 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndicVisionBench: Benchmarking Cultural and Multilingual Understanding in VLMs
Nov 06, 2025



Vision-language models (VLMs) have demonstrated impressive generalization across multimodal tasks, yet most evaluation benchmarks remain Western-centric, leaving open questions about their performance in culturally diverse and multilingual settings. To address this gap, we introduce IndicVisionBench, the first large-scale benchmark centered on the Indian subcontinent. Covering English and 10 Indian languages, our benchmark spans 3 multimodal tasks, including Optical Character Recognition (OCR), Multimodal Machine Translation (MMT), and Visual Question Answering (VQA), covering 6 kinds of question types. Our final benchmark consists of a total of ~5K images and 37K+ QA pairs across 13 culturally grounded topics. In addition, we release a paired parallel corpus of annotations across 10 Indic languages, creating a unique resource for analyzing cultural and linguistic biases in VLMs. We evaluate a broad spectrum of 8 models, from proprietary closed-source systems to open-weights medium and large-scale models. Our experiments reveal substantial performance gaps, underscoring the limitations of current VLMs in culturally diverse contexts. By centering cultural diversity and multilinguality, IndicVisionBench establishes a reproducible evaluation framework that paves the way for more inclusive multimodal research.
Seeing Straight: Document Orientation Detection for Efficient OCR
Nov 06, 2025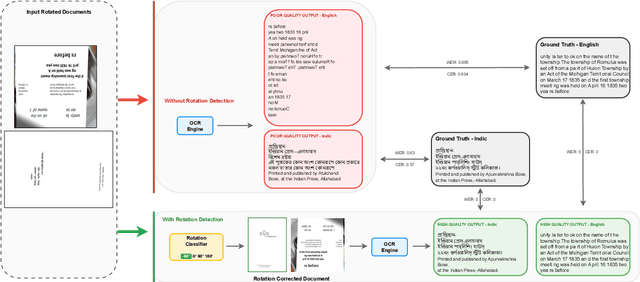



Despite significant advances in document understanding, determining the correct orientation of scanned or photographed documents remains a critical pre-processing step in the real world settings. Accurate rotation correction is essential for enhancing the performance of downstream tasks such as Optical Character Recognition (OCR) where misalignment commonly arises due to user errors, particularly incorrect base orientations of the camera during capture. In this study, we first introduce OCR-Rotation-Bench (ORB), a new benchmark for evaluating OCR robustness to image rotations, comprising (i) ORB-En, built from rotation-transformed structured and free-form English OCR datasets, and (ii) ORB-Indic, a novel multilingual set spanning 11 Indic mid to low-resource languages. We also present a fast, robust and lightweight rotation classification pipeline built on the vision encoder of Phi-3.5-Vision model with dynamic image cropping, fine-tuned specifically for 4-class rotation task in a standalone fashion. Our method achieves near-perfect 96% and 92% accuracy on identifying the rotations respectively on both the datasets. Beyond classification, we demonstrate the critical role of our module in boosting OCR performance: closed-source (up to 14%) and open-weights models (up to 4x) in the simulated real-world setting.
Chitranuvad: Adapting Multi-Lingual LLMs for Multimodal Translation
Feb 27, 2025In this work, we provide the system description of our submission as part of the English to Lowres Multimodal Translation Task at the Workshop on Asian Translation (WAT2024). We introduce Chitranuvad, a multimodal model that effectively integrates Multilingual LLM and a vision module for Multimodal Translation. Our method uses a ViT image encoder to extract visual representations as visual token embeddings which are projected to the LLM space by an adapter layer and generates translation in an autoregressive fashion. We participated in all the three tracks (Image Captioning, Text only and Multimodal translation tasks) for Indic languages (ie. English translation to Hindi, Bengali and Malyalam) and achieved SOTA results for Hindi in all of them on the Challenge set while remaining competitive for the other languages in the shared task.
Chitrarth: Bridging Vision and Language for a Billion People
Feb 21, 2025Recent multimodal foundation models are primarily trained on English or high resource European language data, which hinders their applicability to other medium and low-resource languages. To address this limitation, we introduce Chitrarth (Chitra: Image; Artha: Meaning), an inclusive Vision-Language Model (VLM), specifically targeting the rich linguistic diversity and visual reasoning across 10 prominent Indian languages. Our model effectively integrates a state-of-the-art (SOTA) multilingual Large Language Model (LLM) with a vision module, primarily trained on multilingual image-text data. Furthermore, we also introduce BharatBench, a comprehensive framework for evaluating VLMs across various Indian languages, ultimately contributing to more diverse and effective AI systems. Our model achieves SOTA results for benchmarks across low resource languages while retaining its efficiency in English. Through our research, we aim to set new benchmarks in multilingual-multimodal capabilities, offering substantial improvements over existing models and establishing a foundation to facilitate future advancements in this arena.
