 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub 8-Bit Quantization of Streaming Keyword Spotting Models for Embedded Chipsets
Jul 13, 2022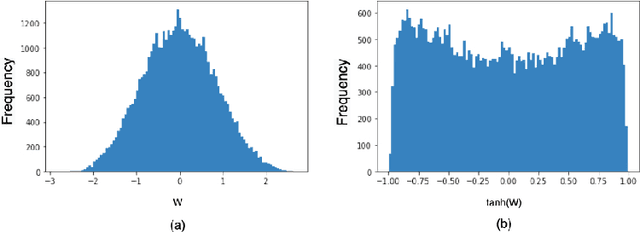
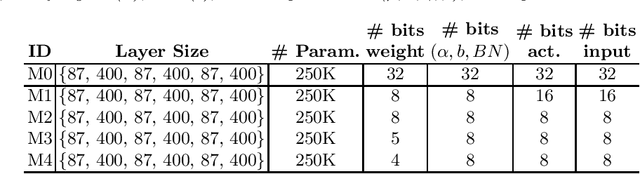
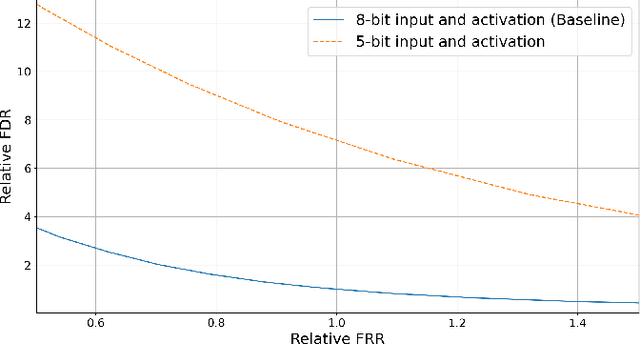
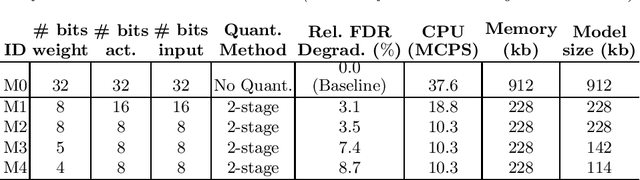
We propose a novel 2-stage sub 8-bit quantization aware training algorithm for all components of a 250K parameter feedforward, streaming, state-free keyword spotting model. For the 1st-stage, we adapt a recently proposed quantization technique using a non-linear transformation with tanh(.) on dense layer weights. In the 2nd-stage, we use linear quantization methods on the rest of the network, including other parameters (bias, gain, batchnorm), inputs, and activations. We conduct large scale experiments, training on 26,000 hours of de-identified production, far-field and near-field audio data (evaluating on 4,000 hours of data). We organize our results in two embedded chipset settings: a) with commodity ARM NEON instruction set and 8-bit containers, we present accuracy, CPU, and memory results using sub 8-bit weights (4, 5, 8-bit) and 8-bit quantization of rest of the network; b) with off-the-shelf neural network accelerators, for a range of weight bit widths (1 and 5-bit), while presenting accuracy results, we project reduction in memory utilization. In both configurations, our results show that the proposed algorithm can achieve: a) parity with a full floating point model's operating point on a detection error tradeoff (DET) curve in terms of false detection rate (FDR) at false rejection rate (FRR); b) significant reduction in compute and memory, yielding up to 3 times improvement in CPU consumption and more than 4 times improvement in memory consumption.
