 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChitrarth: Bridging Vision and Language for a Billion People
Feb 21, 2025Recent multimodal foundation models are primarily trained on English or high resource European language data, which hinders their applicability to other medium and low-resource languages. To address this limitation, we introduce Chitrarth (Chitra: Image; Artha: Meaning), an inclusive Vision-Language Model (VLM), specifically targeting the rich linguistic diversity and visual reasoning across 10 prominent Indian languages. Our model effectively integrates a state-of-the-art (SOTA) multilingual Large Language Model (LLM) with a vision module, primarily trained on multilingual image-text data. Furthermore, we also introduce BharatBench, a comprehensive framework for evaluating VLMs across various Indian languages, ultimately contributing to more diverse and effective AI systems. Our model achieves SOTA results for benchmarks across low resource languages while retaining its efficiency in English. Through our research, we aim to set new benchmarks in multilingual-multimodal capabilities, offering substantial improvements over existing models and establishing a foundation to facilitate future advancements in this arena.
MUSTAN: Multi-scale Temporal Context as Attention for Robust Video Foreground Segmentation
Feb 01, 2024Video foreground segmentation (VFS) is an important computer vision task wherein one aims to segment the objects under motion from the background. Most of the current methods are image-based, i.e., rely only on spatial cues while ignoring motion cues. Therefore, they tend to overfit the training data and don't generalize well to out-of-domain (OOD) distribution. To solve the above problem, prior works exploited several cues such as optical flow, background subtraction mask, etc. However, having a video data with annotations like optical flow is a challenging task. In this paper, we utilize the temporal information and the spatial cues from the video data to improve OOD performance. However, the challenge lies in how we model the temporal information given the video data in an interpretable way creates a very noticeable difference. We therefore devise a strategy that integrates the temporal context of the video in the development of VFS. Our approach give rise to deep learning architectures, namely MUSTAN1 and MUSTAN2 and they are based on the idea of multi-scale temporal context as an attention, i.e., aids our models to learn better representations that are beneficial for VFS. Further, we introduce a new video dataset, namely Indoor Surveillance Dataset (ISD) for VFS. It has multiple annotations on a frame level such as foreground binary mask, depth map, and instance semantic annotations. Therefore, ISD can benefit other computer vision tasks. We validate the efficacy of our architectures and compare the performance with baselines. We demonstrate that proposed methods significantly outperform the benchmark methods on OOD. In addition, the performance of MUSTAN2 is significantly improved on certain video categories on OOD data due to ISD.
AQUALLM: Audio Question Answering Data Generation Using Large Language Models
Dec 28, 2023Audio Question Answering (AQA) constitutes a pivotal task in which machines analyze both audio signals and natural language questions to produce precise natural language answers. The significance of possessing high-quality, diverse, and extensive AQA datasets cannot be overstated when aiming for the precision of an AQA system. While there has been notable focus on developing accurate and efficient AQA models, the creation of high-quality, diverse, and extensive datasets for the specific task at hand has not garnered considerable attention. To address this challenge, this work makes several contributions. We introduce a scalable AQA data generation pipeline, denoted as the AQUALLM framework, which relies on Large Language Models (LLMs). This framework utilizes existing audio-caption annotations and incorporates state-of-the-art LLMs to generate expansive, high-quality AQA datasets. Additionally, we present three extensive and high-quality benchmark datasets for AQA, contributing significantly to the progression of AQA research. AQA models trained on the proposed datasets set superior benchmarks compared to the existing state-of-the-art. Moreover, models trained on our datasets demonstrate enhanced generalizability when compared to models trained using human-annotated AQA data. Code and datasets will be accessible on GitHub~\footnote{\url{https://github.com/swarupbehera/AQUALLM}}.
Learning Generative Prior with Latent Space Sparsity Constraints
May 25, 2021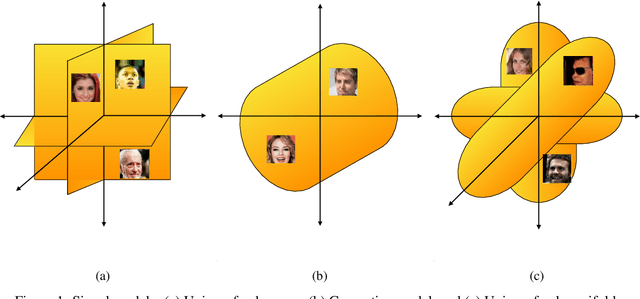

