 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearing Between the Lines: Unlocking the Reasoning Power of LLMs for Speech Evaluation
Jan 24, 2026Large Language Model (LLM) judges exhibit strong reasoning capabilities but are limited to textual content. This leaves current automatic Speech-to-Speech (S2S) evaluation methods reliant on opaque and expensive Audio Language Models (ALMs). In this work, we propose TRACE (Textual Reasoning over Audio Cues for Evaluation), a novel framework that enables LLM judges to reason over audio cues to achieve cost-efficient and human-aligned S2S evaluation. To demonstrate the strength of the framework, we first introduce a Human Chain-of-Thought (HCoT) annotation protocol to improve the diagnostic capability of existing judge benchmarks by separating evaluation into explicit dimensions: content (C), voice quality (VQ), and paralinguistics (P). Using this data, TRACE constructs a textual blueprint of inexpensive audio signals and prompts an LLM to render dimension-wise judgments, fusing them into an overall rating via a deterministic policy. TRACE achieves higher agreement with human raters than ALMs and transcript-only LLM judges while being significantly more cost-effective. We will release the HCoT annotations and the TRACE framework to enable scalable and human-aligned S2S evaluation.
Dimension-First Evaluation of Speech-to-Speech Models with Structured Acoustic Cues
Jan 20, 2026Large Language Model (LLM) judges exhibit strong reasoning capabilities but are limited to textual content. This leaves current automatic Speech-to-Speech (S2S) evaluation methods reliant on opaque and expensive Audio Language Models (ALMs). In this work, we propose TRACE (Textual Reasoning over Audio Cues for Evaluation), a novel framework that enables LLM judges to reason over audio cues to achieve cost-efficient and human-aligned S2S evaluation. To demonstrate the strength of the framework, we first introduce a Human Chain-of-Thought (HCoT) annotation protocol to improve the diagnostic capability of existing judge benchmarks by separating evaluation into explicit dimensions: content (C), voice quality (VQ), and paralinguistics (P). Using this data, TRACE constructs a textual blueprint of inexpensive audio signals and prompts an LLM to render dimension-wise judgments, fusing them into an overall rating via a deterministic policy. TRACE achieves higher agreement with human raters than ALMs and transcript-only LLM judges while being significantly more cost-effective. We will release the HCoT annotations and the TRACE framework to enable scalable and human-aligned S2S evaluation.
The Interspeech 2025 Speech Accessibility Project Challenge
Jul 29, 2025While the last decade has witnessed significant advancements in Automatic Speech Recognition (ASR) systems, performance of these systems for individuals with speech disabilities remains inadequate, partly due to limited public training data. To bridge this gap, the 2025 Interspeech Speech Accessibility Project (SAP) Challenge was launched, utilizing over 400 hours of SAP data collected and transcribed from more than 500 individuals with diverse speech disabilities. Hosted on EvalAI and leveraging the remote evaluation pipeline, the SAP Challenge evaluates submissions based on Word Error Rate and Semantic Score. Consequently, 12 out of 22 valid teams outperformed the whisper-large-v2 baseline in terms of WER, while 17 teams surpassed the baseline on SemScore. Notably, the top team achieved the lowest WER of 8.11\%, and the highest SemScore of 88.44\% at the same time, setting new benchmarks for future ASR systems in recognizing impaired speech.