On Front-end Gain Invariant Modeling for Wake Word Spotting
Oct 13, 2020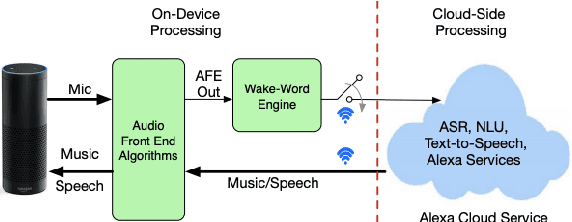
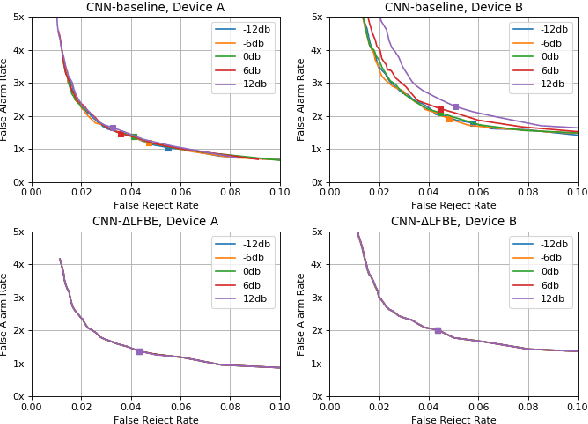
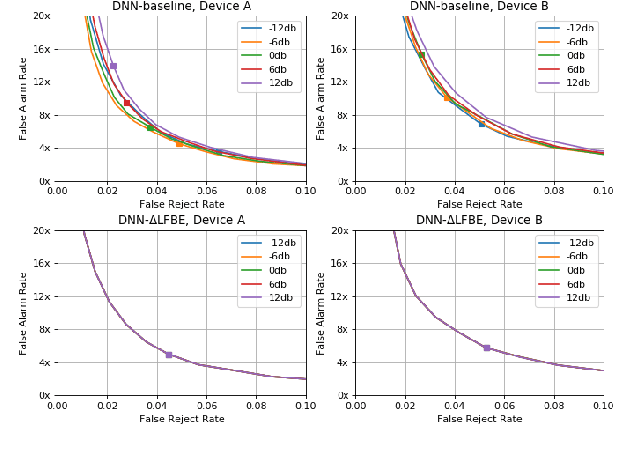
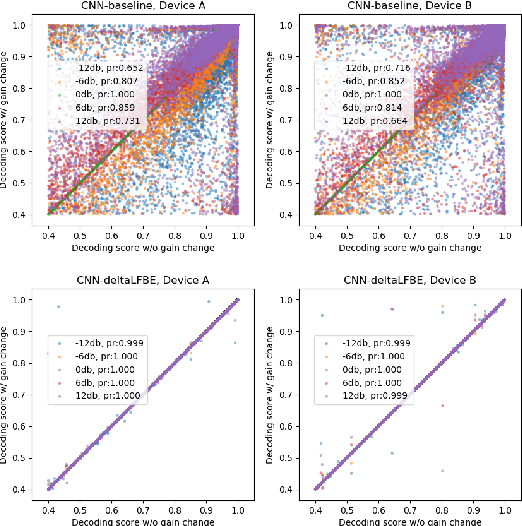
Wake word (WW) spotting is challenging in far-field due to the complexities and variations in acoustic conditions and the environmental interference in signal transmission. A suite of carefully designed and optimized audio front-end (AFE) algorithms help mitigate these challenges and provide better quality audio signals to the downstream modules such as WW spotter. Since the WW model is trained with the AFE-processed audio data, its performance is sensitive to AFE variations, such as gain changes. In addition, when deploying to new devices, the WW performance is not guaranteed because the AFE is unknown to the WW model. To address these issues, we propose a novel approach to use a new feature called $\Delta$LFBE to decouple the AFE gain variations from the WW model. We modified the neural network architectures to accommodate the delta computation, with the feature extraction module unchanged. We evaluate our WW models using data collected from real household settings and showed the models with the $\Delta$LFBE is robust to AFE gain changes. Specifically, when AFE gain changes up to $\pm$12dB, the baseline CNN model lost up to relative 19.0% in false alarm rate or 34.3% in false reject rate, while the model with $\Delta$LFBE demonstrates no performance loss.
