 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Bad Ground Truth in Supervised Machine Learning based Crop Classification: A Multi-Level Framework with Sentinel-2 Images
Mar 14, 2025
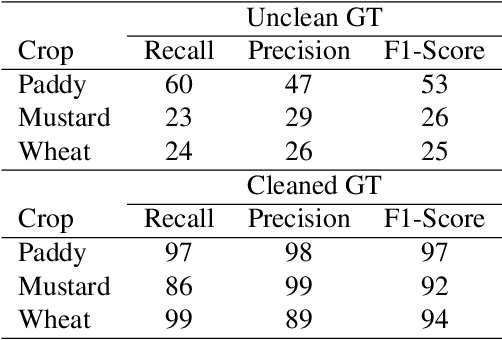
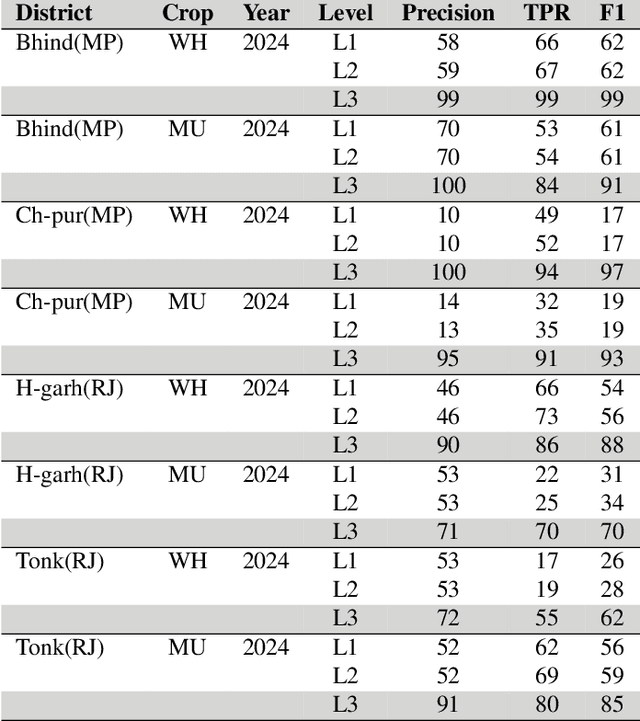
In agricultural management, precise Ground Truth (GT) data is crucial for accurate Machine Learning (ML) based crop classification. Yet, issues like crop mislabeling and incorrect land identification are common. We propose a multi-level GT cleaning framework while utilizing multi-temporal Sentinel-2 data to address these issues. Specifically, this framework utilizes generating embeddings for farmland, clustering similar crop profiles, and identification of outliers indicating GT errors. We validated clusters with False Colour Composite (FCC) checks and used distance-based metrics to scale and automate this verification process. The importance of cleaning the GT data became apparent when the models were trained on the clean and unclean data. For instance, when we trained a Random Forest model with the clean GT data, we achieved upto 70\% absolute percentage points higher for the F1 score metric. This approach advances crop classification methodologies, with potential for applications towards improving loan underwriting and agricultural decision-making.
Application of Zone Method based Machine Learning and Physics-Informed Neural Networks in Reheating Furnaces
Aug 30, 2023Despite the high economic relevance of Foundation Industries, certain components like Reheating furnaces within their manufacturing chain are energy-intensive. Notable energy consumption reduction could be obtained by reducing the overall heating time in furnaces. Computer-integrated Machine Learning (ML) and Artificial Intelligence (AI) powered control systems in furnaces could be enablers in achieving the Net-Zero goals in Foundation Industries for sustainable manufacturing. In this work, due to the infeasibility of achieving good quality data in scenarios like reheating furnaces, classical Hottel's zone method based computational model has been used to generate data for ML and Deep Learning (DL) based model training via regression. It should be noted that the zone method provides an elegant way to model the physical phenomenon of Radiative Heat Transfer (RHT), the dominating heat transfer mechanism in high-temperature processes inside heating furnaces. Using this data, an extensive comparison among a wide range of state-of-the-art, representative ML and DL methods has been made against their temperature prediction performances in varying furnace environments. Owing to their holistic balance among inference times and model performance, DL stands out among its counterparts. To further enhance the Out-Of-Distribution (OOD) generalization capability of the trained DL models, we propose a Physics-Informed Neural Network (PINN) by incorporating prior physical knowledge using a set of novel Energy-Balance regularizers. Our setup is a generic framework, is geometry-agnostic of the 3D structure of the underlying furnace, and as such could accommodate any standard ML regression model, to serve as a Digital Twin of the underlying physical processes, for transitioning Foundation Industries towards Industry 4.0.
