 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperBox: A Supervised Approach for Hypernym Discovery using Box Embeddings
Apr 05, 2022

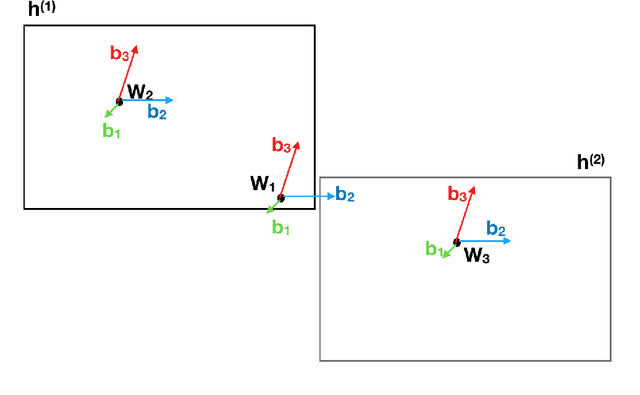
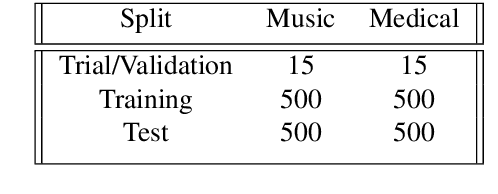
Hypernymy plays a fundamental role in many AI tasks like taxonomy learning, ontology learning, etc. This has motivated the development of many automatic identification methods for extracting this relation, most of which rely on word distribution. We present a novel model HyperBox to learn box embeddings for hypernym discovery. Given an input term, HyperBox retrieves its suitable hypernym from a target corpus. For this task, we use the dataset published for SemEval 2018 Shared Task on Hypernym Discovery. We compare the performance of our model on two specific domains of knowledge: medical and music. Experimentally, we show that our model outperforms existing methods on the majority of the evaluation metrics. Moreover, our model generalize well over unseen hypernymy pairs using only a small set of training data.
A Tale of Color Variants: Representation and Self-Supervised Learning in Fashion E-Commerce
Dec 06, 2021

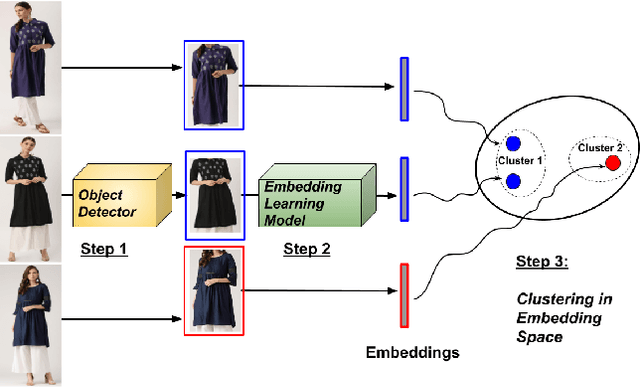
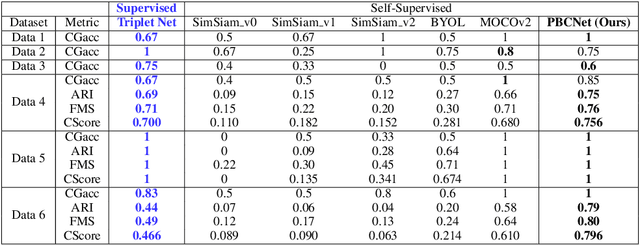
In this paper, we address a crucial problem in fashion e-commerce (with respect to customer experience, as well as revenue): color variants identification, i.e., identifying fashion products that match exactly in their design (or style), but only to differ in their color. We propose a generic framework, that leverages deep visual Representation Learning at its heart, to address this problem for our fashion e-commerce platform. Our framework could be trained with supervisory signals in the form of triplets, that are obtained manually. However, it is infeasible to obtain manual annotations for the entire huge collection of data usually present in fashion e-commerce platforms, such as ours, while capturing all the difficult corner cases. But, to our rescue, interestingly we observed that this crucial problem in fashion e-commerce could also be solved by simple color jitter based image augmentation, that recently became widely popular in the contrastive Self-Supervised Learning (SSL) literature, that seeks to learn visual representations without using manual labels. This naturally led to a question in our mind: Could we leverage SSL in our use-case, and still obtain comparable performance to our supervised framework? The answer is, Yes! because, color variant fashion objects are nothing but manifestations of a style, in different colors, and a model trained to be invariant to the color (with, or without supervision), should be able to recognize this! This is what the paper further demonstrates, both qualitatively, and quantitatively, while evaluating a couple of state-of-the-art SSL techniques, and also proposing a novel method.