Towards Data-efficient Modeling for Wake Word Spotting
Oct 13, 2020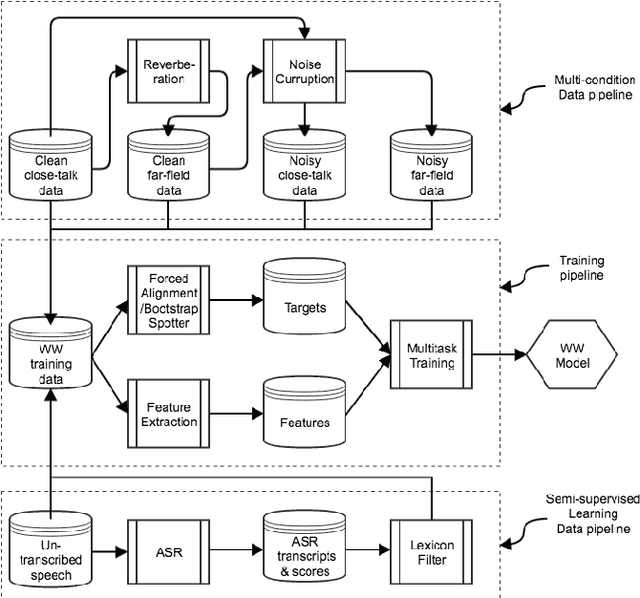
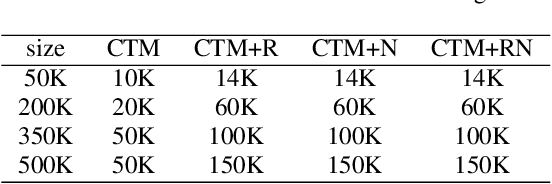
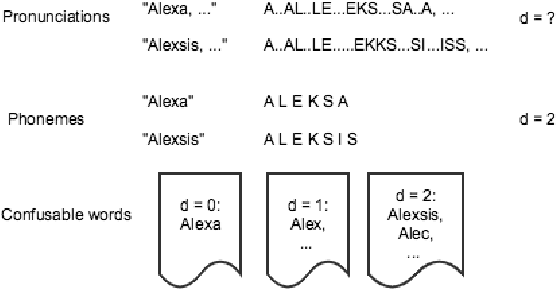

Wake word (WW) spotting is challenging in far-field not only because of the interference in signal transmission but also the complexity in acoustic environments. Traditional WW model training requires large amount of in-domain WW-specific data with substantial human annotations therefore it is hard to build WW models without such data. In this paper we present data-efficient solutions to address the challenges in WW modeling, such as domain-mismatch, noisy conditions, limited annotation, etc. Our proposed system is composed of a multi-condition training pipeline with a stratified data augmentation, which improves the model robustness to a variety of predefined acoustic conditions, together with a semi-supervised learning pipeline to accurately extract the WW and confusable examples from untranscribed speech corpus. Starting from only 10 hours of domain-mismatched WW audio, we are able to enlarge and enrich the training dataset by 20-100 times to capture the acoustic complexity. Our experiments on real user data show that the proposed solutions can achieve comparable performance of a production-grade model by saving 97\% of the amount of WW-specific data collection and 86\% of the bandwidth for annotation.
Accurate Detection of Wake Word Start and End Using a CNN
Aug 09, 2020

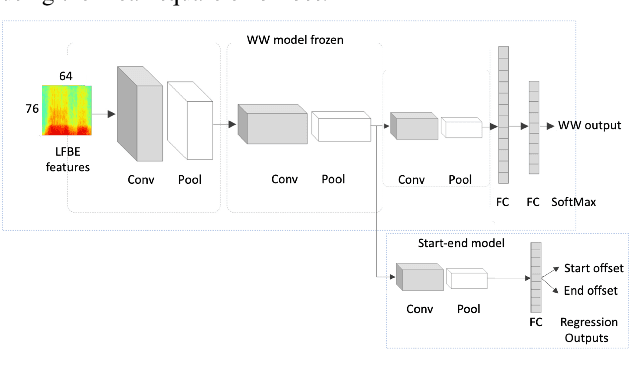

Small footprint embedded devices require keyword spotters (KWS) with small model size and detection latency for enabling voice assistants. Such a keyword is often referred to as \textit{wake word} as it is used to wake up voice assistant enabled devices. Together with wake word detection, accurate estimation of wake word endpoints (start and end) is an important task of KWS. In this paper, we propose two new methods for detecting the endpoints of wake words in neural KWS that use single-stage word-level neural networks. Our results show that the new techniques give superior accuracy for detecting wake words' endpoints of up to 50 msec standard error versus human annotations, on par with the conventional Acoustic Model plus HMM forced alignment. To our knowledge, this is the first study of wake word endpoints detection methods for single-stage neural KWS.
