 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny-CRNN: Streaming Wakeword Detection In A Low Footprint Setting
Sep 29, 2021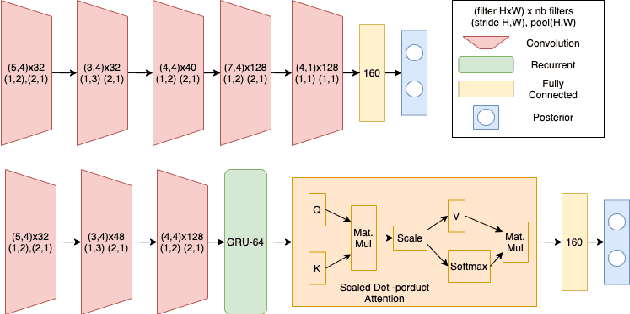
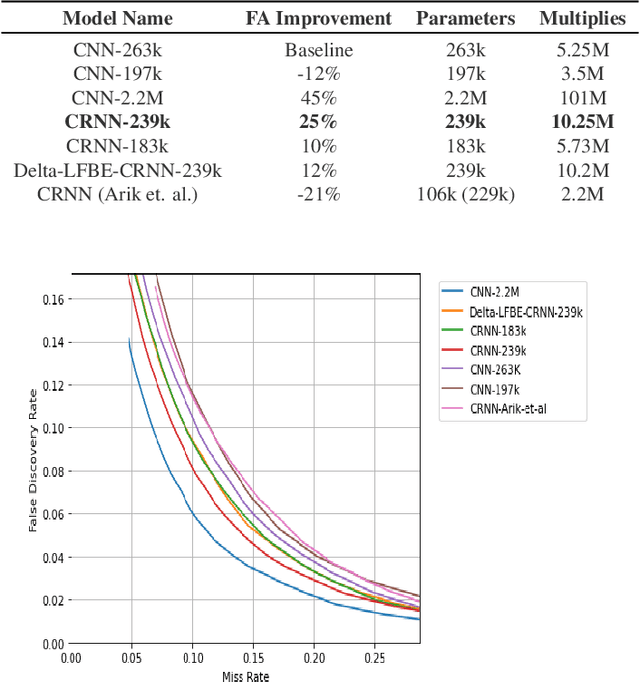
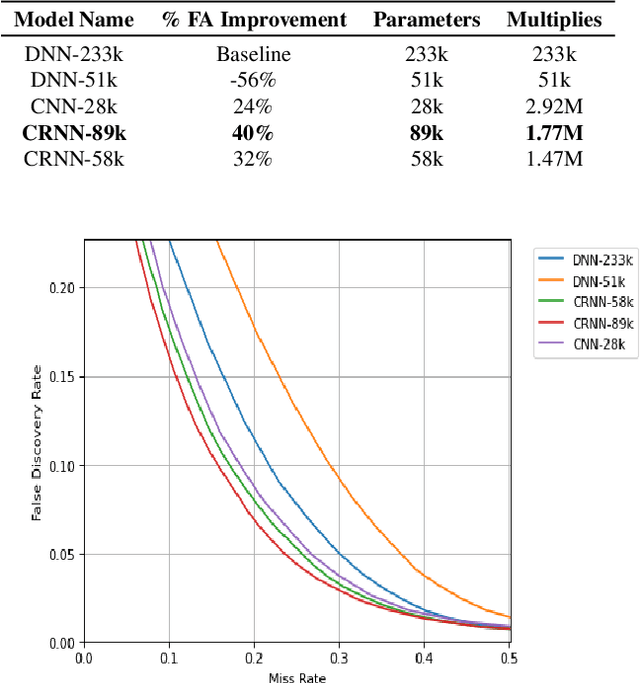
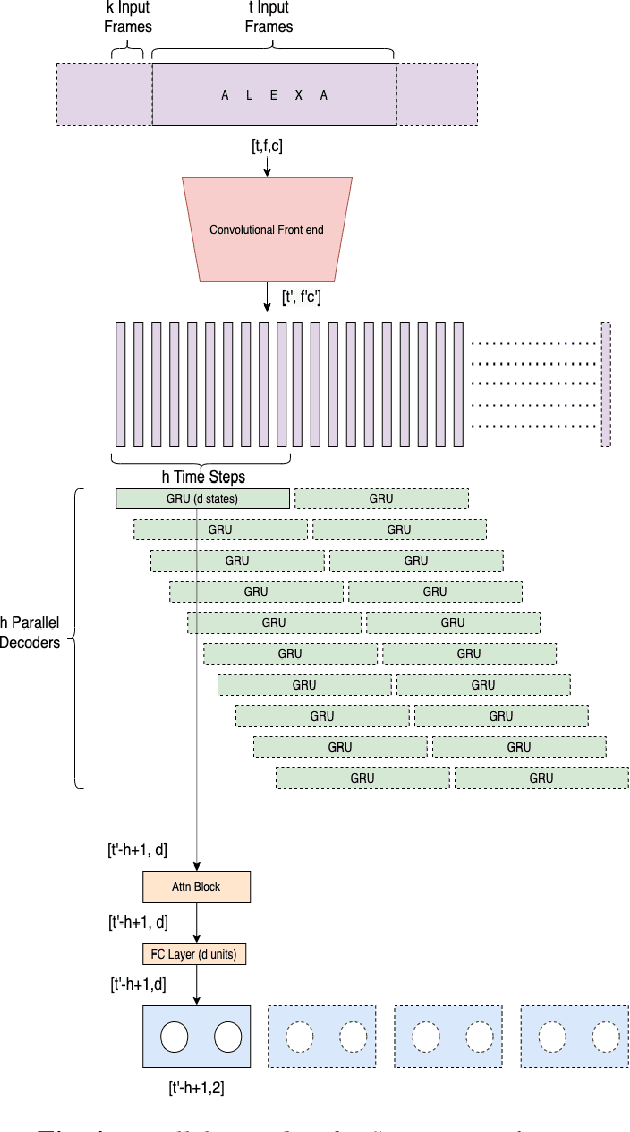
In this work, we propose Tiny-CRNN (Tiny Convolutional Recurrent Neural Network) models applied to the problem of wakeword detection, and augment them with scaled dot product attention. We find that, compared to Convolutional Neural Network models, False Accepts in a 250k parameter budget can be reduced by 25% with a 10% reduction in parameter size by using models based on the Tiny-CRNN architecture, and we can get up to 32% reduction in False Accepts at a 50k parameter budget with 75% reduction in parameter size compared to word-level Dense Neural Network models. We discuss solutions to the challenging problem of performing inference on streaming audio with this architecture, as well as differences in start-end index errors and latency in comparison to CNN, DNN, and DNN-HMM models.
Max-Pooling Loss Training of Long Short-Term Memory Networks for Small-Footprint Keyword Spotting