Mitigating Bad Ground Truth in Supervised Machine Learning based Crop Classification: A Multi-Level Framework with Sentinel-2 Images
Mar 14, 2025
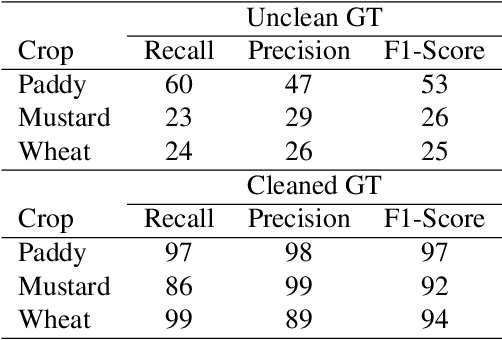
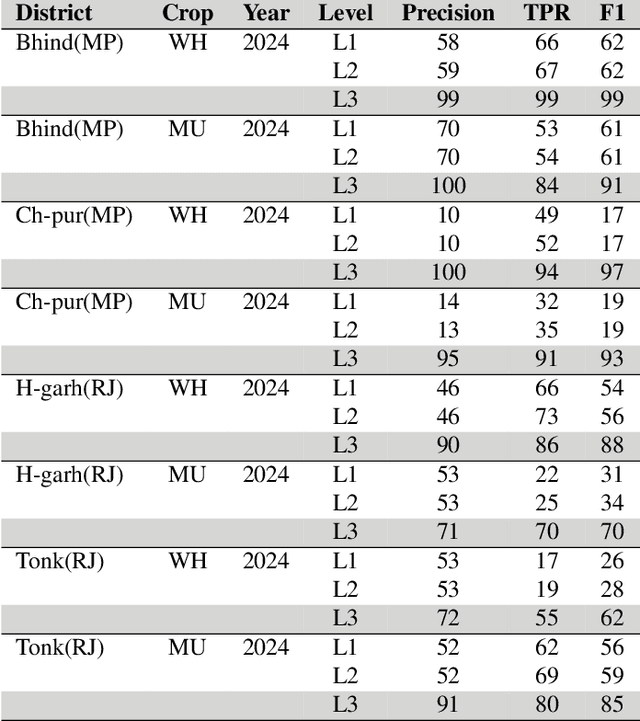
In agricultural management, precise Ground Truth (GT) data is crucial for accurate Machine Learning (ML) based crop classification. Yet, issues like crop mislabeling and incorrect land identification are common. We propose a multi-level GT cleaning framework while utilizing multi-temporal Sentinel-2 data to address these issues. Specifically, this framework utilizes generating embeddings for farmland, clustering similar crop profiles, and identification of outliers indicating GT errors. We validated clusters with False Colour Composite (FCC) checks and used distance-based metrics to scale and automate this verification process. The importance of cleaning the GT data became apparent when the models were trained on the clean and unclean data. For instance, when we trained a Random Forest model with the clean GT data, we achieved upto 70\% absolute percentage points higher for the F1 score metric. This approach advances crop classification methodologies, with potential for applications towards improving loan underwriting and agricultural decision-making.
Multi-Stage Multi-Modal Pre-Training for Automatic Speech Recognition
Mar 28, 2024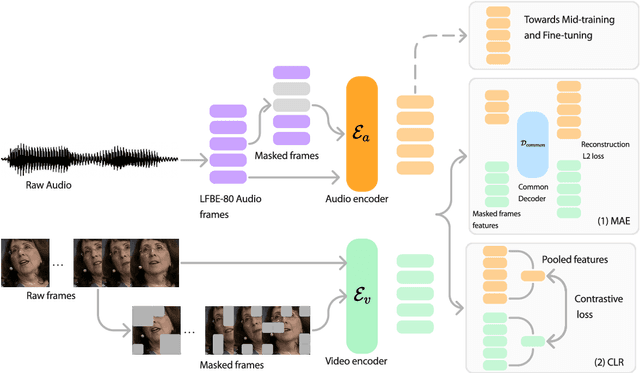
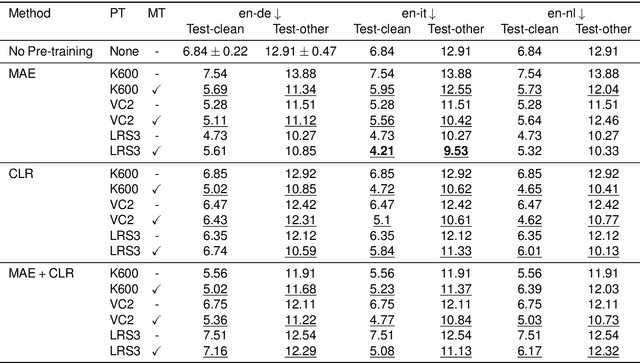
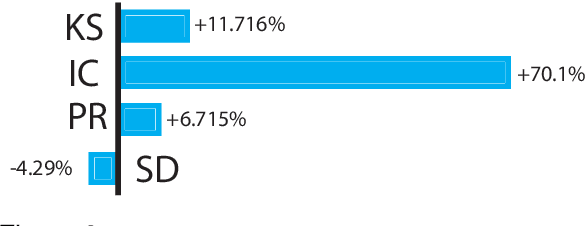
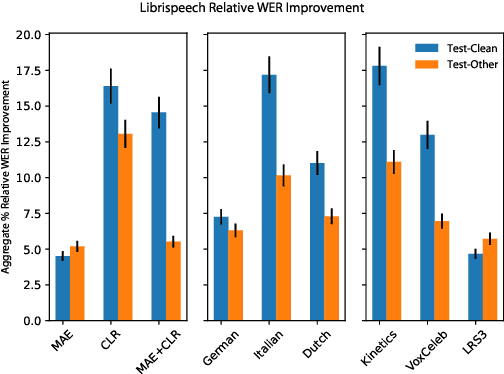
Recent advances in machine learning have demonstrated that multi-modal pre-training can improve automatic speech recognition (ASR) performance compared to randomly initialized models, even when models are fine-tuned on uni-modal tasks. Existing multi-modal pre-training methods for the ASR task have primarily focused on single-stage pre-training where a single unsupervised task is used for pre-training followed by fine-tuning on the downstream task. In this work, we introduce a novel method combining multi-modal and multi-task unsupervised pre-training with a translation-based supervised mid-training approach. We empirically demonstrate that such a multi-stage approach leads to relative word error rate (WER) improvements of up to 38.45% over baselines on both Librispeech and SUPERB. Additionally, we share several important findings for choosing pre-training methods and datasets.
