascade into downstream failures, setting a high bar for accuracy. Yet, existing language identification tools struggle with key cases -- such as music requests where the song title and user language differ. Open-source tools like LangDetect, FastText are fast but less accurate, while large language models, though effective, are often too costly for low-latency or low-resource settings. We introduce PolyLingua, a lightweight Transformer-based model for in-domain language detection and fine-grained language classification. It employs a two-level contrastive learning framework combining instance-level separation and class-level alignment with adaptive margins, yielding compact and well-separated embeddings even for closely related languages. Evaluated on two challenging datasets -- Amazon Massive (multilingual digital assistant utterances) and a Song dataset (music requests with frequent code-switching) -- PolyLingua achieves 99.25% F1 and 98.15% F1, respectively, surpassing Sonnet 3.5 while using 10x fewer parameters, making it ideal for compute- and latency-constrained environments.
Uni-Renderer: Unifying Rendering and Inverse Rendering Via Dual Stream Diffusion
Dec 19, 2024



Rendering and inverse rendering are pivotal tasks in both computer vision and graphics. The rendering equation is the core of the two tasks, as an ideal conditional distribution transfer function from intrinsic properties to RGB images. Despite achieving promising results of existing rendering methods, they merely approximate the ideal estimation for a specific scene and come with a high computational cost. Additionally, the inverse conditional distribution transfer is intractable due to the inherent ambiguity. To address these challenges, we propose a data-driven method that jointly models rendering and inverse rendering as two conditional generation tasks within a single diffusion framework. Inspired by UniDiffuser, we utilize two distinct time schedules to model both tasks, and with a tailored dual streaming module, we achieve cross-conditioning of two pre-trained diffusion models. This unified approach, named Uni-Renderer, allows the two processes to facilitate each other through a cycle-consistent constrain, mitigating ambiguity by enforcing consistency between intrinsic properties and rendered images. Combined with a meticulously prepared dataset, our method effectively decomposition of intrinsic properties and demonstrates a strong capability to recognize changes during rendering. We will open-source our training and inference code to the public, fostering further research and development in this area.
CALICO: Conversational Agent Localization via Synthetic Data Generation
Dec 06, 2024



We present CALICO, a method to fine-tune Large Language Models (LLMs) to localize conversational agent training data from one language to another. For slots (named entities), CALICO supports three operations: verbatim copy, literal translation, and localization, i.e. generating slot values more appropriate in the target language, such as city and airport names located in countries where the language is spoken. Furthermore, we design an iterative filtering mechanism to discard noisy generated samples, which we show boosts the performance of the downstream conversational agent. To prove the effectiveness of CALICO, we build and release a new human-localized (HL) version of the MultiATIS++ travel information test set in 8 languages. Compared to the original human-translated (HT) version of the test set, we show that our new HL version is more challenging. We also show that CALICO out-performs state-of-the-art LINGUIST (which relies on literal slot translation out of context) both on the HT case, where CALICO generates more accurate slot translations, and on the HL case, where CALICO generates localized slots which are closer to the HL test set.
Feature Noise Boosts DNN Generalization under Label Noise
Aug 03, 2023



The presence of label noise in the training data has a profound impact on the generalization of deep neural networks (DNNs). In this study, we introduce and theoretically demonstrate a simple feature noise method, which directly adds noise to the features of training data, can enhance the generalization of DNNs under label noise. Specifically, we conduct theoretical analyses to reveal that label noise leads to weakened DNN generalization by loosening the PAC-Bayes generalization bound, and feature noise results in better DNN generalization by imposing an upper bound on the mutual information between the model weights and the features, which constrains the PAC-Bayes generalization bound. Furthermore, to ensure effective generalization of DNNs in the presence of label noise, we conduct application analyses to identify the optimal types and levels of feature noise to add for obtaining desirable label noise generalization. Finally, extensive experimental results on several popular datasets demonstrate the feature noise method can significantly enhance the label noise generalization of the state-of-the-art label noise method.
Conversational Text-to-SQL: An Odyssey into State-of-the-Art and Challenges Ahead
Feb 21, 2023