Color Variants Identification via Contrastive Self-Supervised Representation Learning
Apr 17, 2021
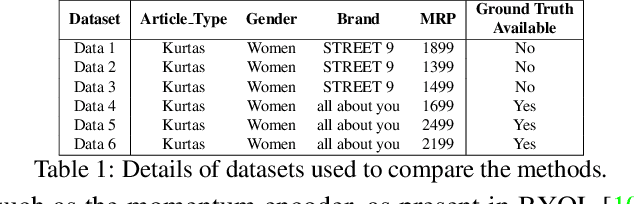
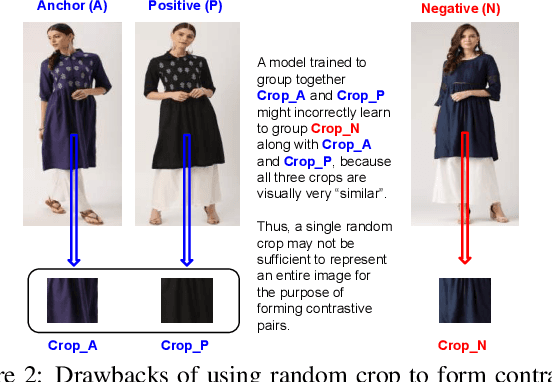
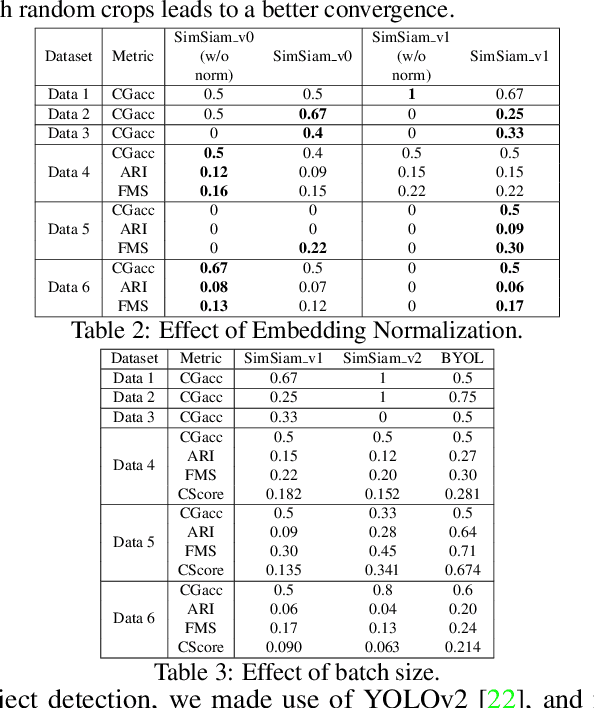
In this paper, we utilize deep visual Representation Learning to address the problem of identification of color variants. In particular, we address color variants identification in fashion products, which refers to the problem of identifying fashion products that match exactly in their design (or style), but only to differ in their color. Firstly, we solve this problem by obtaining manual annotations depicting whether two products are color variants. Having obtained such annotations, we train a triplet loss based neural network model to learn deep representations of fashion products. However, for large scale real-world industrial datasets such as addressed in our paper, it is infeasible to obtain annotations for the entire dataset. Hence, we rather explore the use of self-supervised learning to obtain the representations. We observed that existing state-of-the-art self-supervised methods do not perform competitive against the supervised version of our color variants model. To address this, we additionally propose a novel contrastive loss based self-supervised color variants model. Intuitively, our model focuses on different parts of an object in a fixed manner, rather than focusing on random crops typically used for data augmentation in existing methods. We evaluate our method both quantitatively and qualitatively to show that it outperforms existing self-supervised methods, and at times, the supervised model as well.
Buy Me That Look: An Approach for Recommending Similar Fashion Products
Aug 26, 2020
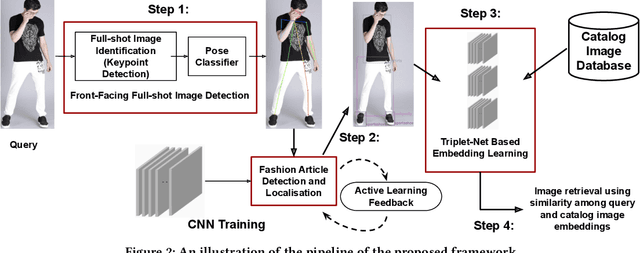
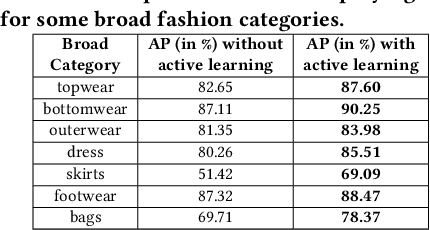

The recent proliferation of numerous fashion e-commerce platforms has led to a surge in online shopping of fashion products. Fashion being the dominant aspect in online retail sales, demands for efficient and effective fashion products recommendation systems that could boost revenue, improve customer experience and engagement. In this paper, we focus on the problem of similar fashion item recommendation for multiple fashion items. Given a Product Display Page for a fashion item in an online e-commerce platform, we identify the images with a full-shot look, i.e., the one with a full human model wearing the fashion item. While the majority of existing works in this domain focus on retrieving similar products corresponding to a single item present in a query, we focus on the retrieval of multiple fashion items at once. This is an important problem because while a user might have searched for a particular primary article type (e.g., men's shorts), the human model in the full-shot look image would usually be wearing secondary fashion items as well (e.g., t-shirts, shoes etc). Upon looking at the full-shot look image in the PDP, the user might also be interested in viewing similar items for the secondary article types. To address this need, we use human keypoint detection to first identify the fullshot images, from which we subsequently select the front facing ones. An article detection and localisation module pretrained on a large-dataset is then used to identify different articles in the image. The detected articles and the catalog database images are then represented in a common embedding space, for the purpose of similarity based retrieval. We make use of a triplet-based neural network to obtain the embeddings. Our embedding network by virtue of an active-learning component achieves further improvements in the retrieval performance.
