 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBhashaKritika: Building Synthetic Pretraining Data at Scale for Indic Languages
Nov 16, 2025In the context of pretraining of Large Language Models (LLMs), synthetic data has emerged as an alternative for generating high-quality pretraining data at scale. This is particularly beneficial in low-resource language settings where the benefits of recent LLMs have been unevenly distributed across languages. In this work, we present a systematic study on the generation and evaluation of synthetic multilingual pretraining data for Indic languages, where we construct a large-scale synthetic dataset BhashaKritika, comprising 540B tokens using 5 different techniques for 10 languages. We explore the impact of grounding generation in documents, personas, and topics. We analyze how language choice, both in the prompt instructions and document grounding, affects data quality, and we compare translations of English content with native generation in Indic languages. To support scalable and language-sensitive evaluation, we introduce a modular quality evaluation pipeline that integrates script and language detection, metadata consistency checks, n-gram repetition analysis, and perplexity-based filtering using KenLM models. Our framework enables robust quality control across diverse scripts and linguistic contexts. Empirical results through model runs reveal key trade-offs in generation strategies and highlight best practices for constructing effective multilingual corpora.
Seeing Straight: Document Orientation Detection for Efficient OCR
Nov 06, 2025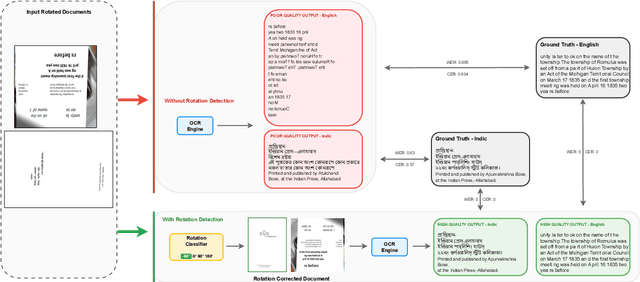



Despite significant advances in document understanding, determining the correct orientation of scanned or photographed documents remains a critical pre-processing step in the real world settings. Accurate rotation correction is essential for enhancing the performance of downstream tasks such as Optical Character Recognition (OCR) where misalignment commonly arises due to user errors, particularly incorrect base orientations of the camera during capture. In this study, we first introduce OCR-Rotation-Bench (ORB), a new benchmark for evaluating OCR robustness to image rotations, comprising (i) ORB-En, built from rotation-transformed structured and free-form English OCR datasets, and (ii) ORB-Indic, a novel multilingual set spanning 11 Indic mid to low-resource languages. We also present a fast, robust and lightweight rotation classification pipeline built on the vision encoder of Phi-3.5-Vision model with dynamic image cropping, fine-tuned specifically for 4-class rotation task in a standalone fashion. Our method achieves near-perfect 96% and 92% accuracy on identifying the rotations respectively on both the datasets. Beyond classification, we demonstrate the critical role of our module in boosting OCR performance: closed-source (up to 14%) and open-weights models (up to 4x) in the simulated real-world setting.
IndicVisionBench: Benchmarking Cultural and Multilingual Understanding in VLMs
Nov 06, 2025



Vision-language models (VLMs) have demonstrated impressive generalization across multimodal tasks, yet most evaluation benchmarks remain Western-centric, leaving open questions about their performance in culturally diverse and multilingual settings. To address this gap, we introduce IndicVisionBench, the first large-scale benchmark centered on the Indian subcontinent. Covering English and 10 Indian languages, our benchmark spans 3 multimodal tasks, including Optical Character Recognition (OCR), Multimodal Machine Translation (MMT), and Visual Question Answering (VQA), covering 6 kinds of question types. Our final benchmark consists of a total of ~5K images and 37K+ QA pairs across 13 culturally grounded topics. In addition, we release a paired parallel corpus of annotations across 10 Indic languages, creating a unique resource for analyzing cultural and linguistic biases in VLMs. We evaluate a broad spectrum of 8 models, from proprietary closed-source systems to open-weights medium and large-scale models. Our experiments reveal substantial performance gaps, underscoring the limitations of current VLMs in culturally diverse contexts. By centering cultural diversity and multilinguality, IndicVisionBench establishes a reproducible evaluation framework that paves the way for more inclusive multimodal research.
VoiceAgentBench: Are Voice Assistants ready for agentic tasks?
