 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub 8-Bit Quantization of Streaming Keyword Spotting Models for Embedded Chipsets
Jul 13, 2022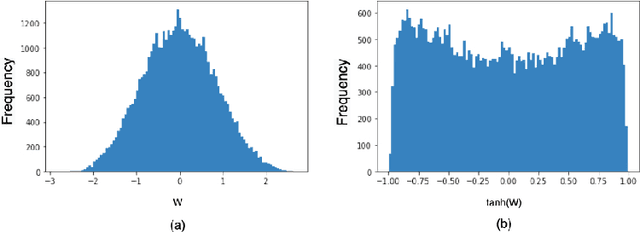
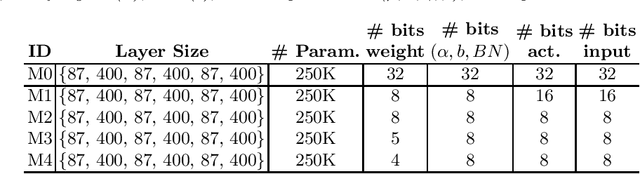
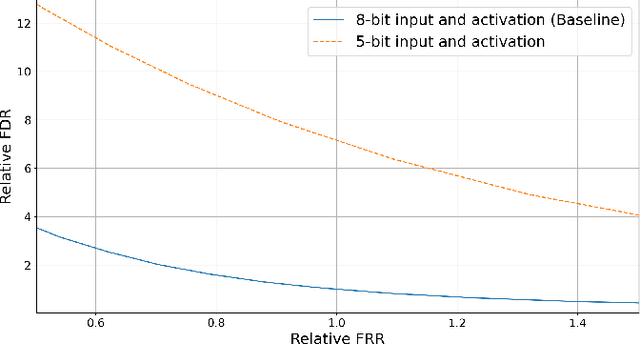
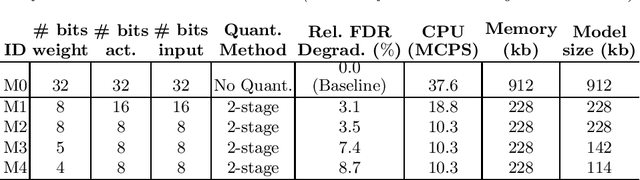
We propose a novel 2-stage sub 8-bit quantization aware training algorithm for all components of a 250K parameter feedforward, streaming, state-free keyword spotting model. For the 1st-stage, we adapt a recently proposed quantization technique using a non-linear transformation with tanh(.) on dense layer weights. In the 2nd-stage, we use linear quantization methods on the rest of the network, including other parameters (bias, gain, batchnorm), inputs, and activations. We conduct large scale experiments, training on 26,000 hours of de-identified production, far-field and near-field audio data (evaluating on 4,000 hours of data). We organize our results in two embedded chipset settings: a) with commodity ARM NEON instruction set and 8-bit containers, we present accuracy, CPU, and memory results using sub 8-bit weights (4, 5, 8-bit) and 8-bit quantization of rest of the network; b) with off-the-shelf neural network accelerators, for a range of weight bit widths (1 and 5-bit), while presenting accuracy results, we project reduction in memory utilization. In both configurations, our results show that the proposed algorithm can achieve: a) parity with a full floating point model's operating point on a detection error tradeoff (DET) curve in terms of false detection rate (FDR) at false rejection rate (FRR); b) significant reduction in compute and memory, yielding up to 3 times improvement in CPU consumption and more than 4 times improvement in memory consumption.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
