 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWakeword Detection under Distribution Shifts
Jul 13, 2022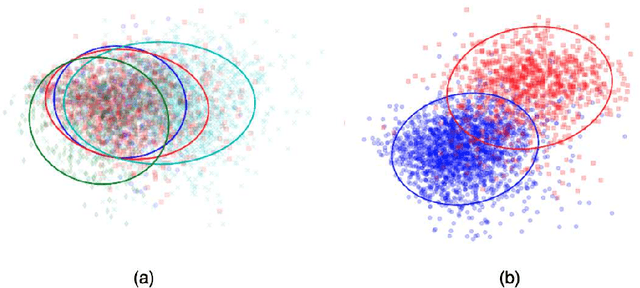
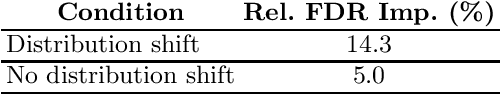
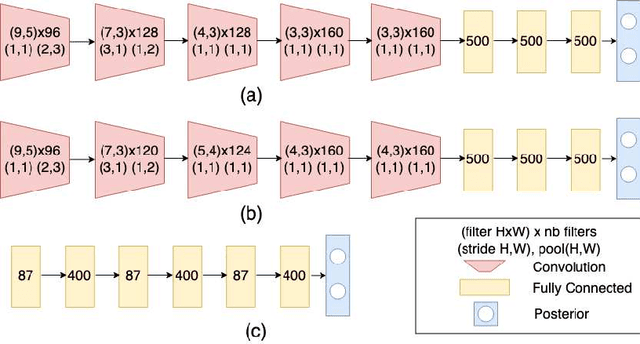
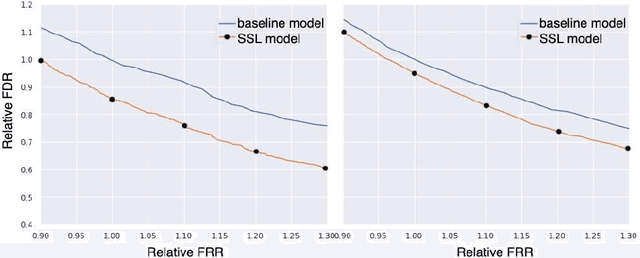
We propose a novel approach for semi-supervised learning (SSL) designed to overcome distribution shifts between training and real-world data arising in the keyword spotting (KWS) task. Shifts from training data distribution are a key challenge for real-world KWS tasks: when a new model is deployed on device, the gating of the accepted data undergoes a shift in distribution, making the problem of timely updates via subsequent deployments hard. Despite the shift, we assume that the marginal distributions on labels do not change. We utilize a modified teacher/student training framework, where labeled training data is augmented with unlabeled data. Note that the teacher does not have access to the new distribution as well. To train effectively with a mix of human and teacher labeled data, we develop a teacher labeling strategy based on confidence heuristics to reduce entropy on the label distribution from the teacher model; the data is then sampled to match the marginal distribution on the labels. Large scale experimental results show that a convolutional neural network (CNN) trained on far-field audio, and evaluated on far-field audio drawn from a different distribution, obtains a 14.3% relative improvement in false discovery rate (FDR) at equal false reject rate (FRR), while yielding a 5% improvement in FDR under no distribution shift. Under a more severe distribution shift from far-field to near-field audio with a smaller fully connected network (FCN) our approach achieves a 52% relative improvement in FDR at equal FRR, while yielding a 20% relative improvement in FDR on the original distribution.