Oct 09, 2025
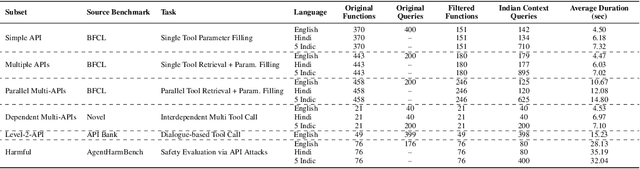
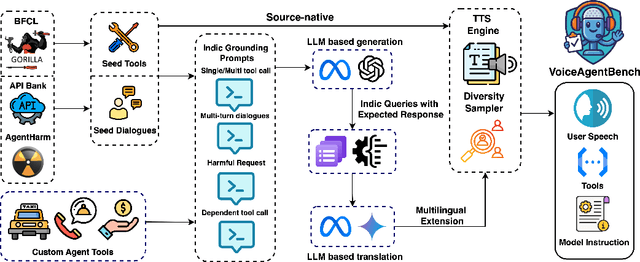
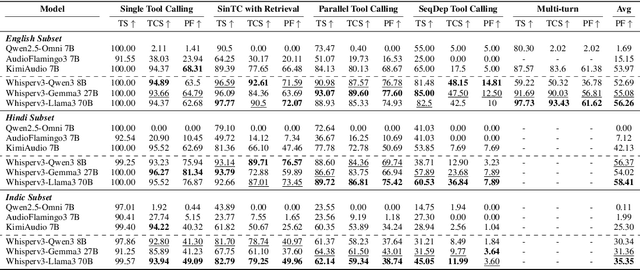
Large-scale Speech Language Models (SpeechLMs) have enabled voice assistants capable of understanding natural spoken queries and performing complex tasks. However, existing speech benchmarks primarily focus on isolated capabilities such as transcription, or question-answering, and do not systematically evaluate agentic scenarios encompassing multilingual and cultural understanding, as well as adversarial robustness. To address this, we introduce VoiceAgentBench, a comprehensive benchmark designed to evaluate SpeechLMs in realistic spoken agentic settings. It comprises over 5,500 synthetic spoken queries, including dialogues grounded in Indian context, covering single-tool invocations, multi-tool workflows, multi-turn interactions, and safety evaluations. The benchmark supports English, Hindi, and 5 other Indian languages, reflecting real-world linguistic and cultural diversity. We simulate speaker variability using a novel sampling algorithm that selects audios for TTS voice conversion based on its speaker embeddings, maximizing acoustic and speaker diversity. Our evaluation measures tool selection accuracy, structural consistency, and the correctness of tool invocations, including adversarial robustness. Our experiments reveal significant gaps in contextual tool orchestration tasks, Indic generalization, and adversarial robustness, exposing critical limitations of current SpeechLMs.
Pragyaan: Designing and Curating High-Quality Cultural Post-Training Datasets for Indian Languages
Oct 08, 2025The effectiveness of Large Language Models (LLMs) depends heavily on the availability of high-quality post-training data, particularly instruction-tuning and preference-based examples. Existing open-source datasets, however, often lack multilingual coverage, cultural grounding, and suffer from task diversity gaps that are especially pronounced for Indian languages. We introduce a human-in-the-loop pipeline that combines translations with synthetic expansion to produce reliable and diverse Indic post-training data. Using this pipeline, we curate two datasets: Pragyaan-IT (22.5K) and Pragyaan-Align (100K) across 10 Indian languages covering 13 broad and 56 sub-categories, leveraging 57 diverse datasets. Our dataset protocol incorporates several often-overlooked dimensions and emphasize task diversity, multi-turn dialogue, instruction fidelity, safety alignment, and preservation of cultural nuance, providing a foundation for more inclusive and effective multilingual LLMs.
Chitranuvad: Adapting Multi-Lingual LLMs for Multimodal Translation
Feb 27, 2025In this work, we provide the system description of our submission as part of the English to Lowres Multimodal Translation Task at the Workshop on Asian Translation (WAT2024). We introduce Chitranuvad, a multimodal model that effectively integrates Multilingual LLM and a vision module for Multimodal Translation. Our method uses a ViT image encoder to extract visual representations as visual token embeddings which are projected to the LLM space by an adapter layer and generates translation in an autoregressive fashion. We participated in all the three tracks (Image Captioning, Text only and Multimodal translation tasks) for Indic languages (ie. English translation to Hindi, Bengali and Malyalam) and achieved SOTA results for Hindi in all of them on the Challenge set while remaining competitive for the other languages in the shared task.