Turn-taking and Backchannel Prediction with Acoustic and Large Language Model Fusion
Jan 26, 2024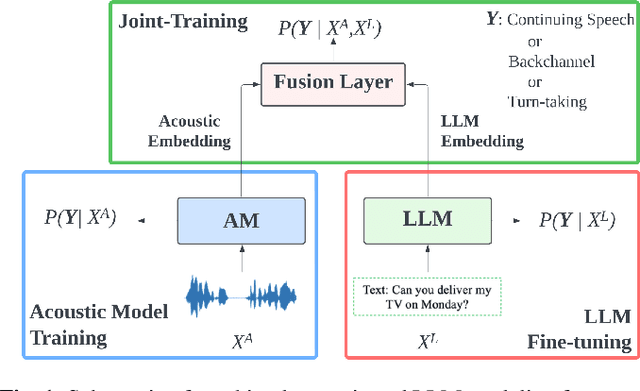
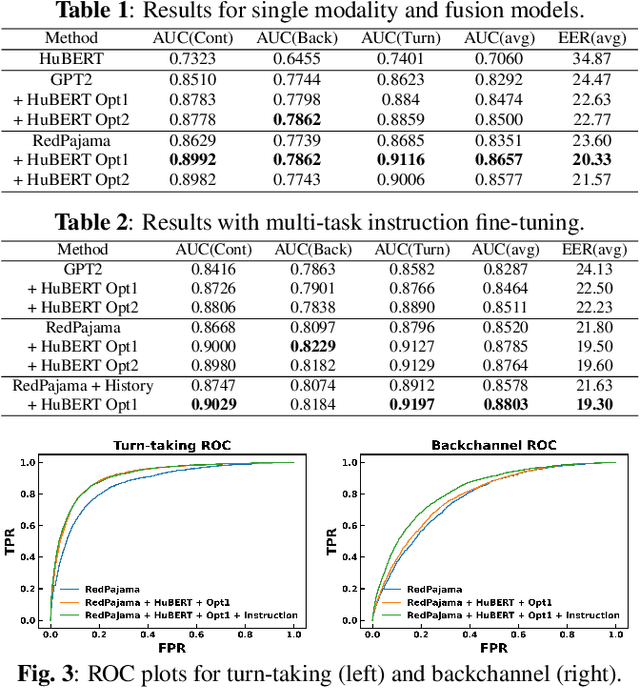
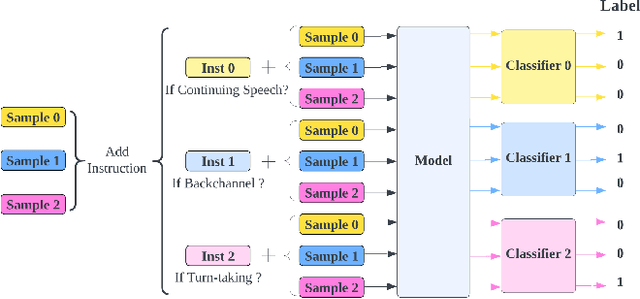
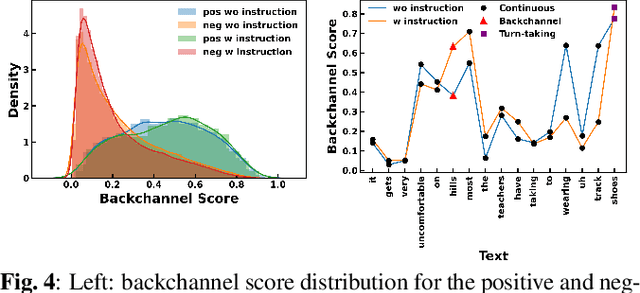
We propose an approach for continuous prediction of turn-taking and backchanneling locations in spoken dialogue by fusing a neural acoustic model with a large language model (LLM). Experiments on the Switchboard human-human conversation dataset demonstrate that our approach consistently outperforms the baseline models with single modality. We also develop a novel multi-task instruction fine-tuning strategy to further benefit from LLM-encoded knowledge for understanding the tasks and conversational contexts, leading to additional improvements. Our approach demonstrates the potential of combined LLMs and acoustic models for a more natural and conversational interaction between humans and speech-enabled AI agents.
