 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023



The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
Alexa Arena: A User-Centric Interactive Platform for Embodied AI
Mar 02, 2023



We introduce Alexa Arena, a user-centric simulation platform for Embodied AI (EAI) research. Alexa Arena provides a variety of multi-room layouts and interactable objects, for the creation of human-robot interaction (HRI) missions. With user-friendly graphics and control mechanisms, Alexa Arena supports the development of gamified robotic tasks readily accessible to general human users, thus opening a new venue for high-efficiency HRI data collection and EAI system evaluation. Along with the platform, we introduce a dialog-enabled instruction-following benchmark and provide baseline results for it. We make Alexa Arena publicly available to facilitate research in building generalizable and assistive embodied agents.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
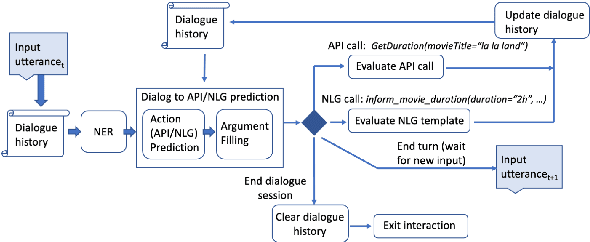

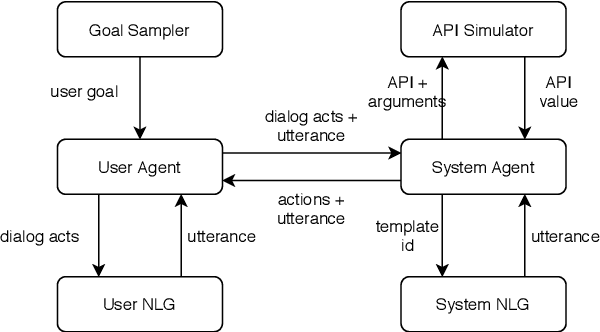
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
Advancing the State of the Art in Open Domain Dialog Systems through the Alexa Prize
Dec 27, 2018
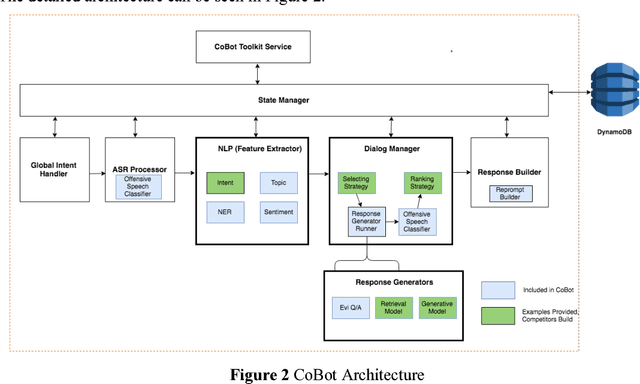
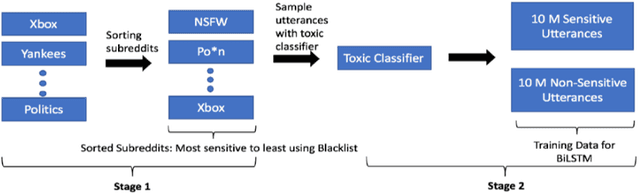
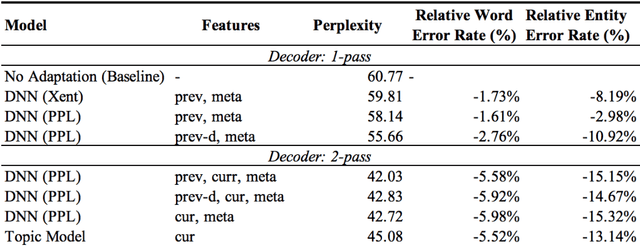
Building open domain conversational systems that allow users to have engaging conversations on topics of their choice is a challenging task. Alexa Prize was launched in 2016 to tackle the problem of achieving natural, sustained, coherent and engaging open-domain dialogs. In the second iteration of the competition in 2018, university teams advanced the state of the art by using context in dialog models, leveraging knowledge graphs for language understanding, handling complex utterances, building statistical and hierarchical dialog managers, and leveraging model-driven signals from user responses. The 2018 competition also included the provision of a suite of tools and models to the competitors including the CoBot (conversational bot) toolkit, topic and dialog act detection models, conversation evaluators, and a sensitive content detection model so that the competing teams could focus on building knowledge-rich, coherent and engaging multi-turn dialog systems. This paper outlines the advances developed by the university teams as well as the Alexa Prize team to achieve the common goal of advancing the science of Conversational AI. We address several key open-ended problems such as conversational speech recognition, open domain natural language understanding, commonsense reasoning, statistical dialog management, and dialog evaluation. These collaborative efforts have driven improved experiences by Alexa users to an average rating of 3.61, the median duration of 2 mins 18 seconds, and average turns to 14.6, increases of 14%, 92%, 54% respectively since the launch of the 2018 competition. For conversational speech recognition, we have improved our relative Word Error Rate by 55% and our relative Entity Error Rate by 34% since the launch of the Alexa Prize. Socialbots improved in quality significantly more rapidly in 2018, in part due to the release of the CoBot toolkit.
