 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Bad Ground Truth in Supervised Machine Learning based Crop Classification: A Multi-Level Framework with Sentinel-2 Images
Paper and Code
Mar 14, 2025
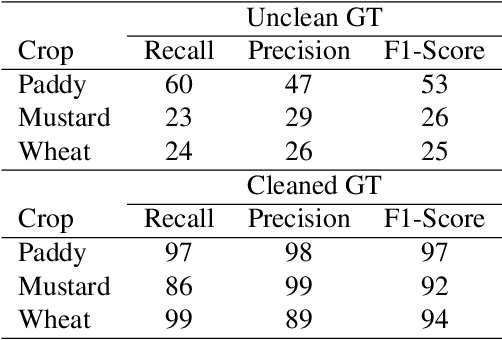
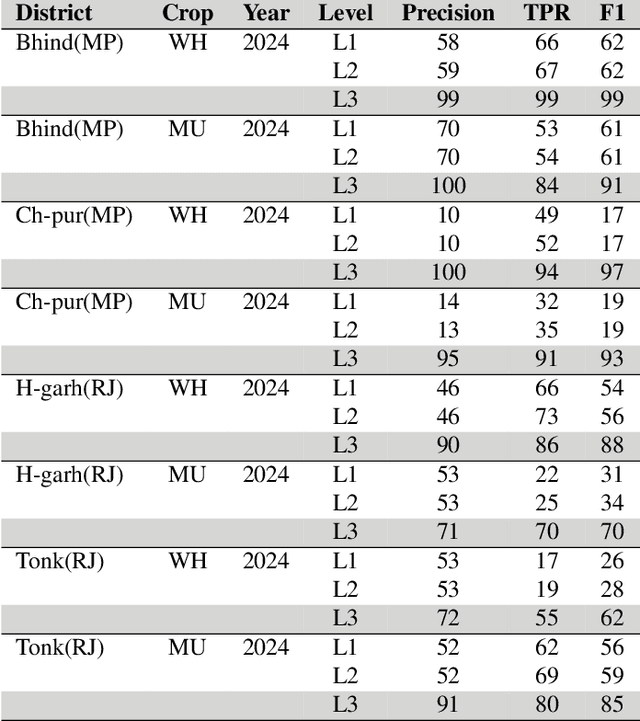
In agricultural management, precise Ground Truth (GT) data is crucial for accurate Machine Learning (ML) based crop classification. Yet, issues like crop mislabeling and incorrect land identification are common. We propose a multi-level GT cleaning framework while utilizing multi-temporal Sentinel-2 data to address these issues. Specifically, this framework utilizes generating embeddings for farmland, clustering similar crop profiles, and identification of outliers indicating GT errors. We validated clusters with False Colour Composite (FCC) checks and used distance-based metrics to scale and automate this verification process. The importance of cleaning the GT data became apparent when the models were trained on the clean and unclean data. For instance, when we trained a Random Forest model with the clean GT data, we achieved upto 70\% absolute percentage points higher for the F1 score metric. This approach advances crop classification methodologies, with potential for applications towards improving loan underwriting and agricultural decision-making.