Conversational, multi-turn, text-to-SQL (CoSQL) tasks map natural language utterances in a dialogue to SQL queries. State-of-the-art (SOTA) systems use large, pre-trained and finetuned language models, such as the T5-family, in conjunction with constrained decoding. With multi-tasking (MT) over coherent tasks with discrete prompts during training, we improve over specialized text-to-SQL T5-family models. Based on Oracle analyses over n-best hypotheses, we apply a query plan model and a schema linking algorithm as rerankers. Combining MT and reranking, our results using T5-3B show absolute accuracy improvements of 1.0% in exact match and 3.4% in execution match over a SOTA baseline on CoSQL. While these gains consistently manifest at turn level, context dependent turns are considerably harder. We conduct studies to tease apart errors attributable to domain and compositional generalization, with the latter remaining a challenge for multi-turn conversations, especially in generating SQL with unseen parse trees.
N-Best Hypotheses Reranking for Text-To-SQL Systems
Oct 19, 2022


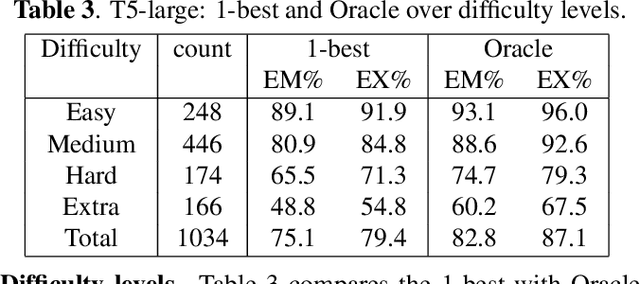
Text-to-SQL task maps natural language utterances to structured queries that can be issued to a database. State-of-the-art (SOTA) systems rely on finetuning large, pre-trained language models in conjunction with constrained decoding applying a SQL parser. On the well established Spider dataset, we begin with Oracle studies: specifically, choosing an Oracle hypothesis from a SOTA model's 10-best list, yields a $7.7\%$ absolute improvement in both exact match (EM) and execution (EX) accuracy, showing significant potential improvements with reranking. Identifying coherence and correctness as reranking approaches, we design a model generating a query plan and propose a heuristic schema linking algorithm. Combining both approaches, with T5-Large, we obtain a consistent $1\% $ improvement in EM accuracy, and a $~2.5\%$ improvement in EX, establishing a new SOTA for this task. Our comprehensive error studies on DEV data show the underlying difficulty in making progress on this task.
Sub 8-Bit Quantization of Streaming Keyword Spotting Models for Embedded Chipsets
Jul 13, 2022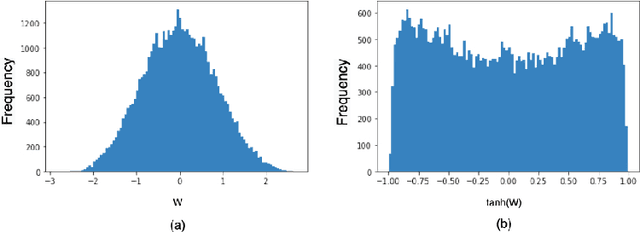
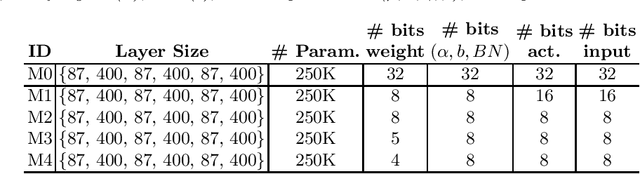
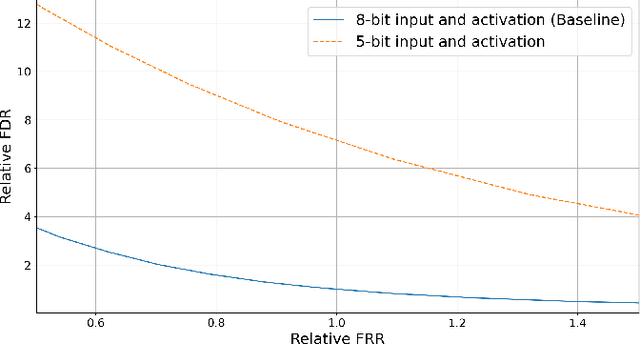
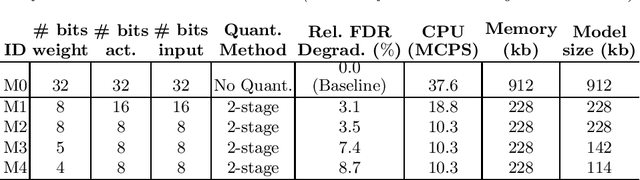
We propose a novel 2-stage sub 8-bit quantization aware training algorithm for all components of a 250K parameter feedforward, streaming, state-free keyword spotting model. For the 1st-stage, we adapt a recently proposed quantization technique using a non-linear transformation with tanh(.) on dense layer weights. In the 2nd-stage, we use linear quantization methods on the rest of the network, including other parameters (bias, gain, batchnorm), inputs, and activations. We