Detecting Offensive Content in Open-domain Conversations using Two Stage Semi-supervision
Nov 30, 2018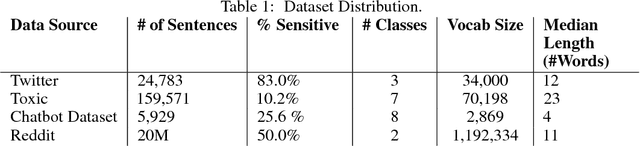
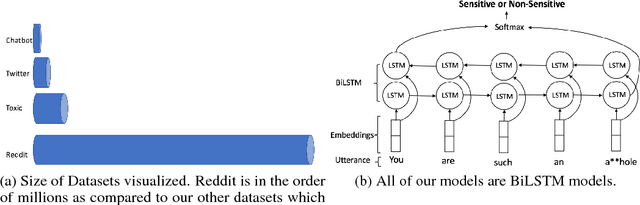
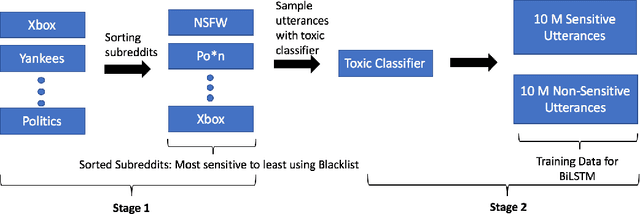
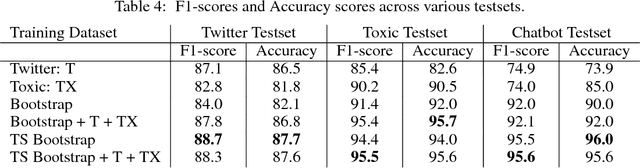
As open-ended human-chatbot interaction becomes commonplace, sensitive content detection gains importance. In this work, we propose a two stage semi-supervised approach to bootstrap large-scale data for automatic sensitive language detection from publicly available web resources. We explore various data selection methods including 1) using a blacklist to rank online discussion forums by the level of their sensitiveness followed by randomly sampling utterances and 2) training a weakly supervised model in conjunction with the blacklist for scoring sentences from online discussion forums to curate a dataset. Our data collection strategy is flexible and allows the models to detect implicit sensitive content for which manual annotations may be difficult. We train models using publicly available annotated datasets as well as using the proposed large-scale semi-supervised datasets. We evaluate the performance of all the models on Twitter and Toxic Wikipedia comments testsets as well as on a manually annotated spoken language dataset collected during a large scale chatbot competition. Results show that a model trained on this collected data outperforms the baseline models by a large margin on both in-domain and out-of-domain testsets, achieving an F1 score of 95.5% on an out-of-domain testset compared to a score of 75% for models trained on public datasets. We also showcase that large scale two stage semi-supervision generalizes well across multiple classes of sensitivities such as hate speech, racism, sexual and pornographic content, etc. without even providing explicit labels for these classes, leading to an average recall of 95.5% versus the models trained using annotated public datasets which achieve an average recall of 73.2% across seven sensitive classes on out-of-domain testsets.
