 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Time is Here for Just-in-Time Systems: Challenges and Opportunities
May 22, 2026Core systems like key-value stores have historically taken years to build, and are designed to be general so as to amortize cost across deployments, paying a significant performance cost. We argue that LLM-based coding agents now make a different approach tractable: Just-in-Time Systems, in which the entire system is synthesized from scratch, specialized to the environment, workload, and required system properties. We present a JIT system synthesis pipeline, Jitskit, and explore its effectiveness in synthesizing key-value stores from spec cards that span different YCSB workloads, deployment constraints (e.g., compute resources), and system properties (e.g., consistency and durability). Jitskit iteratively refines a system implementation to match the specification against an evolving evaluation test suite. The resulting synthesized systems are performant, beating comparable state-of-the-art systems on 18 of 18 specs tried, by up to 4.6x over the best off-the-shelf baseline on the most favorable spec. Naively running Claude Code either reward-hacks or underperforms Jitskit by up to 5.4x. We discuss the challenges we overcame in building Jitskit and our key takeaways.
Inductive Deductive Synthesis: Enabling AI to Generate Formally Verified Systems
May 22, 2026AI agents increasingly excel at generating, testing, and refining code. However, they fall short on tasks requiring formal guarantees of full coverage that testing alone cannot provide. Distributed systems are a prime example: properties such as consistency between reads and writes must hold under every possible interleaving of events. Mechanized formal verification can guarantee such correctness, but typically demands months to years of expert effort. As evidence, even SOTA coding agents (Codex with GPT-5.4 and Claude Code with Opus 4.6) succeed on only 2/7 distributed key-value-store specifications. In this paper, we present the first effective approach to addressing this gap, Inductive Deductive Synthesis (IDS), which jointly and incrementally synthesizes implementation and proof, and learns from failed attempts to systematically try promising strategies. Built as an agentic LLM system, IDS achieves 7/7 in about 6.8 hours and $106 per spec on average, roughly 200x faster than expert effort and 17% cheaper than SOTA agents. IDS further incorporates performance feedback into the same loop, yielding implementations up to 3x faster than published verified systems.
Designing Production-Scale OCR for India: Multilingual and Domain-Specific Systems
Feb 18, 2026Designing Optical Character Recognition (OCR) systems for India requires balancing linguistic diversity, document heterogeneity, and deployment constraints. In this paper, we study two training strategies for building multilingual OCR systems with Vision-Language Models through the Chitrapathak series. We first follow a popular multimodal approach, pairing a generic vision encoder with a strong multilingual language model and training the system end-to-end for OCR. Alternatively, we explore fine-tuning an existing OCR model, despite not being trained for the target languages. Through extensive evaluation on multilingual Indic OCR benchmarks and deployment-oriented metrics, we find that the second strategy consistently achieves better accuracy-latency trade-offs. Chitrapathak-2 achieves 3-6x speedup over its predecessor with being state-of-the-art (SOTA) in Telugu (6.69 char ANLS) and second best in the rest. In addition, we present Parichay, an independent OCR model series designed specifically for 9 Indian government documents to extract structured key fields, achieving 89.8% Exact Match score with a faster inference. Together, these systems achieve SOTA performance and provide practical guidance for building production-scale OCR pipelines in the Indian context.
Arming Data Agents with Tribal Knowledge
Feb 13, 2026Natural language to SQL (NL2SQL) translation enables non-expert users to query relational databases through natural language. Recently, NL2SQL agents, powered by the reasoning capabilities of Large Language Models (LLMs), have significantly advanced NL2SQL translation. Nonetheless, NL2SQL agents still make mistakes when faced with large-scale real-world databases because they lack knowledge of how to correctly leverage the underlying data (e.g., knowledge about the intent of each column) and form misconceptions about the data when querying it, leading to errors. Prior work has studied generating facts about the database to provide more context to NL2SQL agents, but such approaches simply restate database contents without addressing the agent's misconceptions. In this paper, we propose Tk-Boost, a bolt-on framework for augmenting any NL2SQL agent with tribal knowledge: knowledge that corrects the agent's misconceptions in querying the database accumulated through experience using the database. To accumulate experience, Tk-Boost first asks the NL2SQL agent to answer a few queries on the database, identifies the agent's misconceptions by analyzing its mistakes on the database, and generates tribal knowledge to address them. To enable accurate retrieval, Tk-Boost indexes this knowledge with applicability conditions that specify the query features for which the knowledge is useful. When answering new queries, Tk-Boost uses this knowledge to provide feedback to the NL2SQL agent, resolving the agent's misconceptions during SQL generation, and thus improving the agent's accuracy. Extensive experiments across the BIRD and Spider 2.0 benchmarks with various NL2SQL agents shows Tk-Boost improves NL2SQL agents accuracy by up to 16.9% on Spider 2.0 and 13.7% on BIRD
FlowCast: Trajectory Forecasting for Scalable Zero-Cost Speculative Flow Matching
Feb 01, 2026Flow Matching (FM) has recently emerged as a powerful approach for high-quality visual generation. However, their prohibitively slow inference due to a large number of denoising steps limits their potential use in real-time or interactive applications. Existing acceleration methods, like distillation, truncation, or consistency training, either degrade quality, incur costly retraining, or lack generalization. We propose FlowCast, a training-free speculative generation framework that accelerates inference by exploiting the fact that FM models are trained to preserve constant velocity. FlowCast speculates future velocity by extrapolating current velocity without incurring additional time cost, and accepts it if it is within a mean-squared error threshold. This constant-velocity forecasting allows redundant steps in stable regions to be aggressively skipped while retaining precision in complex ones. FlowCast is a plug-and-play framework that integrates seamlessly with any FM model and requires no auxiliary networks. We also present a theoretical analysis and bound the worst-case deviation between speculative and full FM trajectories. Empirical evaluations demonstrate that FlowCast achieves $>2.5\times$ speedup in image generation, video generation, and editing tasks, outperforming existing baselines with no quality loss as compared to standard full generation.