Latency Control for Keyword Spotting
Jun 15, 2022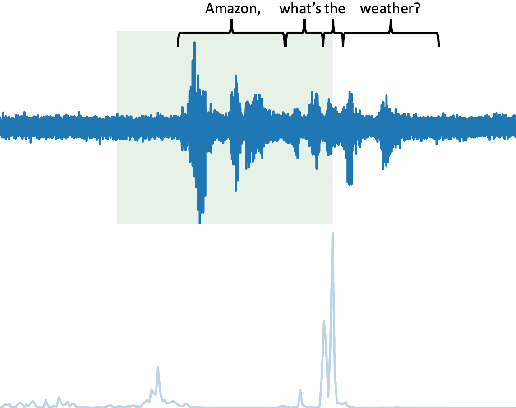

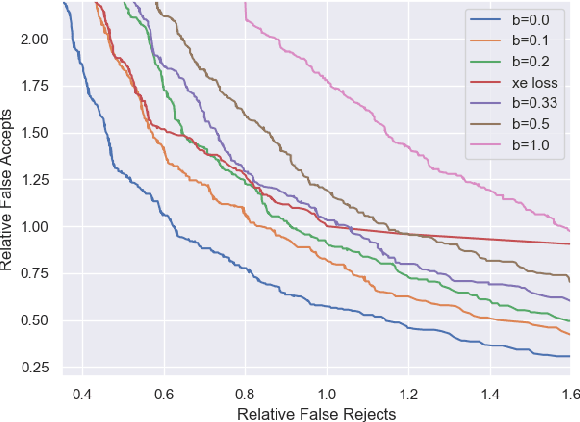
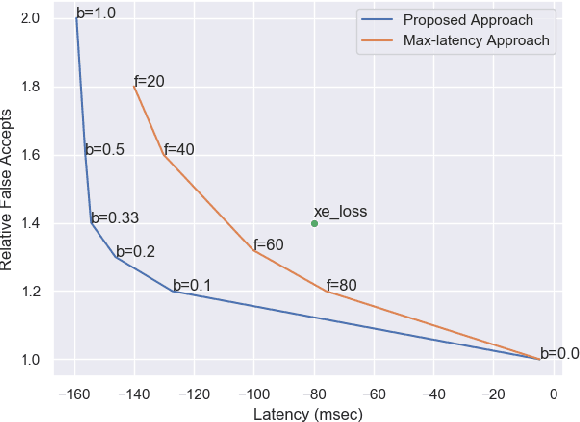
Conversational agents commonly utilize keyword spotting (KWS) to initiate voice interaction with the user. For user experience and privacy considerations, existing approaches to KWS largely focus on accuracy, which can often come at the expense of introduced latency. To address this tradeoff, we propose a novel approach to control KWS model latency and which generalizes to any loss function without explicit knowledge of the keyword endpoint. Through a single, tunable hyperparameter, our approach enables one to balance detection latency and accuracy for the targeted application. Empirically, we show that our approach gives superior performance under latency constraints when compared to existing methods. Namely, we make a substantial 25\% relative false accepts improvement for a fixed latency target when compared to the baseline state-of-the-art. We also show that when our approach is used in conjunction with a max-pooling loss, we are able to improve relative false accepts by 25 % at a fixed latency when compared to cross entropy loss.
Tiny-CRNN: Streaming Wakeword Detection In A Low Footprint Setting
Sep 29, 2021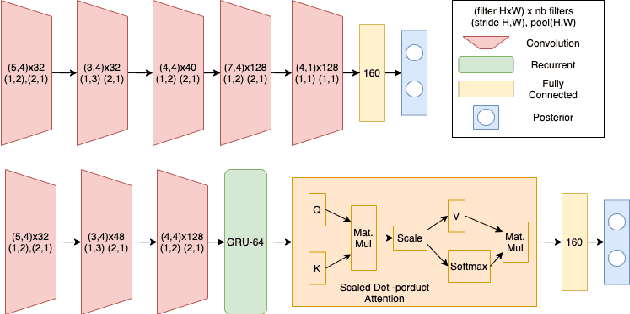
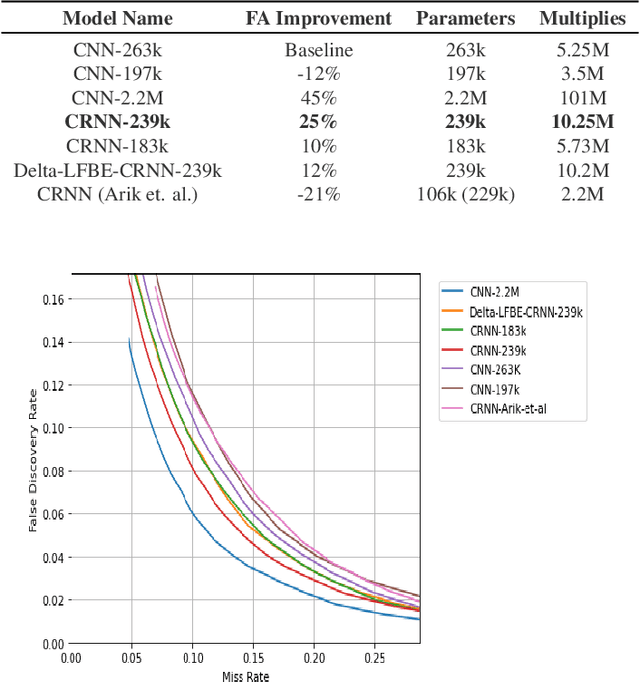
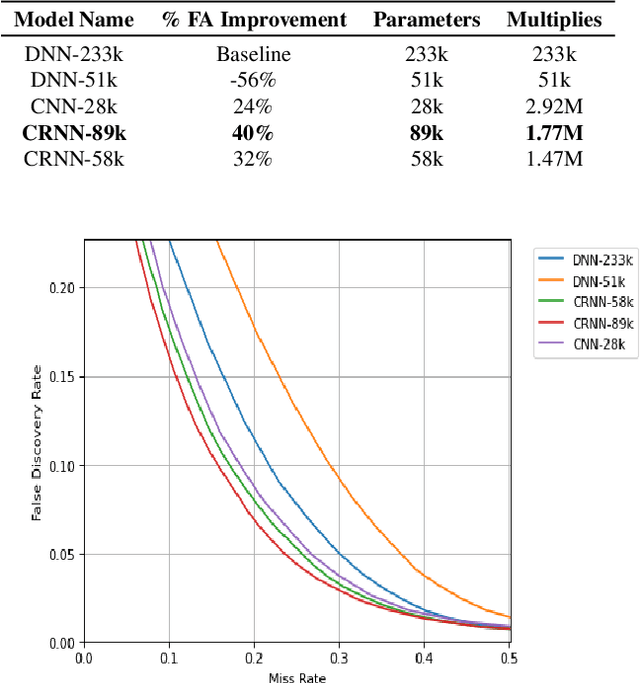
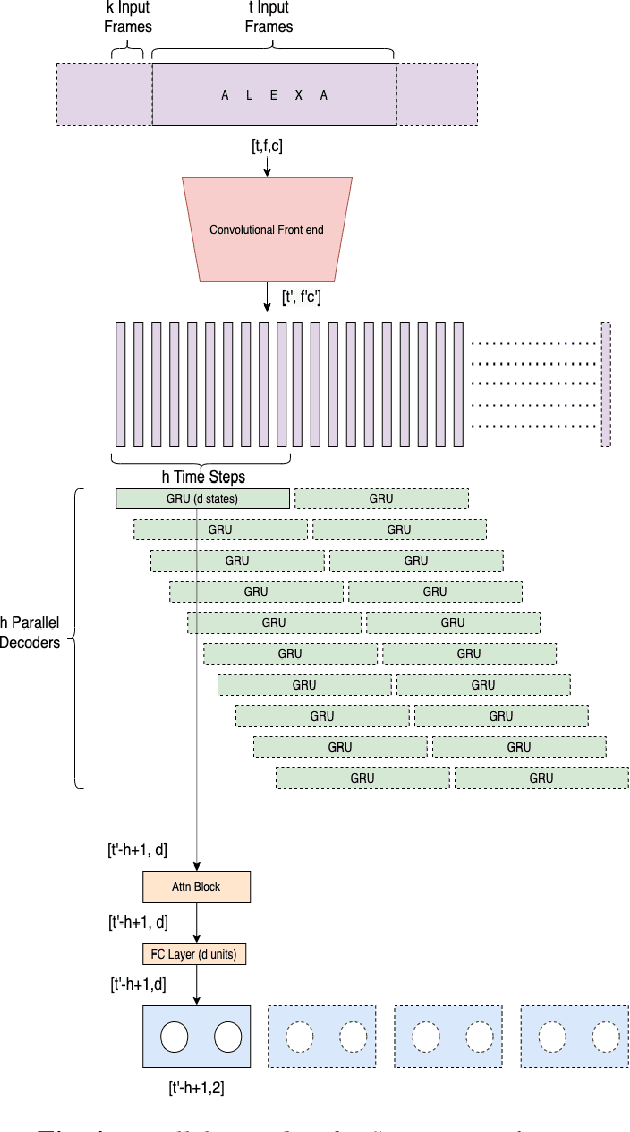