conduct large scale experiments, training on 26,000 hours of de-identified production, far-field and near-field audio data (evaluating on 4,000 hours of data). We organize our results in two embedded chipset settings: a) with commodity ARM NEON instruction set and 8-bit containers, we present accuracy, CPU, and memory results using sub 8-bit weights (4, 5, 8-bit) and 8-bit quantization of rest of the network; b) with off-the-shelf neural network accelerators, for a range of weight bit widths (1 and 5-bit), while presenting accuracy results, we project reduction in memory utilization. In both configurations, our results show that the proposed algorithm can achieve: a) parity with a full floating point model's operating point on a detection error tradeoff (DET) curve in terms of false detection rate (FDR) at false rejection rate (FRR); b) significant reduction in compute and memory, yielding up to 3 times improvement in CPU consumption and more than 4 times improvement in memory consumption.
Wakeword Detection under Distribution Shifts
Jul 13, 2022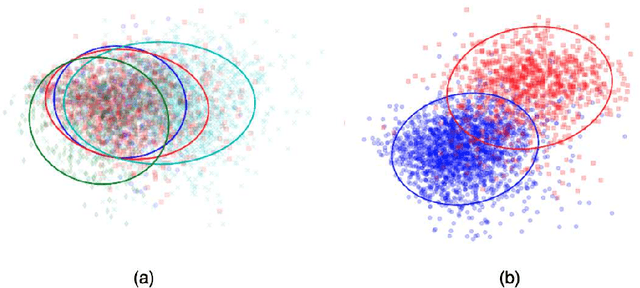
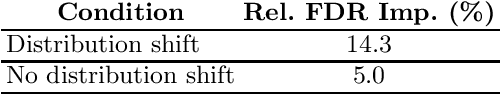
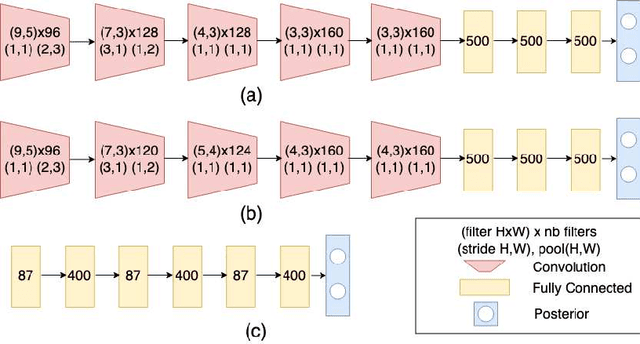
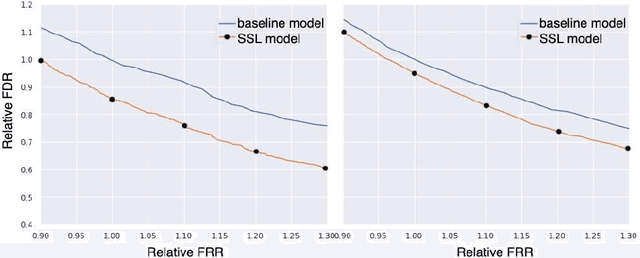
We propose a novel approach for semi-supervised learning (SSL) designed to overcome distribution shifts between training and real-world data arising in the keyword spotting (KWS) task. Shifts from training data distribution are a key challenge for real-world KWS tasks: when a new model is deployed on device, the gating of the accepted data undergoes a shift in distribution, making the problem of timely updates via subsequent deployments hard. Despite the shift, we assume that the marginal distributions on labels do not change. We utilize a modified teacher/student training framework, where labeled training data is augmented with unlabeled data. Note that the teacher does not have access to the new distribution as well. To train effectively with a mix of human and teacher labeled data, we develop a teacher labeling strategy based on confidence heuristics to reduce entropy on the label distribution from the teacher model; the data is then sampled to match the marginal distribution on the labels. Large scale experimental results show that a convolutional neural network (CNN) trained on far-field audio, and evaluated on far-field audio drawn from a different distribution, obtains a 14.3% relative improvement in false discovery rate (FDR) at equal false reject rate (FRR), while yielding a 5% improvement in FDR under no distribution shift. Under a more severe distribution shift from far-field to near-field audio with a smaller fully connected network (FCN) our approach achieves a 52% relative improvement in FDR at equal FRR, while yielding a 20% relative improvement in FDR on the original distribution.