Fuse and Attend: Generalized Embedding Learning for Art and Sketches
Aug 20, 2022


While deep Embedding Learning approaches have witnessed widespread success in multiple computer vision tasks, the state-of-the-art methods for representing natural images need not necessarily perform well on images from other domains, such as paintings, cartoons, and sketch. This is because of the huge shift in the distribution of data from across these domains, as compared to natural images. Domains like sketch often contain sparse informative pixels. However, recognizing objects in such domains is crucial, given multiple relevant applications leveraging such data, for instance, sketch to image retrieval. Thus, achieving an Embedding Learning model that could perform well across multiple domains is not only challenging, but plays a pivotal role in computer vision. To this end, in this paper, we propose a novel Embedding Learning approach with the goal of generalizing across different domains. During training, given a query image from a domain, we employ gated fusion and attention to generate a positive example, which carries a broad notion of the semantics of the query object category (from across multiple domains). By virtue of Contrastive Learning, we pull the embeddings of the query and positive, in order to learn a representation which is robust across domains. At the same time, to teach the model to be discriminative against examples from different semantic categories (across domains), we also maintain a pool of negative embeddings (from different categories). We show the prowess of our method using the DomainBed framework, on the popular PACS (Photo, Art painting, Cartoon, and Sketch) dataset.
Multispectral Satellite Data Classification using Soft Computing Approach
Mar 21, 2022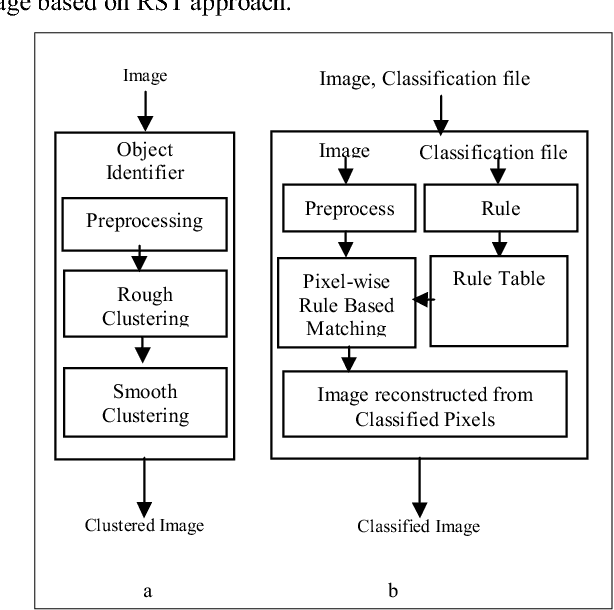

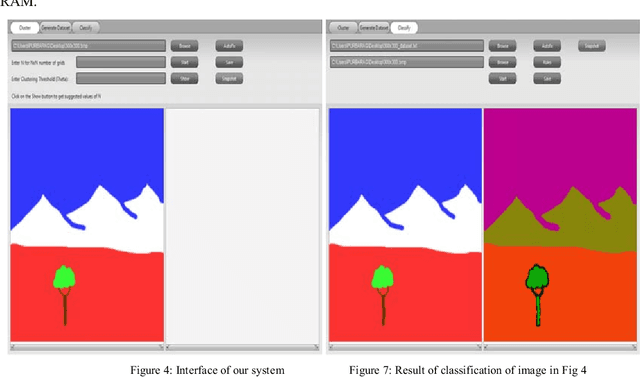

A satellite image is a remotely sensed image data, where each pixel represents a specific location on earth. The pixel value recorded is the reflection radiation from the earth's surface at that location. Multispectral images are those that capture image data at specific frequencies across the electromagnetic spectrum as compared to Panchromatic images which are sensitive to all wavelength of visible light. Because of the high resolution and high dimensions of these images, they create difficulties for clustering techniques to efficiently detect clusters of different sizes, shapes and densities as a trade off for fast processing time. In this paper we propose a grid-density based clustering technique for identification of objects. We also introduce an approach to classify a satellite image data using a rule induction based machine learning algorithm. The object identification and classification methods have been validated using several synthetic and benchmark datasets.
