 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Extraction of Clinical Event Contextual Properties from Electronic Health Records: A Comparative Study
Paper and Code
Aug 30, 2024
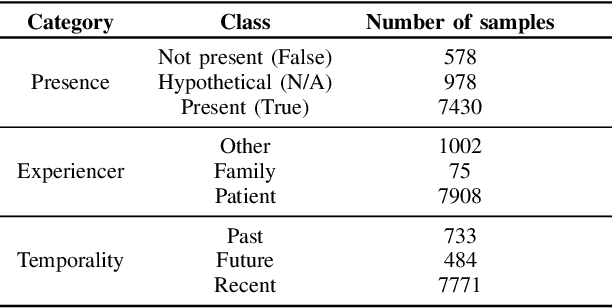
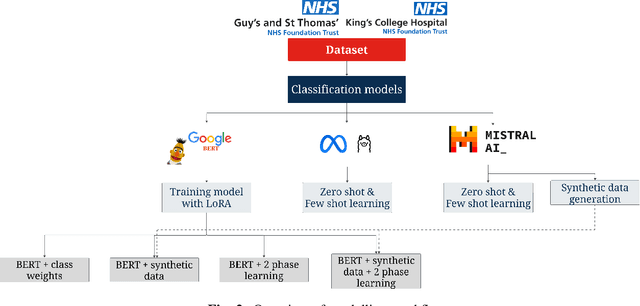
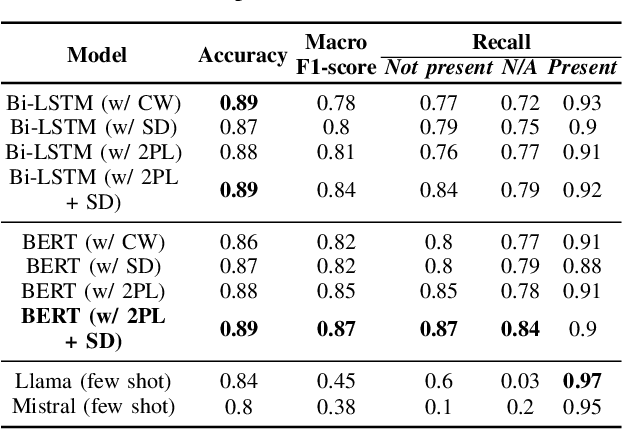
Electronic Health Records are large repositories of valuable clinical data, with a significant portion stored in unstructured text format. This textual data includes clinical events (e.g., disorders, symptoms, findings, medications and procedures) in context that if extracted accurately at scale can unlock valuable downstream applications such as disease prediction. Using an existing Named Entity Recognition and Linking methodology, MedCAT, these identified concepts need to be further classified (contextualised) for their relevance to the patient, and their temporal and negated status for example, to be useful downstream. This study performs a comparative analysis of various natural language models for medical text classification. Extensive experimentation reveals the effectiveness of transformer-based language models, particularly BERT. When combined with class imbalance mitigation techniques, BERT outperforms Bi-LSTM models by up to 28% and the baseline BERT model by up to 16% for recall of the minority classes. The method has been implemented as part of CogStack/MedCAT framework and made available to the community for further research.