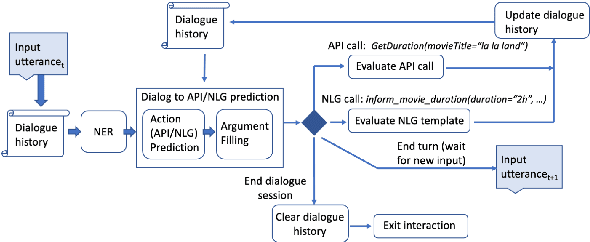

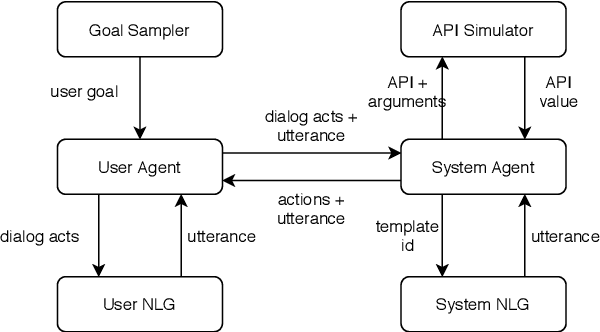
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
Realizing Petabyte Scale Acoustic Modeling
Apr 24, 2019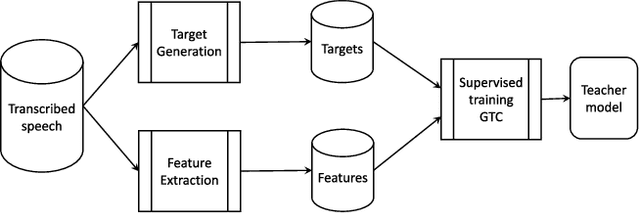
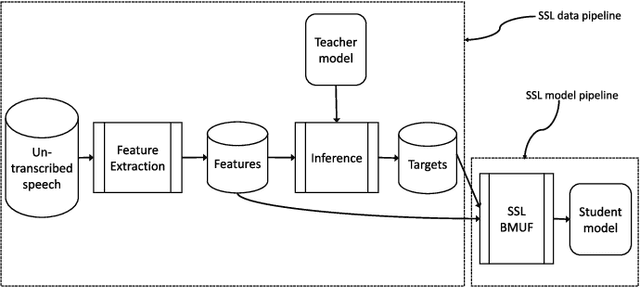
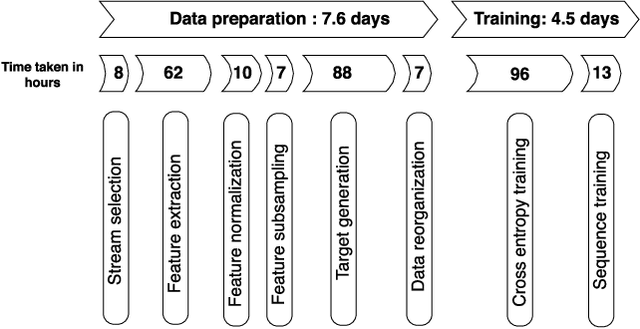
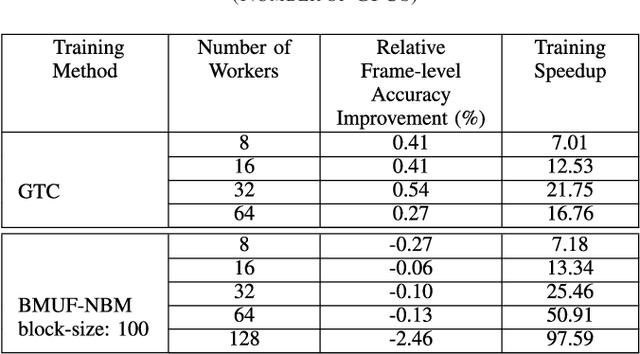
Large scale machine learning (ML) systems such as the Alexa automatic speech recognition (ASR) system continue to improve with increasing amounts of manually transcribed training data. Instead of scaling manual transcription to impractical levels, we utilize semi-supervised learning (SSL) to learn acoustic models (AM) from the vast firehose of untranscribed audio data. Learning an AM from 1 Million hours of audio presents unique ML and system design challenges. We present the design and evaluation of a highly scalable and resource efficient SSL system for AM. Employing the student/teacher learning paradigm, we focus on the student learning subsystem: a scalable and robust data pipeline that generates features and targets from raw audio, and an efficient model pipeline, including the distributed trainer, that builds a student model. Our evaluations show that, even without extensive hyper-parameter tuning, we obtain relative accuracy improvements in the 10 to 20$\%$ range, with higher gains in noisier conditions. The end-to-end processing time of this SSL system was 12 days, and several components in this system can trivially scale linearly with more compute resources.