A Tale of Color Variants: Representation and Self-Supervised Learning in Fashion E-Commerce
Dec 06, 2021

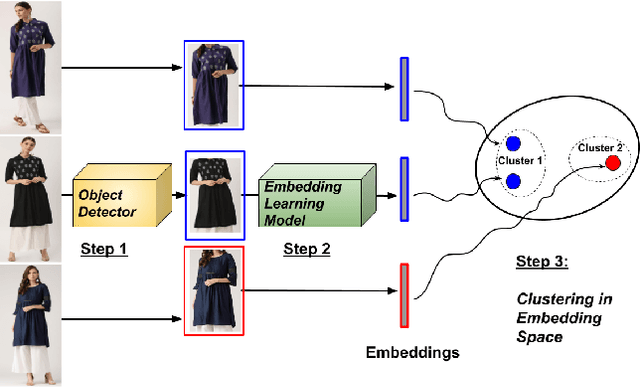
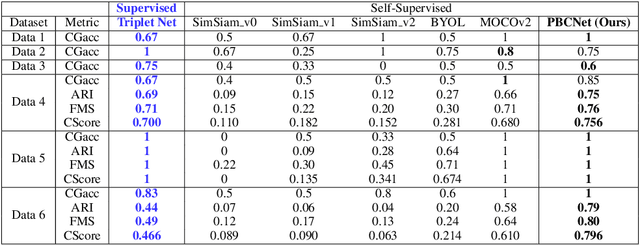
In this paper, we address a crucial problem in fashion e-commerce (with respect to customer experience, as well as revenue): color variants identification, i.e., identifying fashion products that match exactly in their design (or style), but only to differ in their color. We propose a generic framework, that leverages deep visual Representation Learning at its heart, to address this problem for our fashion e-commerce platform. Our framework could be trained with supervisory signals in the form of triplets, that are obtained manually. However, it is infeasible to obtain manual annotations for the entire huge collection of data usually present in fashion e-commerce platforms, such as ours, while capturing all the difficult corner cases. But, to our rescue, interestingly we observed that this crucial problem in fashion e-commerce could also be solved by simple color jitter based image augmentation, that recently became widely popular in the contrastive Self-Supervised Learning (SSL) literature, that seeks to learn visual representations without using manual labels. This naturally led to a question in our mind: Could we leverage SSL in our use-case, and still obtain comparable performance to our supervised framework? The answer is, Yes! because, color variant fashion objects are nothing but manifestations of a style, in different colors, and a model trained to be invariant to the color (with, or without supervision), should be able to recognize this! This is what the paper further demonstrates, both qualitatively, and quantitatively, while evaluating a couple of state-of-the-art SSL techniques, and also proposing a novel method.
Seeing BDD100K in dark: Single-Stage Night-time Object Detection via Continual Fourier Contrastive Learning
Dec 06, 2021

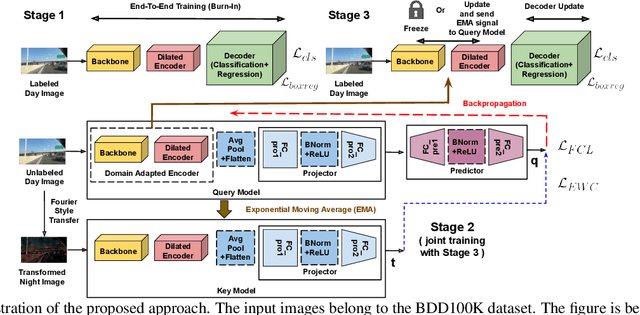
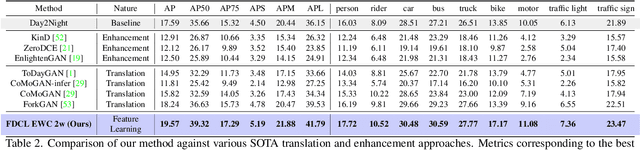
Despite tremendous improvements in state-of-the-art object detectors, addressing object detection in the night-time has been studied only sparsely, that too, via non-uniform evaluation protocols among the limited available papers. In addition to the lack of methods to address this problem, there was also a lack of an adequately large benchmark dataset to study night-time object detection. Recently, the large scale BDD100K was introduced, which, in our opinion, should be chosen as the benchmark, to kickstart research in this area. Now, coming to the methods, existing approaches (limited in number), are mainly either generative image translation based, or image enhancement/ illumination based, neither of which is natural, conforming to how humans see objects in the night time (by focusing on object contours). In this paper, we bridge these 3 gaps: 1. Lack of an uniform evaluation protocol (using a single-stage detector, due to its efficacy, and efficiency), 2. Choice of dataset for benchmarking night-time object detection, and 3. A novel method to address the limitations of current alternatives. Our method leverages a Contrastive Learning based feature extractor, borrowing information from the frequency domain via Fourier transformation, and trained in a continual learning based fashion. The learned features when used for object detection (after fine-tuning the classification and regression layers), help achieve a new state-of-the-art empirical performance, comfortably outperforming an extensive number of competitors.