May 05, 2017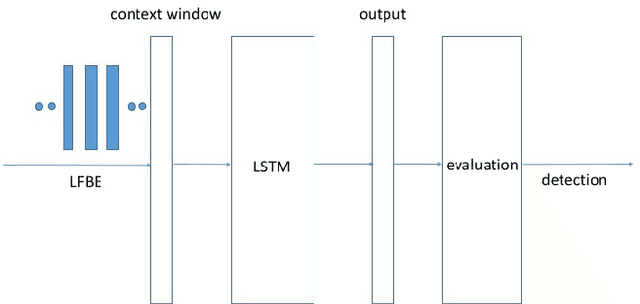

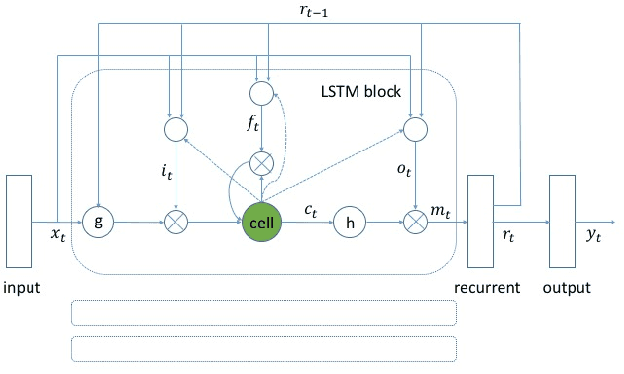
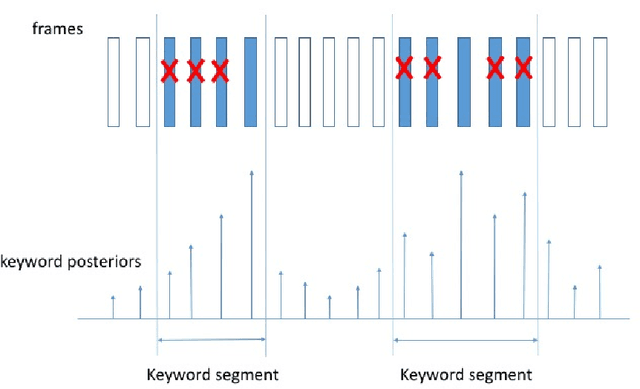
We propose a max-pooling based loss function for training Long Short-Term Memory (LSTM) networks for small-footprint keyword spotting (KWS), with low CPU, memory, and latency requirements. The max-pooling loss training can be further guided by initializing with a cross-entropy loss trained network. A posterior smoothing based evaluation approach is employed to measure keyword spotting performance. Our experimental results show that LSTM models trained using cross-entropy loss or max-pooling loss outperform a cross-entropy loss trained baseline feed-forward Deep Neural Network (DNN). In addition, max-pooling loss trained LSTM with randomly initialized network performs better compared to cross-entropy loss trained LSTM. Finally, the max-pooling loss trained LSTM initialized with a cross-entropy pre-trained network shows the best performance, which yields $67.6\%$ relative reduction compared to baseline feed-forward DNN in Area Under the Curve (AUC) measure.