Lessons from Building Acoustic Models with a Million Hours of Speech
Apr 02, 2019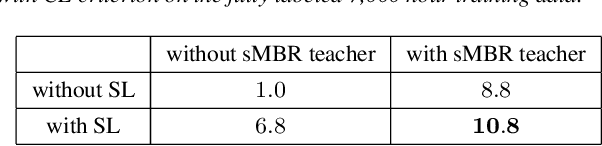
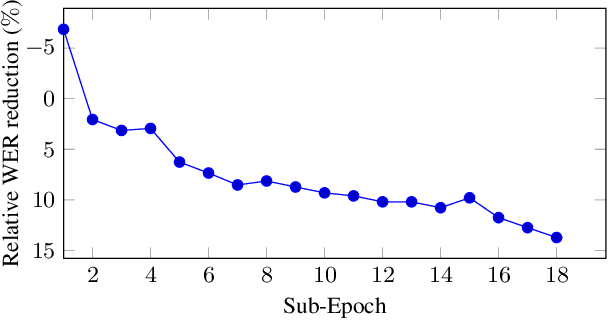
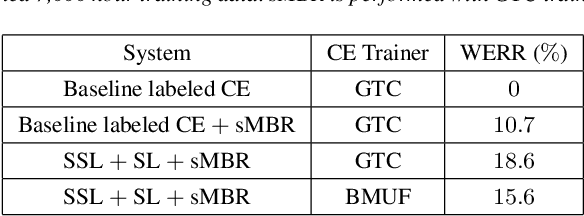
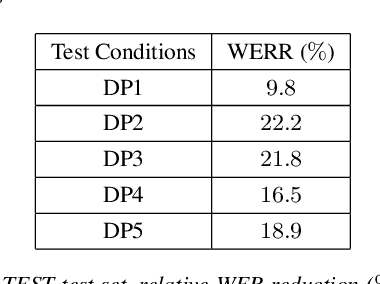
This is a report of our lessons learned building acoustic models from 1 Million hours of unlabeled speech, while labeled speech is restricted to 7,000 hours. We employ student/teacher training on unlabeled data, helping scale out target generation in comparison to confidence model based methods, which require a decoder and a confidence model. To optimize storage and to parallelize target generation, we store high valued logits from the teacher model. Introducing the notion of scheduled learning, we interleave learning on unlabeled and labeled data. To scale distributed training across a large number of GPUs, we use BMUF with 64 GPUs, while performing sequence training only on labeled data with gradient threshold compression SGD using 16 GPUs. Our experiments show that extremely large amounts of data are indeed useful; with little hyper-parameter tuning, we obtain relative WER improvements in the 10 to 20% range, with higher gains in noisier conditions.
Data Augmentation for Robust Keyword Spotting under Playback Interference
Aug 01, 2018
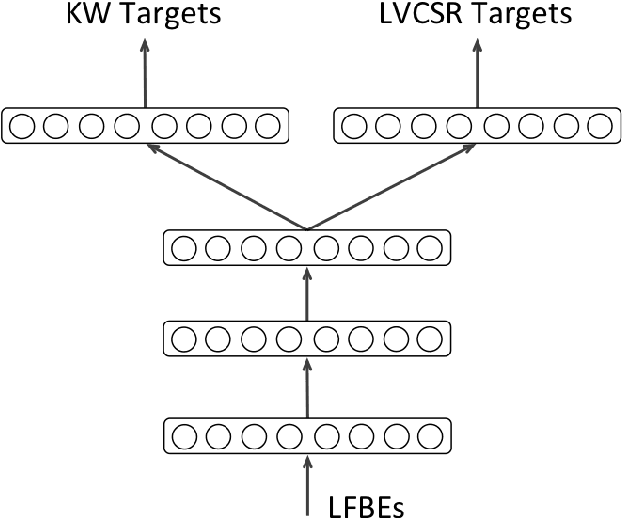
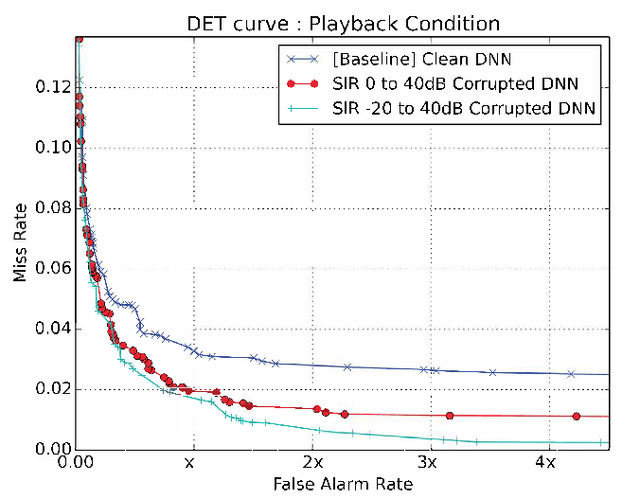
Accurate on-device keyword spotting (KWS) with low false accept and false reject rate is crucial to customer experience for far-field voice control of conversational agents. It is particularly challenging to maintain low false reject rate in real world conditions where there is (a) ambient noise from external sources such as TV, household appliances, or other speech that is not directed at the device (b) imperfect cancellation of the audio playback from the device, resulting in residual echo, after being processed by the Acoustic Echo Cancellation (AEC) system. In this paper, we propose a data augmentation strategy to improve keyword spotting performance under these challenging conditions. The training set audio is artificially corrupted by mixing in music and TV/movie audio, at different signal to interference ratios. Our results show that we get around 30-45% relative reduction in false reject rates, at a range of false alarm rates, under audio playback from such devices.