Semi-Supervised Metric Learning: A Deep Resurrection
May 10, 2021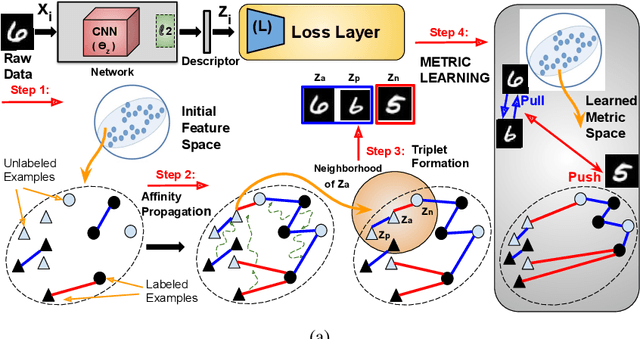
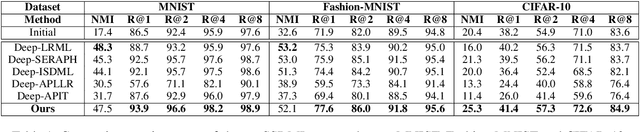
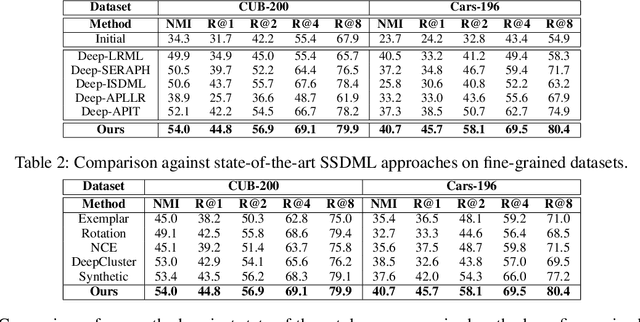
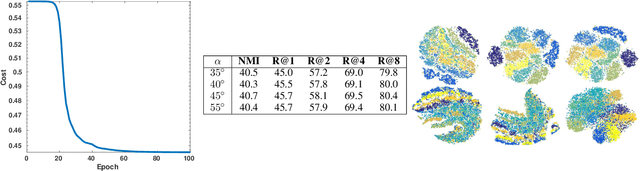
Distance Metric Learning (DML) seeks to learn a discriminative embedding where similar examples are closer, and dissimilar examples are apart. In this paper, we address the problem of Semi-Supervised DML (SSDML) that tries to learn a metric using a few labeled examples, and abundantly available unlabeled examples. SSDML is important because it is infeasible to manually annotate all the examples present in a large dataset. Surprisingly, with the exception of a few classical approaches that learn a linear Mahalanobis metric, SSDML has not been studied in the recent years, and lacks approaches in the deep SSDML scenario. In this paper, we address this challenging problem, and revamp SSDML with respect to deep learning. In particular, we propose a stochastic, graph-based approach that first propagates the affinities between the pairs of examples from labeled data, to that of the unlabeled pairs. The propagated affinities are used to mine triplet based constraints for metric learning. We impose orthogonality constraint on the metric parameters, as it leads to a better performance by avoiding a model collapse.