A Tale of Color Variants: Representation and Self-Supervised Learning in Fashion E-Commerce
Dec 06, 2021

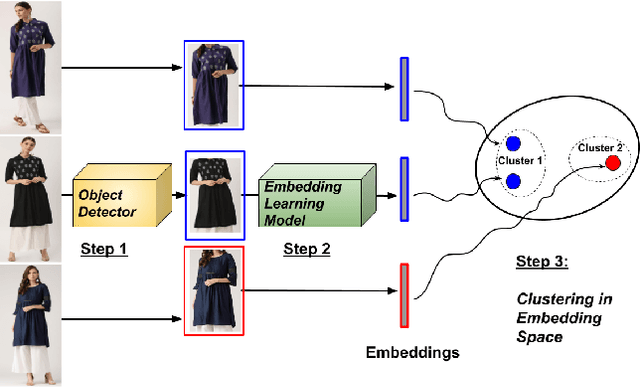
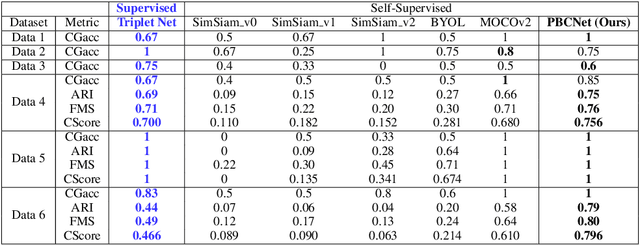
In this paper, we address a crucial problem in fashion e-commerce (with respect to customer experience, as well as revenue): color variants identification, i.e., identifying fashion products that match exactly in their design (or style), but only to differ in their color. We propose a generic framework, that leverages deep visual Representation Learning at its heart, to address this problem for our fashion e-commerce platform. Our framework could be trained with supervisory signals in the form of triplets, that are obtained manually. However, it is infeasible to obtain manual annotations for the entire huge collection of data usually present in fashion e-commerce platforms, such as ours, while capturing all the difficult corner cases. But, to our rescue, interestingly we observed that this crucial problem in fashion e-commerce could also be solved by simple color jitter based image augmentation, that recently became widely popular in the contrastive Self-Supervised Learning (SSL) literature, that seeks to learn visual representations without using manual labels. This naturally led to a question in our mind: Could we leverage SSL in our use-case, and still obtain comparable performance to our supervised framework? The answer is, Yes! because, color variant fashion objects are nothing but manifestations of a style, in different colors, and a model trained to be invariant to the color (with, or without supervision), should be able to recognize this! This is what the paper further demonstrates, both qualitatively, and quantitatively, while evaluating a couple of state-of-the-art SSL techniques, and also proposing a novel method.
Color Variants Identification via Contrastive Self-Supervised Representation Learning
Apr 17, 2021
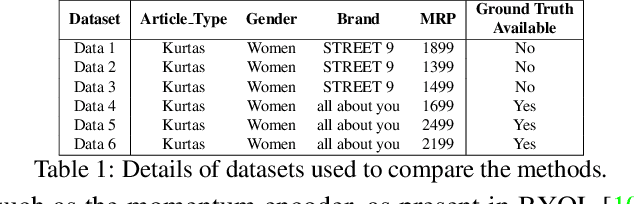
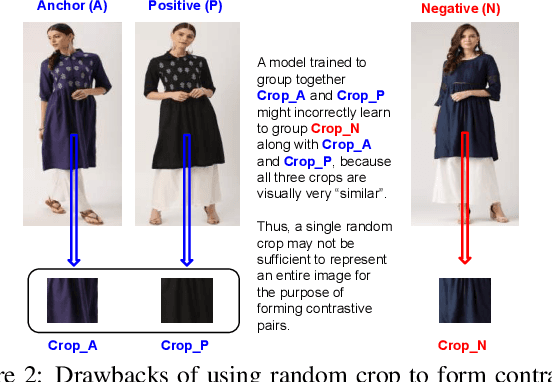
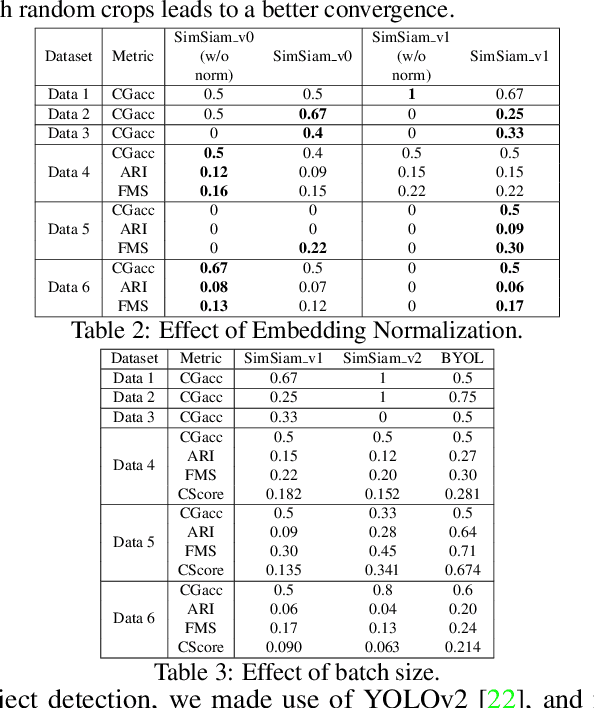
In this paper, we utilize deep visual Representation Learning to address the problem of identification of color variants. In particular, we address color variants identification in fashion products, which refers to the problem of identifying fashion products that match exactly in their design (or style), but only to differ in their color. Firstly, we solve this problem by obtaining manual annotations depicting whether two products are color variants. Having obtained such annotations, we train a triplet loss based neural network model to learn deep representations of fashion products. However, for large scale real-world industrial datasets such as addressed in our paper, it is infeasible