Max-Pooling Loss Training of Long Short-Term Memory Networks for Small-Footprint Keyword Spotting
May 05, 2017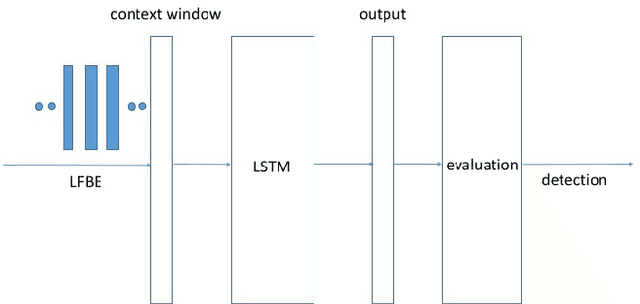

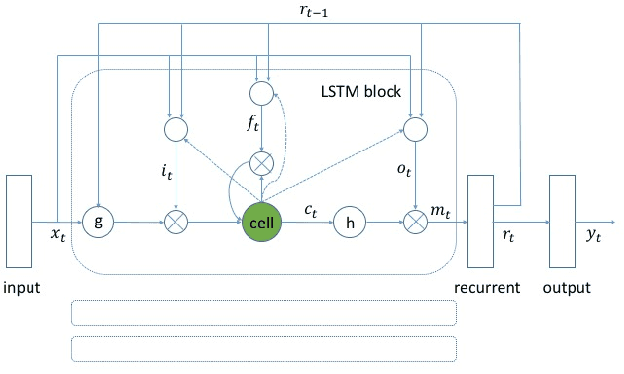
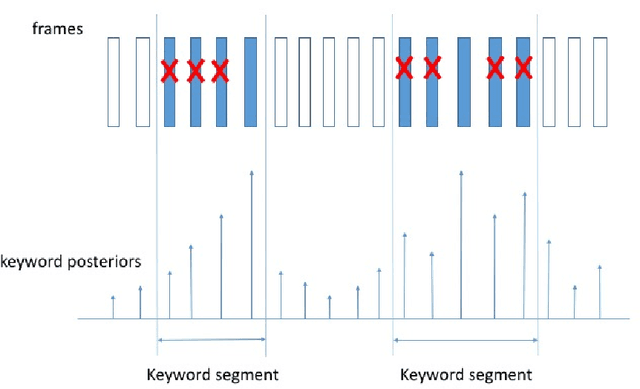
We propose a max-pooling based loss function for training Long Short-Term Memory (LSTM) networks for small-footprint keyword spotting (KWS), with low CPU, memory, and latency requirements. The max-pooling loss training can be further guided by initializing with a cross-entropy loss trained network. A posterior smoothing based evaluation approach is employed to measure keyword spotting performance. Our experimental results show that LSTM models trained using cross-entropy loss or max-pooling loss outperform a cross-entropy loss trained baseline feed-forward Deep Neural Network (DNN). In addition, max-pooling loss trained LSTM with randomly initialized network performs better compared to cross-entropy loss trained LSTM. Finally, the max-pooling loss trained LSTM initialized with a cross-entropy pre-trained network shows the best performance, which yields $67.6\%$ relative reduction compared to baseline feed-forward DNN in Area Under the Curve (AUC) measure.
Super-resolution using Sparse Representations over Learned Dictionaries: Reconstruction of Brain Structure using Electron Microscopy
Oct 01, 2012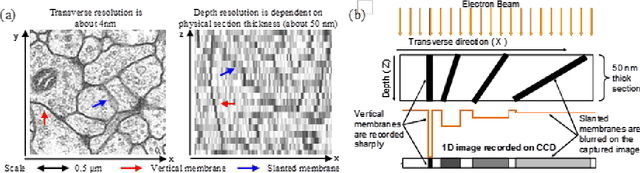
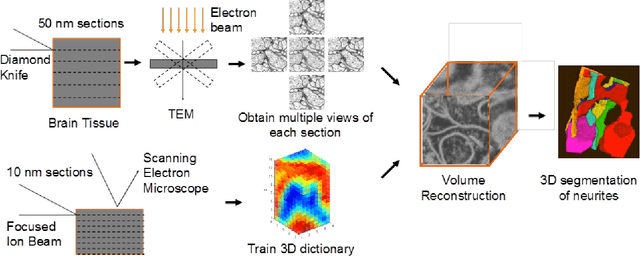

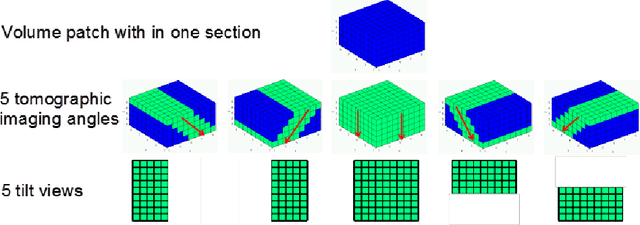
A central problem in neuroscience is reconstructing neuronal circuits on the synapse level. Due to a wide range of scales in brain architecture such reconstruction requires imaging that is both high-resolution and high-throughput. Existing electron microscopy (EM) techniques possess required resolution in the lateral plane and either high-throughput or high depth resolution but not both. Here, we exploit recent advances in unsupervised learning and signal processing to obtain high depth-resolution EM images computationally without sacrificing throughput. First, we show that the brain tissue can be represented as a sparse linear combination of localized basis functions that are learned using high-resolution datasets. We then develop compressive sensing-inspired techniques that can reconstruct the brain tissue from very few (typically 5) tomographic views of each section. This enables tracing of neuronal processes and, hence, high throughput reconstruction of neural circuits on the level of individual synapses.