 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Offensive Content in Open-domain Conversations using Two Stage Semi-supervision
Nov 30, 2018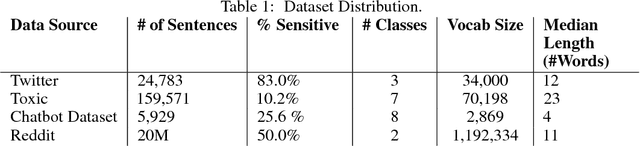
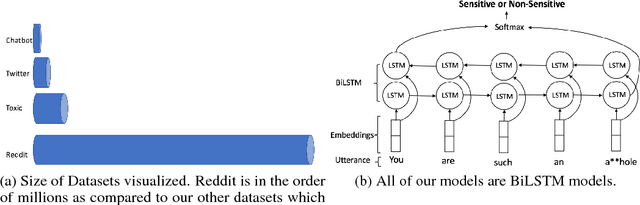
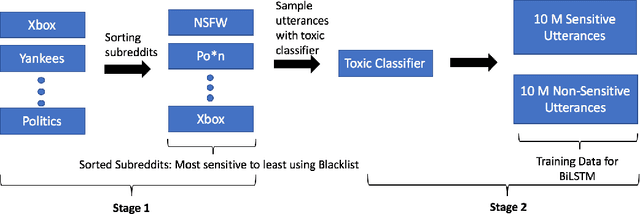
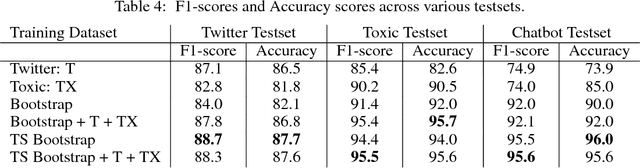
As open-ended human-chatbot interaction becomes commonplace, sensitive content detection gains importance. In this work, we propose a two stage semi-supervised approach to bootstrap large-scale data for automatic sensitive language detection from publicly available web resources. We explore various data selection methods including 1) using a blacklist to rank online discussion forums by the level of their sensitiveness followed by randomly sampling utterances and 2) training a weakly supervised model in conjunction with the blacklist for scoring sentences from online discussion forums to curate a dataset. Our data collection strategy is flexible and allows the models to detect implicit sensitive content for which manual annotations may be difficult. We train models using publicly available annotated datasets as well as using the proposed large-scale semi-supervised datasets. We evaluate the performance of all the models on Twitter and Toxic Wikipedia comments testsets as well as on a manually annotated spoken language dataset collected during a large scale chatbot competition. Results show that a model trained on this collected data outperforms the baseline models by a large margin on both in-domain and out-of-domain testsets, achieving an F1 score of 95.5% on an out-of-domain testset compared to a score of 75% for models trained on public datasets. We also showcase that large scale two stage semi-supervision generalizes well across multiple classes of sensitivities such as hate speech, racism, sexual and pornographic content, etc. without even providing explicit labels for these classes, leading to an average recall of 95.5% versus the models trained using annotated public datasets which achieve an average recall of 73.2% across seven sensitive classes on out-of-domain testsets.
Contextual Topic Modeling For Dialog Systems
Oct 19, 2018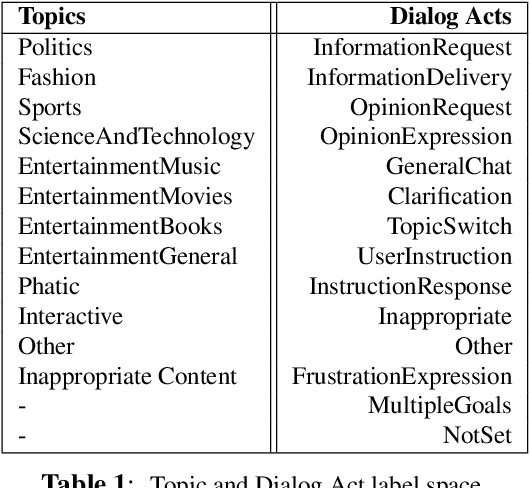

Accurate prediction of conversation topics can be a valuable signal for creating coherent and engaging dialog systems. In this work, we focus on context-aware topic classification methods for identifying topics in free-form human-chatbot dialogs. We extend previous work on neural topic classification and unsupervised topic keyword detection by incorporating conversational context and dialog act features. On annotated data, we show that incorporating context and dialog acts leads to relative gains in topic classification accuracy by 35% and on unsupervised keyword detection recall by 11% for conversational interactions where topics frequently span multiple utterances. We show that topical metrics such as topical depth is highly correlated with dialog evaluation metrics such as coherence and engagement implying that conversational topic models can predict user satisfaction. Our work for detecting conversation topics and keywords can be used to guide chatbots towards coherent dialog.