 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatency Control for Keyword Spotting
Jun 15, 2022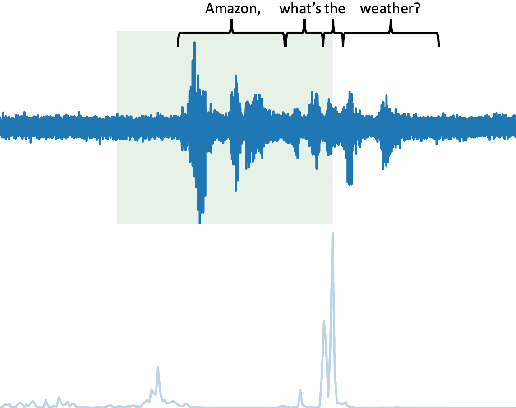

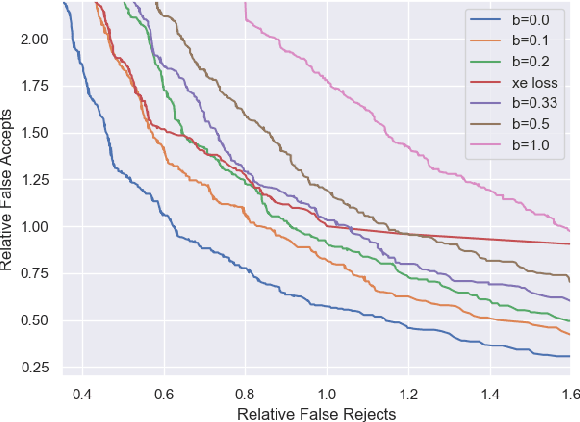
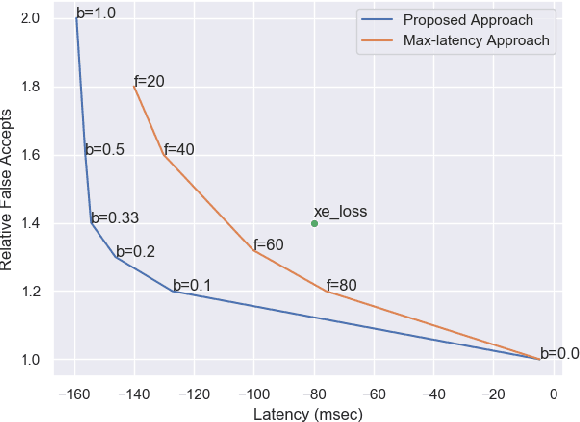
Conversational agents commonly utilize keyword spotting (KWS) to initiate voice interaction with the user. For user experience and privacy considerations, existing approaches to KWS largely focus on accuracy, which can often come at the expense of introduced latency. To address this tradeoff, we propose a novel approach to control KWS model latency and which generalizes to any loss function without explicit knowledge of the keyword endpoint. Through a single, tunable hyperparameter, our approach enables one to balance detection latency and accuracy for the targeted application. Empirically, we show that our approach gives superior performance under latency constraints when compared to existing methods. Namely, we make a substantial 25\% relative false accepts improvement for a fixed latency target when compared to the baseline state-of-the-art. We also show that when our approach is used in conjunction with a max-pooling loss, we are able to improve relative false accepts by 25 % at a fixed latency when compared to cross entropy loss.
Towards Data-efficient Modeling for Wake Word Spotting
Oct 13, 2020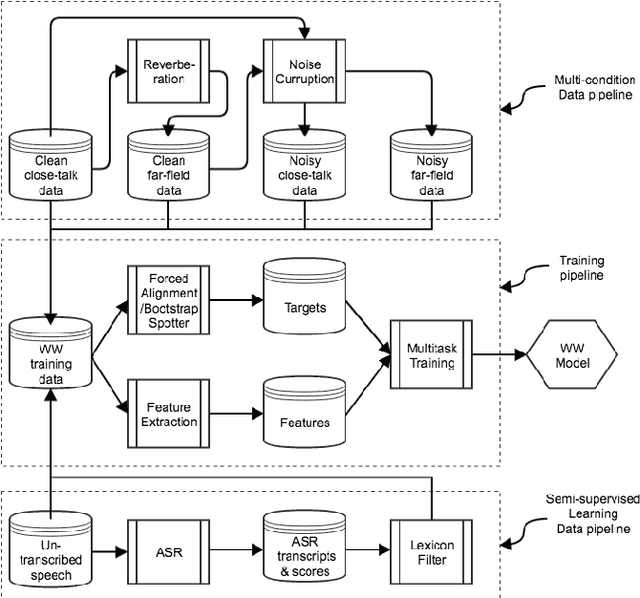
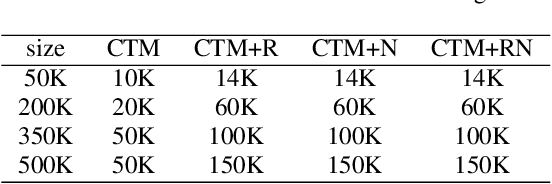
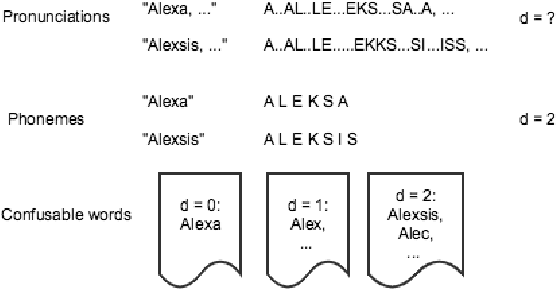