to obtain annotations for the entire dataset. Hence, we rather explore the use of self-supervised learning to obtain the representations. We observed that existing state-of-the-art self-supervised methods do not perform competitive against the supervised version of our color variants model. To address this, we additionally propose a novel contrastive loss based self-supervised color variants model. Intuitively, our model focuses on different parts of an object in a fixed manner, rather than focusing on random crops typically used for data augmentation in existing methods. We evaluate our method both quantitatively and qualitatively to show that it outperforms existing self-supervised methods, and at times, the supervised model as well.
Attr2Style: A Transfer Learning Approach for Inferring Fashion Styles via Apparel Attributes
Aug 26, 2020
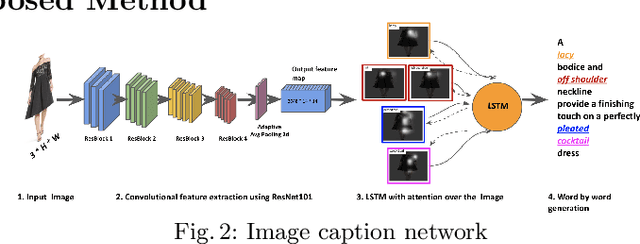

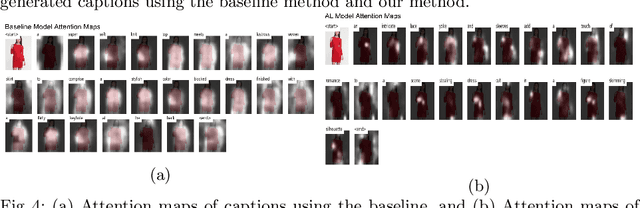
Popular fashion e-commerce platforms mostly provide details about low-level attributes of an apparel (for example, neck type, dress length, collar type, print etc) on their product detail pages. However, customers usually prefer to buy apparels based on their style information, or simply put, occasion (for example, party wear, sports wear, casual wear etc). Application of a supervised image-captioning model to generate style-based image captions is limited because obtaining ground-truth annotations in the form of style-based captions is difficult. This is because annotating style-based captions requires a certain amount of fashion domain expertise, and also adds to the costs and manual effort. On the contrary, low-level attribute based annotations are much more easily available. To address this issue, we propose a transfer-learning based image captioning model that is trained on a source dataset with sufficient attribute-based ground-truth captions, and used to predict style-based captions on a target dataset. The target dataset has only a limited amount of images with style-based ground-truth captions. The main motivation of our approach comes from the fact that most often there are correlations among the low-level attributes and the higher-level styles for an apparel. We leverage this fact and train our model in an encoder-decoder based framework using attention mechanism. In particular, the encoder of the model is first trained on the source dataset to obtain latent representations capturing the low-level attributes. The trained model is fine-tuned to generate style-based captions for the target dataset. To highlight the effectiveness of our method, we qualitatively demonstrate that the captions generated by our approach are close to the actual style information for the evaluated apparels.