Flexible and Scalable State Tracking Framework for Goal-Oriented Dialogue Systems
Nov 30, 2018


Goal-oriented dialogue systems typically rely on components specifically developed for a single task or domain. This limits such systems in two different ways: If there is an update in the task domain, the dialogue system usually needs to be updated or completely re-trained. It is also harder to extend such dialogue systems to different and multiple domains. The dialogue state tracker in conventional dialogue systems is one such component - it is usually designed to fit a well-defined application domain. For example, it is common for a state variable to be a categorical distribution over a manually-predefined set of entities (Henderson et al., 2013), resulting in an inflexible and hard-to-extend dialogue system. In this paper, we propose a new approach for dialogue state tracking that can generalize well over multiple domains without incorporating any domain-specific knowledge. Under this framework, discrete dialogue state variables are learned independently and the information of a predefined set of possible values for dialogue state variables is not required. Furthermore, it enables adding arbitrary dialogue context as features and allows for multiple values to be associated with a single state variable. These characteristics make it much easier to expand the dialogue state space. We evaluate our framework using the widely used dialogue state tracking challenge data set (DSTC2) and show that our framework yields competitive results with other state-of-the-art results despite incorporating little domain knowledge. We also show that this framework can benefit from widely available external resources such as pre-trained word embeddings.
Parsing Coordination for Spoken Language Understanding
Oct 26, 2018

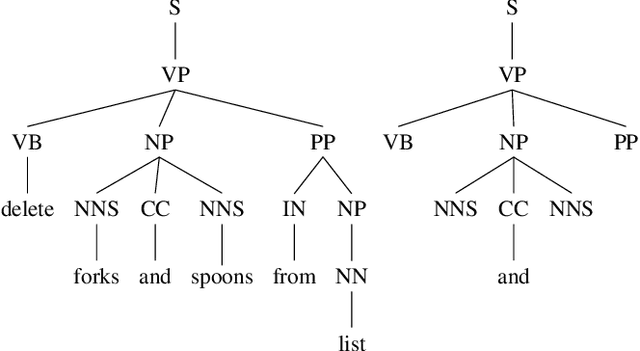
Typical spoken language understanding systems provide narrow semantic parses using a domain-specific ontology. The parses contain intents and slots that are directly consumed by downstream domain applications. In this work we discuss expanding such systems to handle compound entities and intents by introducing a domain-agnostic shallow parser that handles linguistic coordination. We show that our model for parsing coordination learns domain-independent and slot-independent features and is able to segment conjunct boundaries of many different phrasal categories. We also show that using adversarial training can be effective for improving generalization across different slot types for coordination parsing.