Chitrarth: Bridging Vision and Language for a Billion People
Feb 21, 2025Recent multimodal foundation models are primarily trained on English or high resource European language data, which hinders their applicability to other medium and low-resource languages. To address this limitation, we introduce Chitrarth (Chitra: Image; Artha: Meaning), an inclusive Vision-Language Model (VLM), specifically targeting the rich linguistic diversity and visual reasoning across 10 prominent Indian languages. Our model effectively integrates a state-of-the-art (SOTA) multilingual Large Language Model (LLM) with a vision module, primarily trained on multilingual image-text data. Furthermore, we also introduce BharatBench, a comprehensive framework for evaluating VLMs across various Indian languages, ultimately contributing to more diverse and effective AI systems. Our model achieves SOTA results for benchmarks across low resource languages while retaining its efficiency in English. Through our research, we aim to set new benchmarks in multilingual-multimodal capabilities, offering substantial improvements over existing models and establishing a foundation to facilitate future advancements in this arena.
Towards Automatic Evaluation of Task-Oriented Dialogue Flows
Nov 15, 2024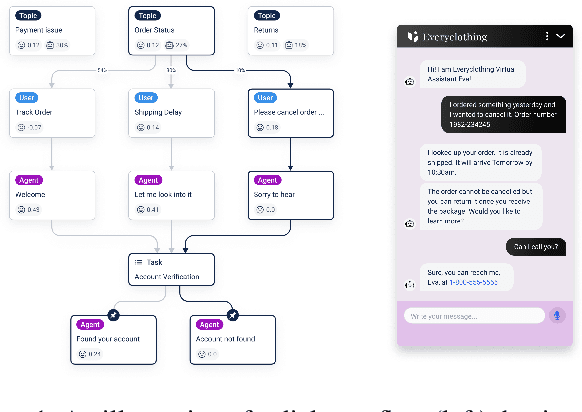
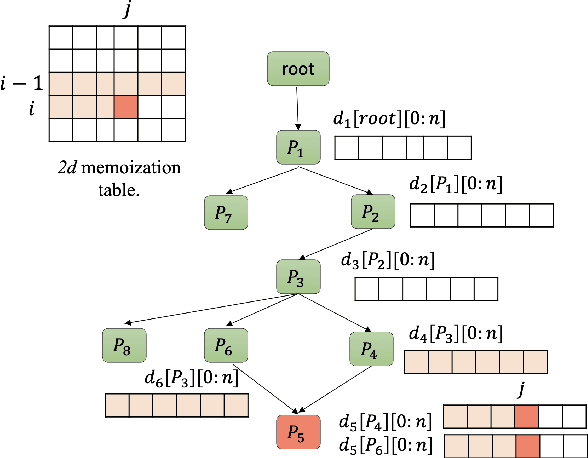
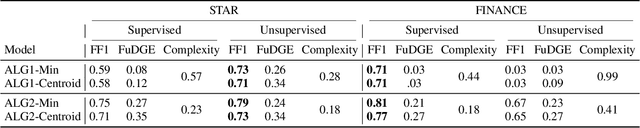
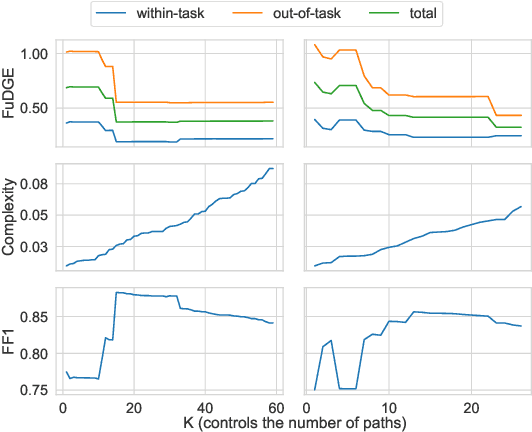
Task-oriented dialogue systems rely on predefined conversation schemes (dialogue flows) often represented as directed acyclic graphs. These flows can be manually designed or automatically generated from previously recorded conversations. Due to variations in domain expertise or reliance on different sets of prior conversations, these dialogue flows can manifest in significantly different graph structures. Despite their importance, there is no standard method for evaluating the quality of dialogue flows. We introduce FuDGE (Fuzzy Dialogue-Graph Edit Distance), a novel metric that evaluates dialogue flows by assessing their structural complexity and representational coverage of the conversation data. FuDGE measures how well individual conversations align with a flow and, consequently, how well a set of conversations is represented by the flow overall. Through extensive experiments on manually configured flows and flows generated by automated techniques, we demonstrate the effectiveness of FuDGE and its evaluation framework. By standardizing and optimizing dialogue flows, FuDGE enables conversational designers and automated techniques to achieve higher levels of efficiency and automation.