Color Variants Identification via Contrastive Self-Supervised Representation Learning
Apr 17, 2021
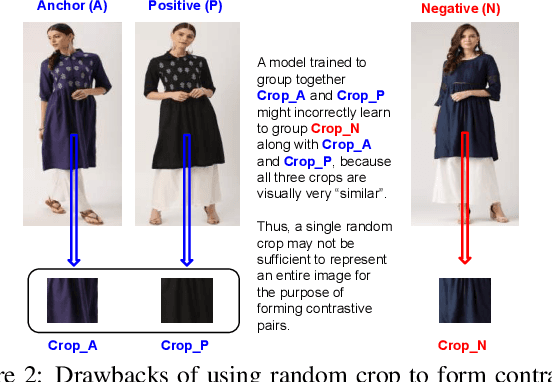
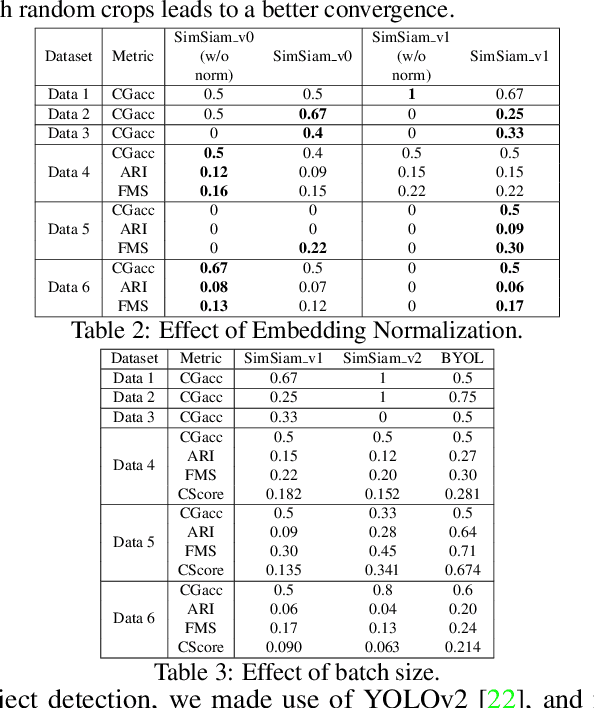
In this paper, we utilize deep visual Representation Learning to address the problem of identification of color variants. In particular, we address color variants identification in fashion products, which refers to the problem of identifying fashion products that match exactly in their design (or style), but only to differ in their color. Firstly, we solve this problem by obtaining manual annotations depicting whether two products are color variants. Having obtained such annotations, we train a triplet loss based neural network model to learn deep representations of fashion products. However, for large scale real-world industrial datasets such as addressed in our paper, it is infeasible to obtain annotations for the entire dataset. Hence, we rather explore the use of self-supervised learning to obtain the representations. We observed that existing state-of-the-art self-supervised methods do not perform competitive against the supervised version of our color variants model. To address this, we additionally propose a novel contrastive loss based self-supervised color variants model. Intuitively, our model focuses on different parts of an object in a fixed manner, rather than focusing on random crops typically used for data augmentation in existing methods. We evaluate our method both quantitatively and qualitatively to show that it outperforms existing self-supervised methods, and at times, the supervised model as well.