Contextual Topic Modeling For Dialog Systems
Oct 19, 2018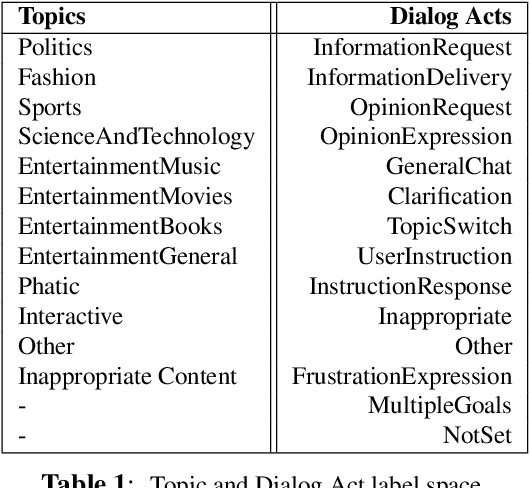
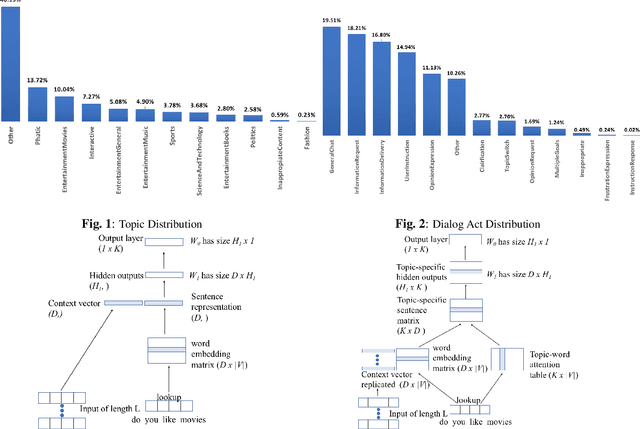

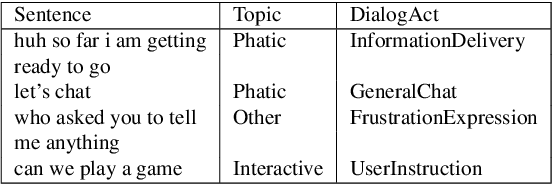
Accurate prediction of conversation topics can be a valuable signal for creating coherent and engaging dialog systems. In this work, we focus on context-aware topic classification methods for identifying topics in free-form human-chatbot dialogs. We extend previous work on neural topic classification and unsupervised topic keyword detection by incorporating conversational context and dialog act features. On annotated data, we show that incorporating context and dialog acts leads to relative gains in topic classification accuracy by 35% and on unsupervised keyword detection recall by 11% for conversational interactions where topics frequently span multiple utterances. We show that topical metrics such as topical depth is highly correlated with dialog evaluation metrics such as coherence and engagement implying that conversational topic models can predict user satisfaction. Our work for detecting conversation topics and keywords can be used to guide chatbots towards coherent dialog.
Data Augmentation for Robust Keyword Spotting under Playback Interference
Aug 01, 2018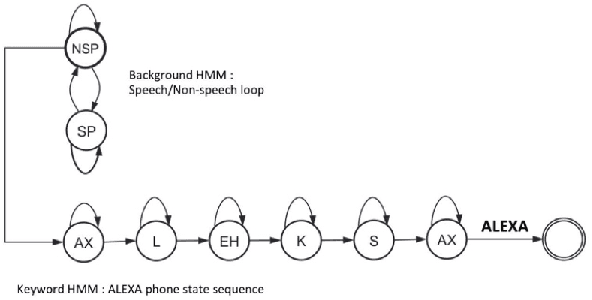
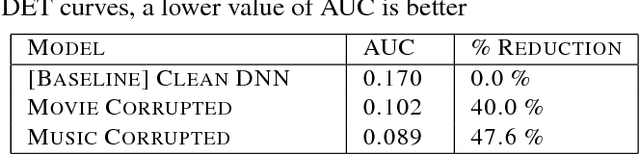
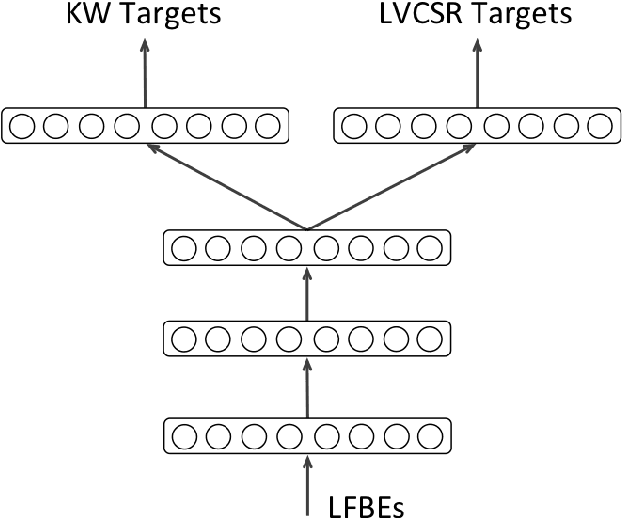
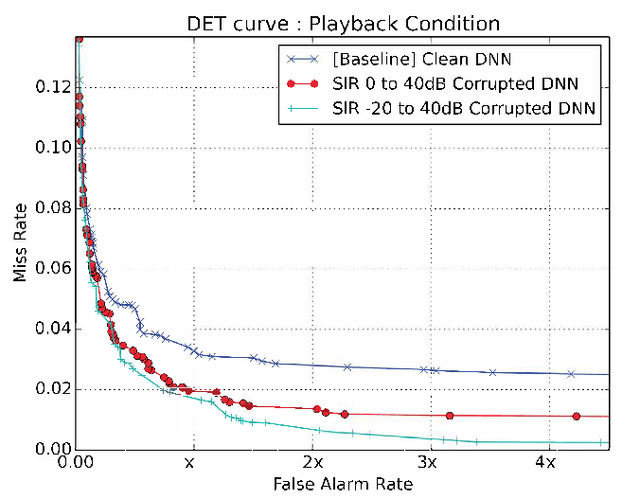
Accurate on-device keyword spotting (KWS) with low false accept and false reject rate is crucial to customer experience for far-field voice control of conversational agents. It is particularly challenging to maintain low false reject rate in real world conditions where there is (a) ambient noise from external sources such as TV, household appliances, or other speech that is not directed at the device (b) imperfect cancellation of the audio playback from the device, resulting in residual echo, after being processed by the Acoustic Echo Cancellation (AEC) system. In this paper, we propose a data augmentation strategy to improve keyword spotting performance under these challenging conditions. The training set audio is artificially corrupted by mixing in music and TV/movie audio, at different signal to interference ratios. Our results show that we get around 30-45% relative reduction in false reject rates, at a range of false alarm rates, under audio playback from such devices.