Max-Pooling Loss Training of Long Short-Term Memory Networks for Small-Footprint Keyword Spotting
May 05, 2017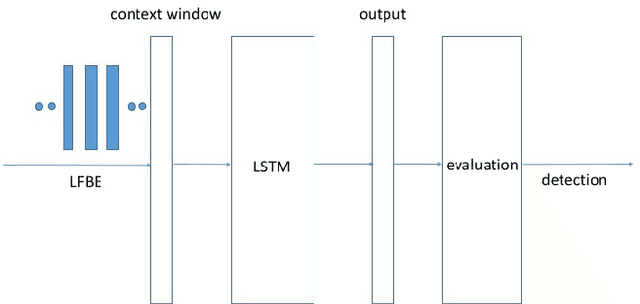

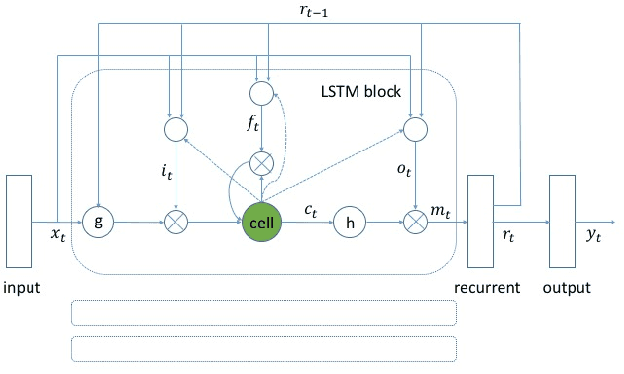
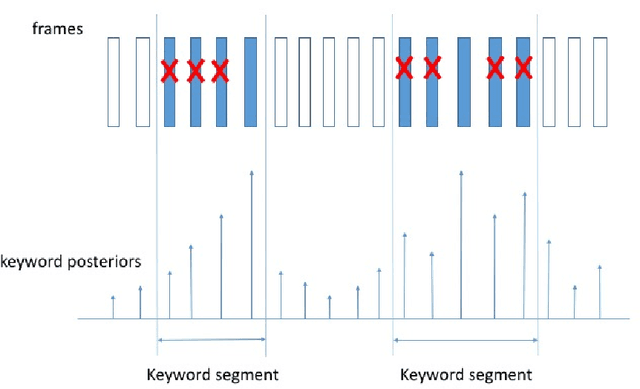
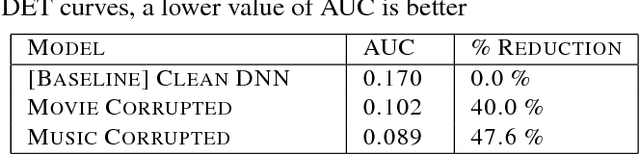
We propose a max-pooling based loss function for training Long Short-Term Memory (LSTM) networks for small-footprint keyword spotting (KWS), with low CPU, memory, and latency requirements. The max-pooling loss training can be further guided by initializing with a cross-entropy loss trained network. A posterior smoothing based evaluation approach is employed to measure keyword spotting performance. Our experimental results show that LSTM models trained using cross-entropy loss or max-pooling loss outperform a cross-entropy loss trained baseline feed-forward Deep Neural Network (DNN). In addition, max-pooling loss trained LSTM with randomly initialized network performs better compared to cross-entropy loss trained LSTM. Finally, the max-pooling loss trained LSTM initialized with a cross-entropy pre-trained network shows the best performance, which yields $67.6\%$ relative reduction compared to baseline feed-forward DNN in Area Under the Curve (AUC) measure.