Neural Machine Translation with Recurrent Highway Networks
Apr 28, 2019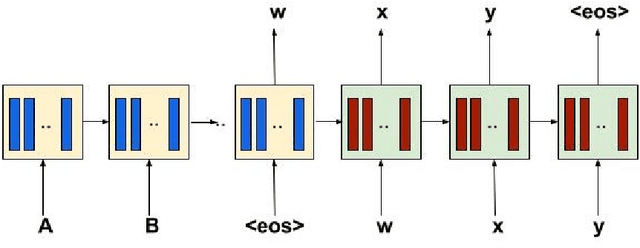
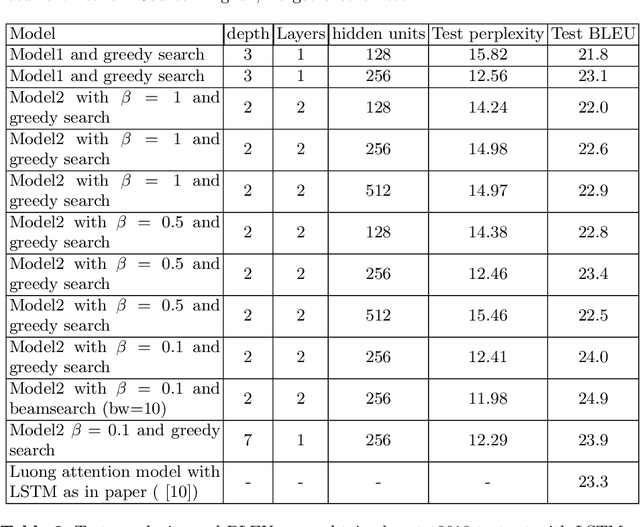
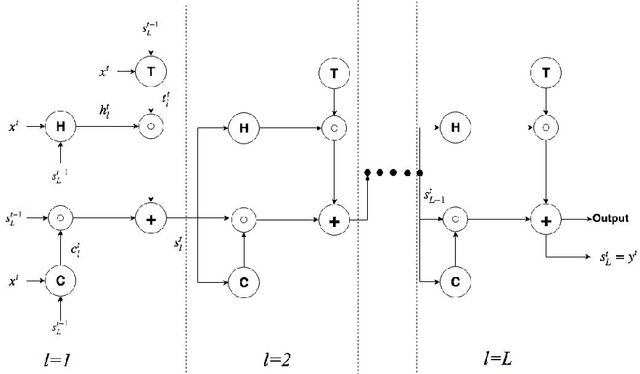
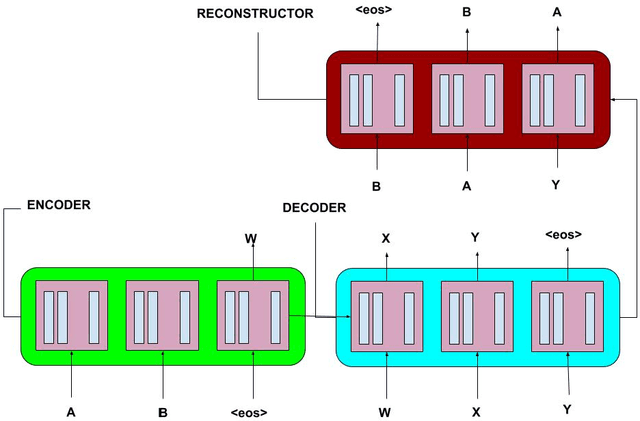
Recurrent Neural Networks have lately gained a lot of popularity in language modelling tasks, especially in neural machine translation(NMT). Very recent NMT models are based on Encoder-Decoder, where a deep LSTM based encoder is used to project the source sentence to a fixed dimensional vector and then another deep LSTM decodes the target sentence from the vector. However there has been very little work on exploring architectures that have more than one layer in space(i.e. in each time step). This paper examines the effectiveness of the simple Recurrent Highway Networks(RHN) in NMT tasks. The model uses Recurrent Highway Neural Network in encoder and decoder, with attention .We also explore the reconstructor model to improve adequacy. We demonstrate the effectiveness of all three approaches on the IWSLT English-Vietnamese dataset. We see that RHN performs on par with LSTM based models and even better in some cases.We see that deep RHN models are easy to train compared to deep LSTM based models because of highway connections. The paper also investigates the effects of increasing recurrent depth in each time step.
* International Conference on Mining Intelligence and Knowledge Exploration