Max-Pooling Loss Training of Long Short-Term Memory Networks for Small-Footprint Keyword Spotting
May 05, 2017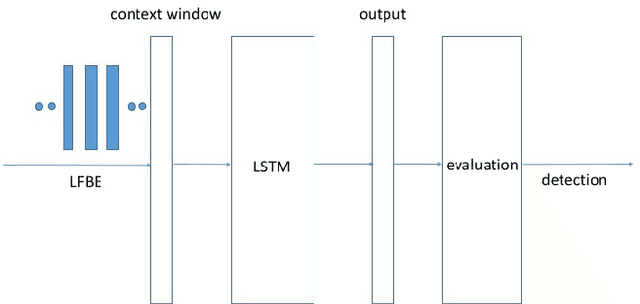

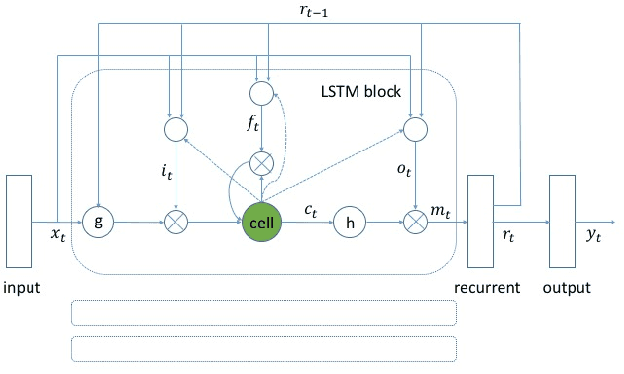
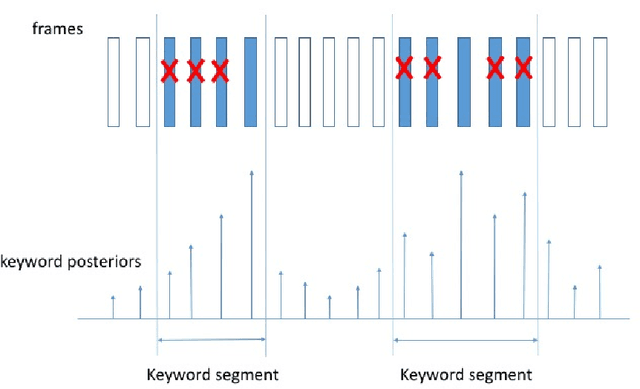
We propose a max-pooling based loss function for training Long Short-Term Memory (LSTM) networks for small-footprint keyword spotting (KWS), with low CPU, memory, and latency requirements. The max-pooling loss training can be further guided by initializing with a cross-entropy loss trained network. A posterior smoothing based evaluation approach is employed to measure keyword spotting performance. Our experimental results show that LSTM models trained using cross-entropy loss or max-pooling loss outperform a cross-entropy loss trained baseline feed-forward Deep Neural Network (DNN). In addition, max-pooling loss trained LSTM with randomly initialized network performs better compared to cross-entropy loss trained LSTM. Finally, the max-pooling loss trained LSTM initialized with a cross-entropy pre-trained network shows the best performance, which yields $67.6\%$ relative reduction compared to baseline feed-forward DNN in Area Under the Curve (AUC) measure.