Buy Me That Look: An Approach for Recommending Similar Fashion Products
Aug 26, 2020
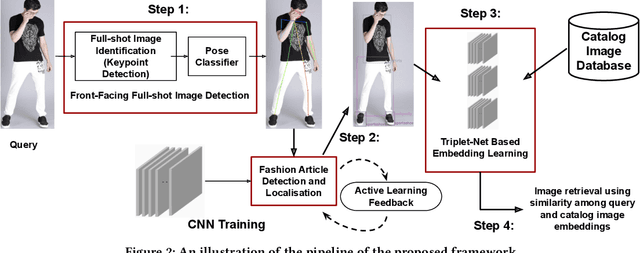
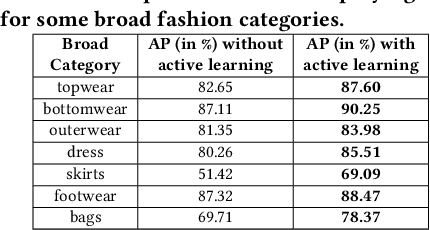

The recent proliferation of numerous fashion e-commerce platforms has led to a surge in online shopping of fashion products. Fashion being the dominant aspect in online retail sales, demands for efficient and effective fashion products recommendation systems that could boost revenue, improve customer experience and engagement. In this paper, we focus on the problem of similar fashion item recommendation for multiple fashion items. Given a Product Display Page for a fashion item in an online e-commerce platform, we identify the images with a full-shot look, i.e., the one with a full human model wearing the fashion item. While the majority of existing works in this domain focus on retrieving similar products corresponding to a single item present in a query, we focus on the retrieval of multiple fashion items at once. This is an important problem because while a user might have searched for a particular primary article type (e.g., men's shorts), the human model in the full-shot look image would usually be wearing secondary fashion items as well (e.g., t-shirts, shoes etc). Upon looking at the full-shot look image in the PDP, the user might also be interested in viewing similar items for the secondary article types. To address this need, we use human keypoint detection to first identify the fullshot images, from which we subsequently select the front facing ones. An article detection and localisation module pretrained on a large-dataset is then used to identify different articles in the image. The detected articles and the catalog database images are then represented in a common embedding space, for the purpose of similarity based retrieval. We make use of a triplet-based neural network to obtain the embeddings. Our embedding network by virtue of an active-learning component achieves further improvements in the retrieval performance.
Teaching DNNs to design fast fashion
Jul 03, 2019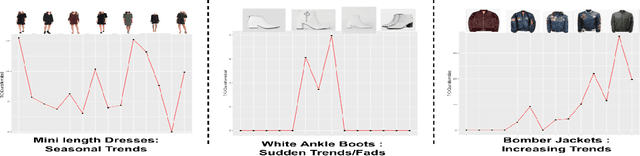
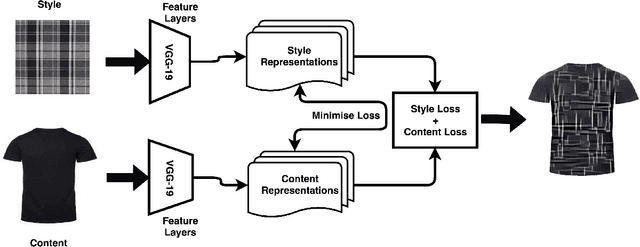
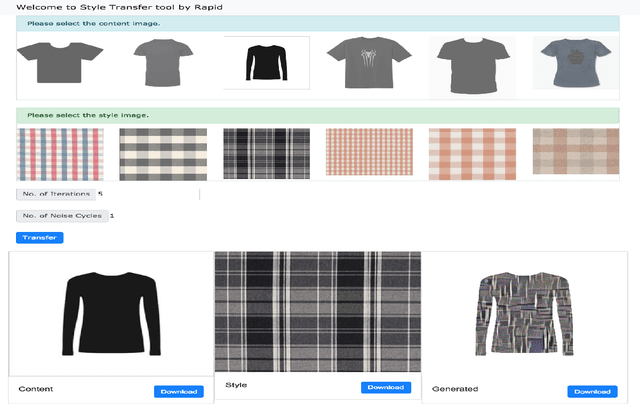

$ $"Fast Fashion" spearheads the biggest disruption in fashion that enabled to engineer resilient supply chains to quickly respond to changing fashion trends. The conventional design process in commercial manufacturing is often fed through "trends" or prevailing modes of dressing around the world that indicate sudden interest in a new form of expression, cyclic patterns, and popular modes of expression for a given time frame. In this work, we propose a fully automated system to explore, detect, and finally synthesize trends in fashion into design elements by designing representative prototypes of apparel given time series signals generated from social media feeds. Our system is envisioned to be the first step in design of Fast Fashion where the production cycle for clothes from design inception to manufacturing is meant to be rapid and responsive to current "trends". It also works to reduce wastage in fashion production by taking in customer feedback on sellability at the time of design generation. We also provide an interface wherein the designers can play with multiple trending styles in fashion and visualize designs as interpolations of elements of these styles. We aim to aid the creative process through generating interesting and inspiring combinations for a designer to mull by running them through her key customers.