KULCQ: An Unsupervised Keyword-based Utterance Level Clustering Quality Metric
Nov 15, 2024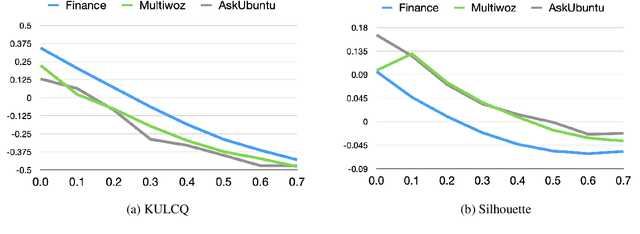


Intent discovery is crucial for both building new conversational agents and improving existing ones. While several approaches have been proposed for intent discovery, most rely on clustering to group similar utterances together. Traditional evaluation of these utterance clusters requires intent labels for each utterance, limiting scalability. Although some clustering quality metrics exist that do not require labeled data, they focus solely on cluster geometry while ignoring the linguistic nuances present in conversational transcripts. In this paper, we introduce Keyword-based Utterance Level Clustering Quality (KULCQ), an unsupervised metric that leverages keyword analysis to evaluate clustering quality. We demonstrate KULCQ's effectiveness by comparing it with existing unsupervised clustering metrics and validate its performance through comprehensive ablation studies. Our results show that KULCQ better captures semantic relationships in conversational data while maintaining consistency with geometric clustering principles.
Joint Contextual Modeling for ASR Correction and Language Understanding
Jan 28, 2020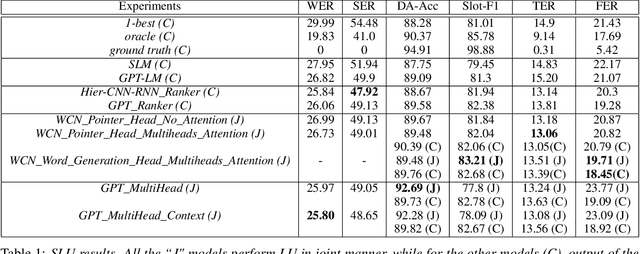
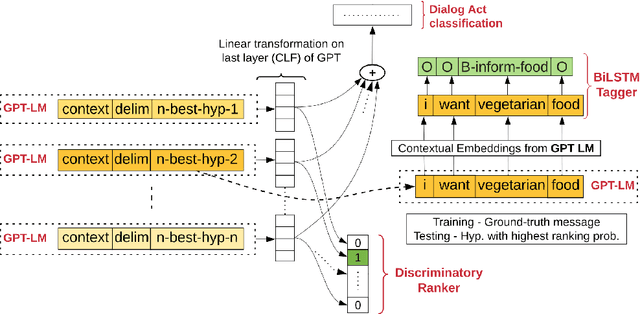
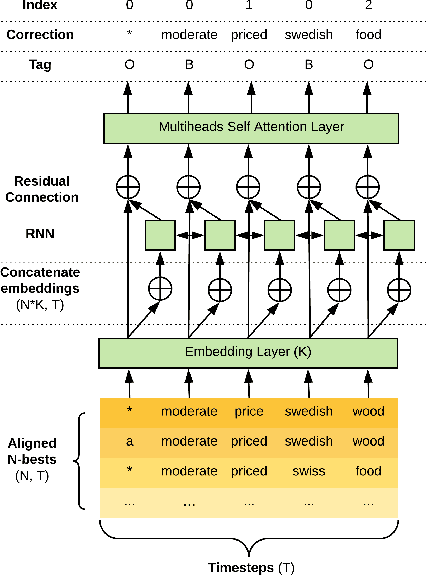
The quality of automatic speech recognition (ASR) is critical to Dialogue Systems as ASR errors propagate to and directly impact downstream tasks such as language understanding (LU). In this paper, we propose multi-task neural approaches to perform contextual language correction on ASR outputs jointly with LU to improve the performance of both tasks simultaneously. To measure the effectiveness of this approach we used a public benchmark, the 2nd Dialogue State Tracking (DSTC2) corpus. As a baseline approach, we trained task-specific Statistical Language Models (SLM) and fine-tuned state-of-the-art Generalized Pre-training (GPT) Language Model to re-rank the n-best ASR hypotheses, followed by a model to identify the dialog act and slots. i) We further trained ranker models using GPT and Hierarchical CNN-RNN models with discriminatory losses to detect the best output given n-best hypotheses. We extended these ranker models to first select the best ASR output and then identify the dialogue act and slots in an end to end fashion. ii) We also proposed a novel joint ASR error correction and LU model, a word confusion pointer network (WCN-Ptr) with multi-head self-attention on top, which consumes the word confusions populated from the n-best. We show that the error rates of off the shelf ASR and following LU systems can be reduced significantly by 14% relative with joint models trained using small amounts of in-domain data.