Let the Barbarians In: How AI Can Accelerate Systems Performance Research
Dec 22, 2025Artificial Intelligence (AI) is beginning to transform the research process by automating the discovery of new solutions. This shift depends on the availability of reliable verifiers, which AI-driven approaches require to validate candidate solutions. Research focused on improving systems performance is especially well-suited to this paradigm because system performance problems naturally admit such verifiers: candidates can be implemented in real systems or simulators and evaluated against predefined workloads. We term this iterative cycle of generation, evaluation, and refinement AI-Driven Research for Systems (ADRS). Using several open-source ADRS instances (i.e., OpenEvolve, GEPA, and ShinkaEvolve), we demonstrate across ten case studies (e.g., multi-region cloud scheduling, mixture-of-experts load balancing, LLM-based SQL, transaction scheduling) that ADRS-generated solutions can match or even outperform human state-of-the-art designs. Based on these findings, we outline best practices (e.g., level of prompt specification, amount of feedback, robust evaluation) for effectively using ADRS, and we discuss future research directions and their implications. Although we do not yet have a universal recipe for applying ADRS across all of systems research, we hope our preliminary findings, together with the challenges we identify, offer meaningful guidance for future work as researcher effort shifts increasingly toward problem formulation and strategic oversight. Note: This paper is an extension of our prior work [14]. It adds extensive evaluation across multiple ADRS frameworks and provides deeper analysis and insights into best practices.
BhashaKritika: Building Synthetic Pretraining Data at Scale for Indic Languages
Nov 16, 2025In the context of pretraining of Large Language Models (LLMs), synthetic data has emerged as an alternative for generating high-quality pretraining data at scale. This is particularly beneficial in low-resource language settings where the benefits of recent LLMs have been unevenly distributed across languages. In this work, we present a systematic study on the generation and evaluation of synthetic multilingual pretraining data for Indic languages, where we construct a large-scale synthetic dataset BhashaKritika, comprising 540B tokens using 5 different techniques for 10 languages. We explore the impact of grounding generation in documents, personas, and topics. We analyze how language choice, both in the prompt instructions and document grounding, affects data quality, and we compare translations of English content with native generation in Indic languages. To support scalable and language-sensitive evaluation, we introduce a modular quality evaluation pipeline that integrates script and language detection, metadata consistency checks, n-gram repetition analysis, and perplexity-based filtering using KenLM models. Our framework enables robust quality control across diverse scripts and linguistic contexts. Empirical results through model runs reveal key trade-offs in generation strategies and highlight best practices for constructing effective multilingual corpora.