In this work, we propose Tiny-CRNN (Tiny Convolutional Recurrent Neural Network) models applied to the problem of wakeword detection, and augment them with scaled dot product attention. We find that, compared to Convolutional Neural Network models, False Accepts in a 250k parameter budget can be reduced by 25% with a 10% reduction in parameter size by using models based on the Tiny-CRNN architecture, and we can get up to 32% reduction in False Accepts at a 50k parameter budget with 75% reduction in parameter size compared to word-level Dense Neural Network models. We discuss solutions to the challenging problem of performing inference on streaming audio with this architecture, as well as differences in start-end index errors and latency in comparison to CNN, DNN, and DNN-HMM models.
Accurate Detection of Wake Word Start and End Using a CNN
Aug 09, 2020

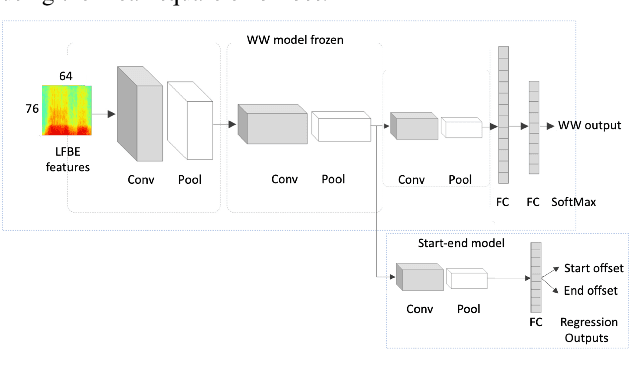

Small footprint embedded devices require keyword spotters (KWS) with small model size and detection latency for enabling voice assistants. Such a keyword is often referred to as \textit{wake word} as it is used to wake up voice assistant enabled devices. Together with wake word detection, accurate estimation of wake word endpoints (start and end) is an important task of KWS. In this paper, we propose two new methods for detecting the endpoints of wake words in neural KWS that use single-stage word-level neural networks. Our results show that the new techniques give superior accuracy for detecting wake words' endpoints of up to 50 msec standard error versus human annotations, on par with the conventional Acoustic Model plus HMM forced alignment. To our knowledge, this is the first study of wake word endpoints detection methods for single-stage neural KWS.