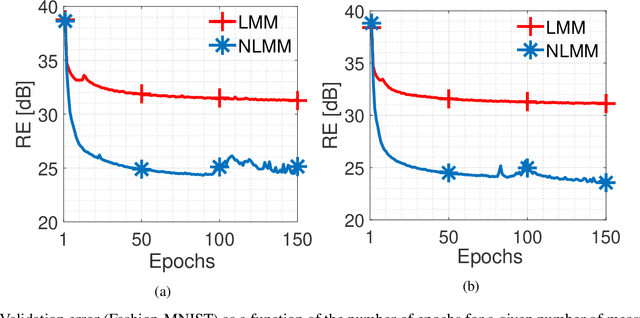

We address the problem of compressed sensing using a deep generative prior model and consider both linear and learned nonlinear sensing mechanisms, where the nonlinear one involves either a fully connected neural network or a convolutional neural network. Recently, it has been argued that the distribution of natural images do not lie in a single manifold but rather lie in a union of several submanifolds. We propose a sparsity-driven latent space sampling (SDLSS) framework and develop a proximal meta-learning (PML) algorithm to enforce sparsity in the latent space. SDLSS allows the range-space of the generator to be considered as a union-of-submanifolds. We also derive the sample complexity bounds within the SDLSS framework for the linear measurement model. The results demonstrate that for a higher degree of compression, the SDLSS method is more efficient than the state-of-the-art method. We first consider a comparison between linear and nonlinear sensing mechanisms on Fashion-MNIST dataset and show that the learned nonlinear version is superior to the linear one. Subsequent comparisons with the deep compressive sensing (DCS) framework proposed in the literature are reported. We also consider the effect of the dimension of the latent space and the sparsity factor in validating the SDLSS framework. Performance quantification is carried out by employing three objective metrics: peak signal-to-noise ratio (PSNR), structural similarity index metric (SSIM), and reconstruction error (RE).
Quantized Proximal Averaging Network for Analysis Sparse Coding
May 13, 2021


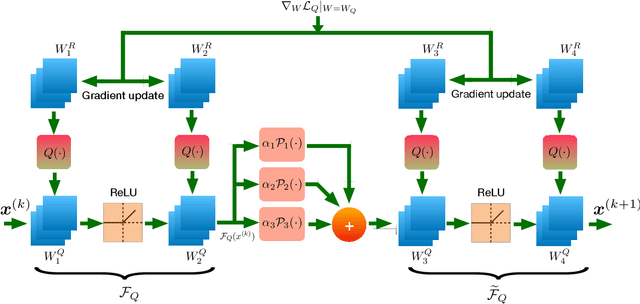
We solve the analysis sparse coding problem considering a combination of convex and non-convex sparsity promoting penalties. The multi-penalty formulation results in an iterative algorithm involving proximal-averaging. We then unfold the iterative algorithm into a trainable network that facilitates learning the sparsity prior. We also consider quantization of the network weights. Quantization makes neural networks efficient both in terms of memory and computation during inference, and also renders them compatible for low-precision hardware deployment. Our learning algorithm is based on a variant of the ADAM optimizer in which the quantizer is part of the forward pass and the gradients of the loss function are evaluated corresponding to the quantized weights while doing a book-keeping of the high-precision weights. We demonstrate applications to compressed image recovery and magnetic resonance image reconstruction. The proposed approach offers superior reconstruction accuracy and quality than state-of-the-art unfolding techniques and the performance degradation is minimal even when the weights are subjected to extreme quantization.
NuSPAN: A Proximal Average Network for Nonuniform Sparse Model -- Application to Seismic Reflectivity Inversion
May 01, 2021



We solve the problem of sparse signal deconvolution in the context of seismic reflectivity inversion, which pertains to high-resolution recovery of the subsurface reflection coefficients. Our formulation employs a nonuniform, non-convex synthesis sparse model comprising a combination of convex and non-convex regularizers, which results in accurate approximations of the l0 pseudo-norm. The resulting iterative algorithm requires the proximal average strategy. When unfolded, the iterations give rise to a learnable proximal average network architecture that can be optimized in a data-driven fashion. We demonstrate the efficacy of the proposed approach through numerical experiments on synthetic 1-D seismic traces and 2-D wedge models in comparison with the benchmark techniques. We also present validations considering the simulated Marmousi2 model as well as real 3-D seismic volume data acquired from the Penobscot 3D survey off the coast of Nova Scotia, Canada.
DuRIN: A Deep-unfolded Sparse Seismic Reflectivity Inversion Network
Apr 10, 2021



We consider the reflection seismology problem of recovering the locations of interfaces and the amplitudes of reflection coefficients from seismic data, which are vital for estimating the subsurface structure. The reflectivity inversion problem is typically solved using greedy algorithms and iterative techniques. Sparse Bayesian learning framework, and more recently, deep learning techniques have shown the potential of data-driven approaches to solve the problem. In this paper, we propose a weighted minimax-concave penalty-regularized reflectivity inversion formulation and solve it through a model-based neural network. The network is referred to as deep-unfolded reflectivity inversion network (DuRIN). We demonstrate the efficacy of the proposed approach over the benchmark techniques by testing on synthetic 1-D seismic traces and 2-D wedge models and validation with the simulated 2-D Marmousi2 model and real data from the Penobscot 3D survey off the coast of Nova Scotia, Canada.