Two-pass Endpoint Detection for Speech Recognition
Jan 17, 2024Endpoint (EP) detection is a key component of far-field speech recognition systems that assist the user through voice commands. The endpoint detector has to trade-off between accuracy and latency, since waiting longer reduces the cases of users being cut-off early. We propose a novel two-pass solution for endpointing, where the utterance endpoint detected from a first pass endpointer is verified by a 2nd-pass model termed EP Arbitrator. Our method improves the trade-off between early cut-offs and latency over a baseline endpointer, as tested on datasets including voice-assistant transactional queries, conversational speech, and the public SLURP corpus. We demonstrate that our method shows improvements regardless of the first-pass EP model used.
Multimodal Attention Merging for Improved Speech Recognition and Audio Event Classification
Dec 22, 2023



Training large foundation models using self-supervised objectives on unlabeled data, followed by fine-tuning on downstream tasks, has emerged as a standard procedure. Unfortunately, the efficacy of this approach is often constrained by both limited fine-tuning compute and scarcity in labeled downstream data. We introduce Multimodal Attention Merging (MAM), an attempt that facilitates direct knowledge transfer from attention matrices of models rooted in high resource modalities, text and images, to those in resource-constrained domains, speech and audio, employing a zero-shot paradigm. MAM reduces the relative Word Error Rate (WER) of an Automatic Speech Recognition (ASR) model by up to 6.70%, and relative classification error of an Audio Event Classification (AEC) model by 10.63%. In cases where some data/compute is available, we present Learnable-MAM, a data-driven approach to merging attention matrices, resulting in a further 2.90% relative reduction in WER for ASR and 18.42% relative reduction in AEC compared to fine-tuning.
Improving fairness for spoken language understanding in atypical speech with Text-to-Speech
Nov 16, 2023
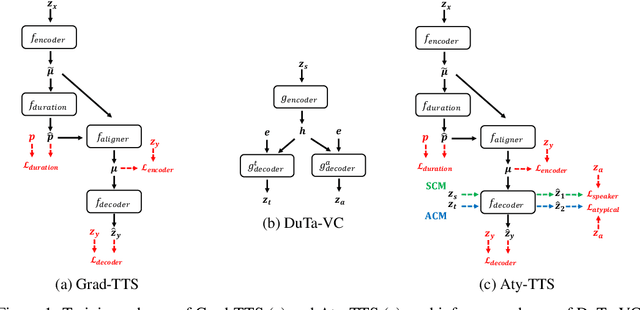
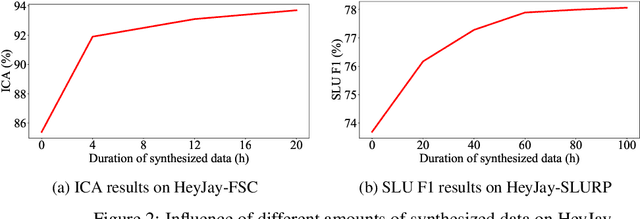
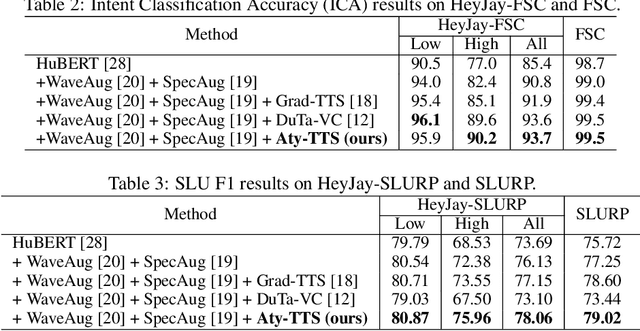
Spoken language understanding (SLU) systems often exhibit suboptimal performance in processing atypical speech, typically caused by neurological conditions and motor impairments. Recent advancements in Text-to-Speech (TTS) synthesis-based augmentation for more fair SLU have struggled to accurately capture the unique vocal characteristics of atypical speakers, largely due to insufficient data. To address this issue, we present a novel data augmentation method for atypical speakers by finetuning a TTS model, called Aty-TTS. Aty-TTS models speaker and atypical characteristics via knowledge transferring from a voice conversion model. Then, we use the augmented data to train SLU models adapted to atypical speech. To train these data augmentation models and evaluate the resulting SLU systems, we have collected a new atypical speech dataset containing intent annotation. Both objective and subjective assessments validate that Aty-TTS is capable of generating high-quality atypical speech. Furthermore, it serves as an effective data augmentation strategy, contributing to more fair SLU systems that can better accommodate individuals with atypical speech patterns.