Argus: Quality-Aware High-Throughput Text-to-Image Inference Serving System
Nov 10, 2025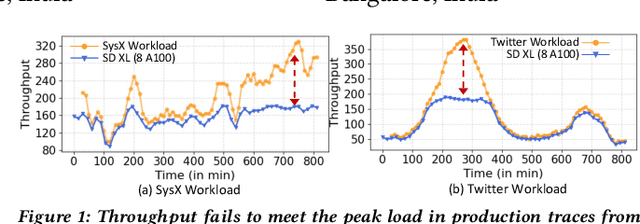

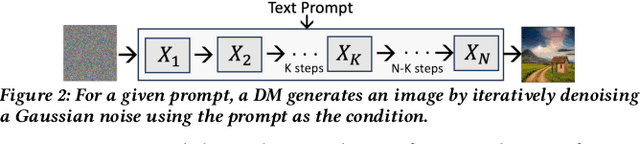
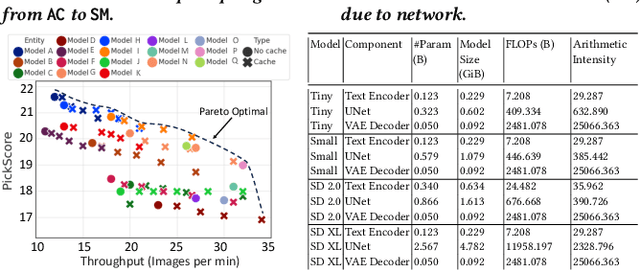
Text-to-image (T2I) models have gained significant popularity. Most of these are diffusion models with unique computational characteristics, distinct from both traditional small-scale ML models and large language models. They are highly compute-bound and use an iterative denoising process to generate images, leading to very high inference time. This creates significant challenges in designing a high-throughput system. We discovered that a large fraction of prompts can be served using faster, approximated models. However, the approximation setting must be carefully calibrated for each prompt to avoid quality degradation. Designing a high-throughput system that assigns each prompt to the appropriate model and compatible approximation setting remains a challenging problem. We present Argus, a high-throughput T2I inference system that selects the right level of approximation for each prompt to maintain quality while meeting throughput targets on a fixed-size cluster. Argus intelligently switches between different approximation strategies to satisfy both throughput and quality requirements. Overall, Argus achieves 10x fewer latency service-level objective (SLO) violations, 10% higher average quality, and 40% higher throughput compared to baselines on two real-world workload traces.
IndicVisionBench: Benchmarking Cultural and Multilingual Understanding in VLMs
Nov 06, 2025



Vision-language models (VLMs) have demonstrated impressive generalization across multimodal tasks, yet most evaluation benchmarks remain Western-centric, leaving open questions about their performance in culturally diverse and multilingual settings. To address this gap, we introduce IndicVisionBench, the first large-scale benchmark centered on the Indian subcontinent. Covering English and 10 Indian languages, our benchmark spans 3 multimodal tasks, including Optical Character Recognition (OCR), Multimodal Machine Translation (MMT), and Visual Question Answering (VQA), covering 6 kinds of question types. Our final benchmark consists of a total of ~5K images and 37K+ QA pairs across 13 culturally grounded topics. In addition, we release a paired parallel corpus of annotations across 10 Indic languages, creating a unique resource for analyzing cultural and linguistic biases in VLMs. We evaluate a broad spectrum of 8 models, from proprietary closed-source systems to open-weights medium and large-scale models. Our experiments reveal substantial performance gaps, underscoring the limitations of current VLMs in culturally diverse contexts. By centering cultural diversity and multilinguality, IndicVisionBench establishes a reproducible evaluation framework that paves the way for more inclusive multimodal research.
Seeing Straight: Document Orientation Detection for Efficient OCR
Nov 06, 2025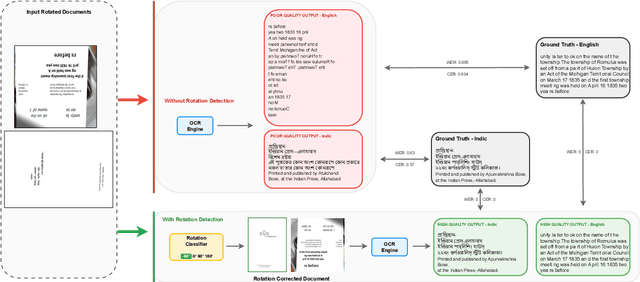



Despite significant advances in document understanding, determining the correct orientation of scanned or photographed documents remains a critical pre-processing step in the real world settings. Accurate rotation correction is essential for enhancing the performance of downstream tasks such as Optical Character Recognition (OCR) where misalignment commonly arises due to user errors, particularly incorrect base orientations of the camera during capture. In this study, we first introduce OCR-Rotation-Bench (ORB), a new benchmark for evaluating OCR robustness to image rotations, comprising (i) ORB-En, built from rotation-transformed structured and free-form English OCR datasets, and (ii) ORB-Indic, a novel multilingual set spanning 11 Indic mid to low-resource languages. We also present a fast, robust and lightweight rotation classification pipeline built on the vision encoder of Phi-3.5-Vision model with dynamic image cropping, fine-tuned specifically for 4-class rotation task in a standalone fashion. Our method achieves near-perfect 96% and 92% accuracy on identifying the rotations respectively on both the datasets. Beyond classification, we demonstrate the critical role of our module in boosting OCR performance: closed-source (up to 14%) and open-weights models (up to 4x) in the simulated real-world setting.