Wake word (WW) spotting is challenging in far-field not only because of the interference in signal transmission but also the complexity in acoustic environments. Traditional WW model training requires large amount of in-domain WW-specific data with substantial human annotations therefore it is hard to build WW models without such data. In this paper we present data-efficient solutions to address the challenges in WW modeling, such as domain-mismatch, noisy conditions, limited annotation, etc. Our proposed system is composed of a multi-condition training pipeline with a stratified data augmentation, which improves the model robustness to a variety of predefined acoustic conditions, together with a semi-supervised learning pipeline to accurately extract the WW and confusable examples from untranscribed speech corpus. Starting from only 10 hours of domain-mismatched WW audio, we are able to enlarge and enrich the training dataset by 20-100 times to capture the acoustic complexity. Our experiments on real user data show that the proposed solutions can achieve comparable performance of a production-grade model by saving 97\% of the amount of WW-specific data collection and 86\% of the bandwidth for annotation.
Accurate Detection of Wake Word Start and End Using a CNN
Aug 09, 2020

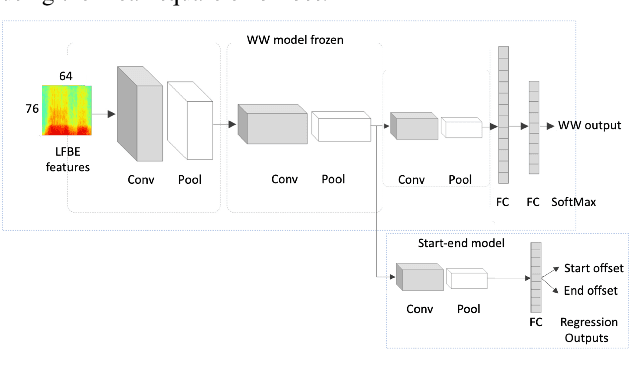

Small footprint embedded devices require keyword spotters (KWS) with small model size and detection latency for enabling voice assistants. Such a keyword is often referred to as \textit{wake word} as it is used to wake up voice assistant enabled devices. Together with wake word detection, accurate estimation of wake word endpoints (start and end) is an important task of KWS. In this paper, we propose two new methods for detecting the endpoints of wake words in neural KWS that use single-stage word-level neural networks. Our results show that the new techniques give superior accuracy for detecting wake words' endpoints of up to 50 msec standard error versus human annotations, on par with the conventional Acoustic Model plus HMM forced alignment. To our knowledge, this is the first study of wake word endpoints detection methods for single-stage neural KWS.