Cross-utterance ASR Rescoring with Graph-based Label Propagation
Mar 27, 2023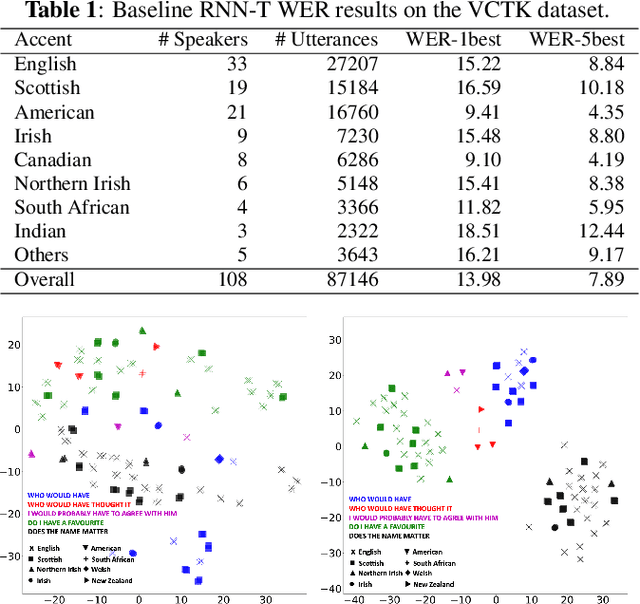
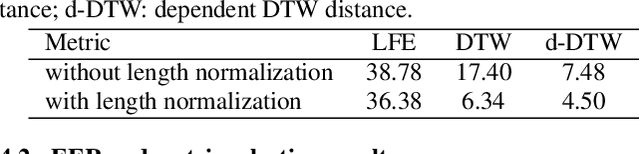
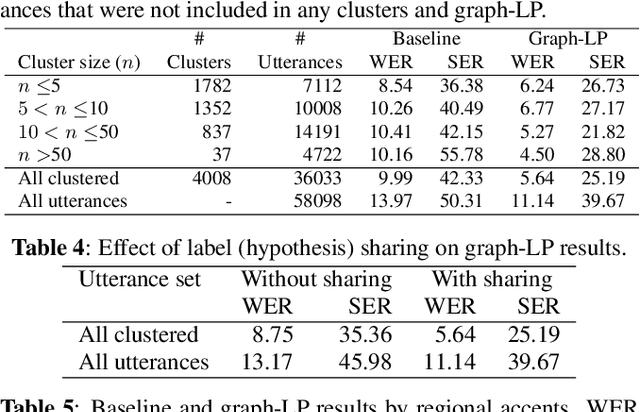
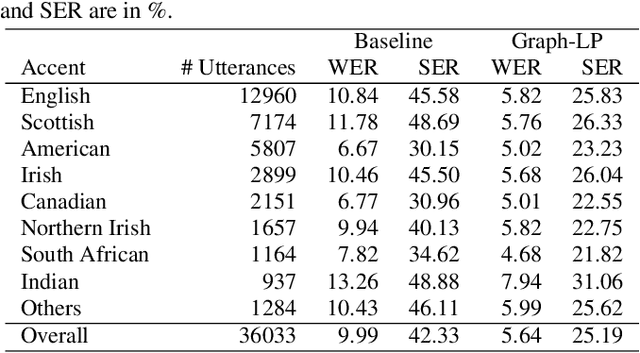
We propose a novel approach for ASR N-best hypothesis rescoring with graph-based label propagation by leveraging cross-utterance acoustic similarity. In contrast to conventional neural language model (LM) based ASR rescoring/reranking models, our approach focuses on acoustic information and conducts the rescoring collaboratively among utterances, instead of individually. Experiments on the VCTK dataset demonstrate that our approach consistently improves ASR performance, as well as fairness across speaker groups with different accents. Our approach provides a low-cost solution for mitigating the majoritarian bias of ASR systems, without the need to train new domain- or accent-specific models.