Attr2Style: A Transfer Learning Approach for Inferring Fashion Styles via Apparel Attributes
Aug 26, 2020
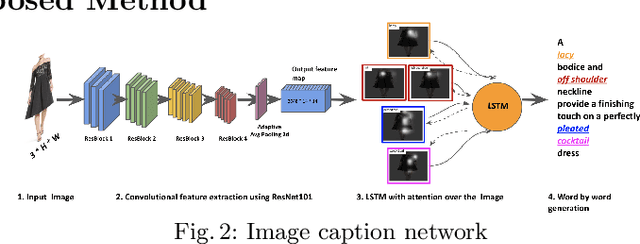

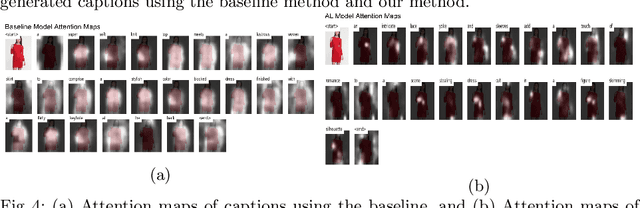
Popular fashion e-commerce platforms mostly provide details about low-level attributes of an apparel (for example, neck type, dress length, collar type, print etc) on their product detail pages. However, customers usually prefer to buy apparels based on their style information, or simply put, occasion (for example, party wear, sports wear, casual wear etc). Application of a supervised image-captioning model to generate style-based image captions is limited because obtaining ground-truth annotations in the form of style-based captions is difficult. This is because annotating style-based captions requires a certain amount of fashion domain expertise, and also adds to the costs and manual effort. On the contrary, low-level attribute based annotations are much more easily available. To address this issue, we propose a transfer-learning based image captioning model that is trained on a source dataset with sufficient attribute-based ground-truth captions, and used to predict style-based captions on a target dataset. The target dataset has only a limited amount of images with style-based ground-truth captions. The main motivation of our approach comes from the fact that most often there are correlations among the low-level attributes and the higher-level styles for an apparel. We leverage this fact and train our model in an encoder-decoder based framework using attention mechanism. In particular, the encoder of the model is first trained on the source dataset to obtain latent representations capturing the low-level attributes. The trained model is fine-tuned to generate style-based captions for the target dataset. To highlight the effectiveness of our method, we qualitatively demonstrate that the captions generated by our approach are close to the actual style information for the evaluated apparels.
Buy Me That Look: An Approach for Recommending Similar Fashion Products
Aug 26, 2020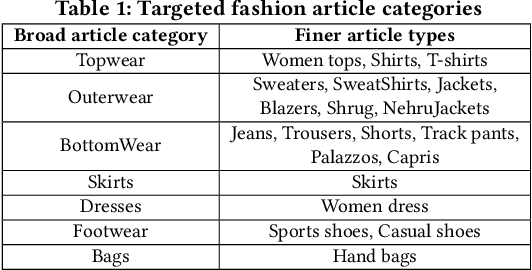
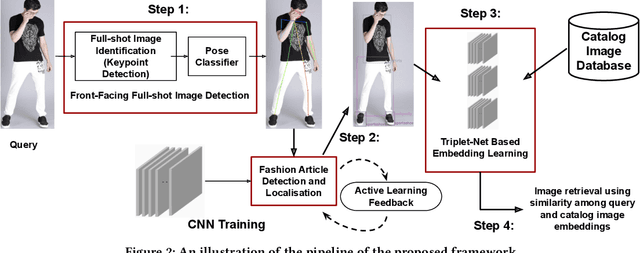
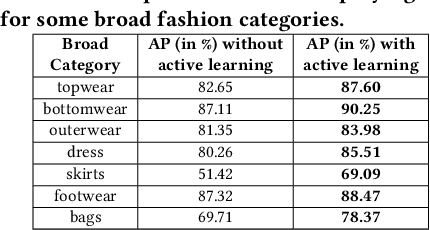

The recent proliferation of numerous fashion e-commerce platforms has led to a surge in online shopping of fashion products. Fashion being the dominant aspect in online retail sales, demands for efficient and effective fashion products recommendation systems that could boost revenue, improve customer experience and engagement. In this paper, we focus on the problem of similar fashion item recommendation for multiple fashion items. Given a Product Display Page for a fashion item in an online e-commerce platform, we identify the images with a full-shot look, i.e., the one with a full human model wearing the fashion item. While the majority of existing works in this domain focus on retrieving similar products corresponding to a single item present in a query, we focus on the retrieval of multiple fashion items at once. This is an important problem because while a user might have searched for a particular primary article type (e.g., men's shorts), the human model in the full-shot look image would usually be wearing secondary fashion items as well (e.g., t-shirts, shoes etc). Upon looking at the full-shot look image in the PDP, the user might also be interested in viewing similar items for the secondary article types. To address this need, we use human keypoint detection to first identify the fullshot images, from which we subsequently select the front facing ones. An article detection and localisation module pretrained on a large-dataset is then used to identify different articles in the image. The detected articles and the catalog database images are then represented in a common embedding space, for the purpose of similarity based retrieval. We make use of a triplet-based neural network to obtain the embeddings. Our embedding network by virtue of an active-learning component achieves further improvements in the retrieval performance.