 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving fairness for spoken language understanding in atypical speech with Text-to-Speech
Nov 16, 2023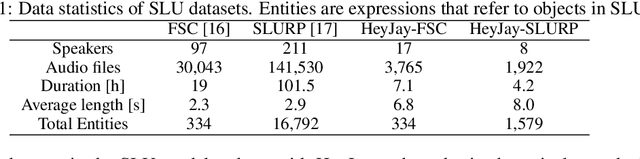
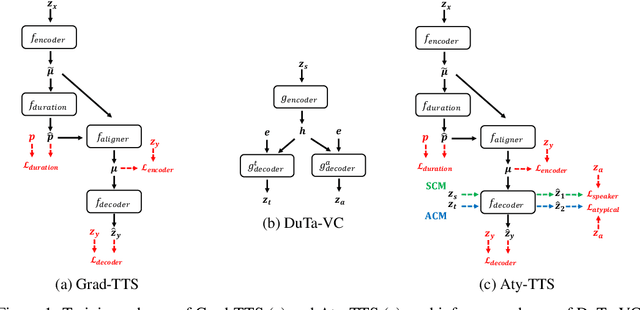
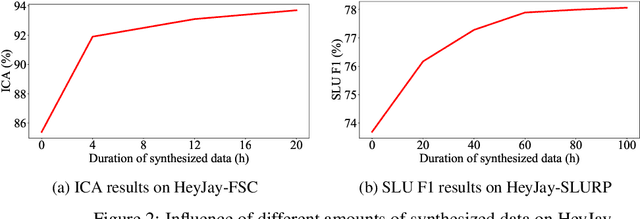
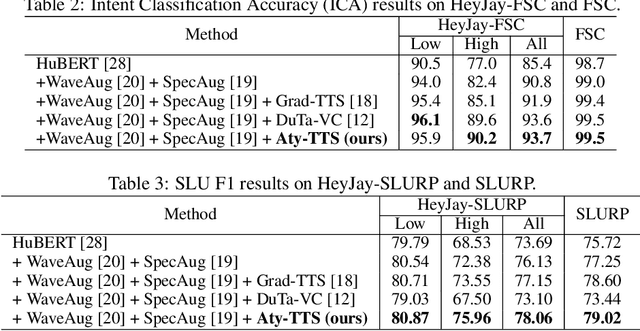
Spoken language understanding (SLU) systems often exhibit suboptimal performance in processing atypical speech, typically caused by neurological conditions and motor impairments. Recent advancements in Text-to-Speech (TTS) synthesis-based augmentation for more fair SLU have struggled to accurately capture the unique vocal characteristics of atypical speakers, largely due to insufficient data. To address this issue, we present a novel data augmentation method for atypical speakers by finetuning a TTS model, called Aty-TTS. Aty-TTS models speaker and atypical characteristics via knowledge transferring from a voice conversion model. Then, we use the augmented data to train SLU models adapted to atypical speech. To train these data augmentation models and evaluate the resulting SLU systems, we have collected a new atypical speech dataset containing intent annotation. Both objective and subjective assessments validate that Aty-TTS is capable of generating high-quality atypical speech. Furthermore, it serves as an effective data augmentation strategy, contributing to more fair SLU systems that can better accommodate individuals with atypical speech patterns.
DuTa-VC: A Duration-aware Typical-to-atypical Voice Conversion Approach with Diffusion Probabilistic Model
Jun 18, 2023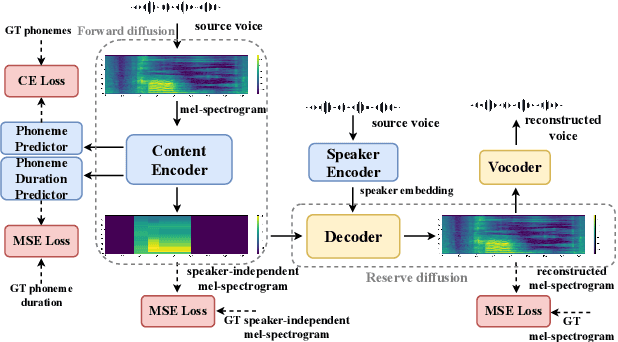
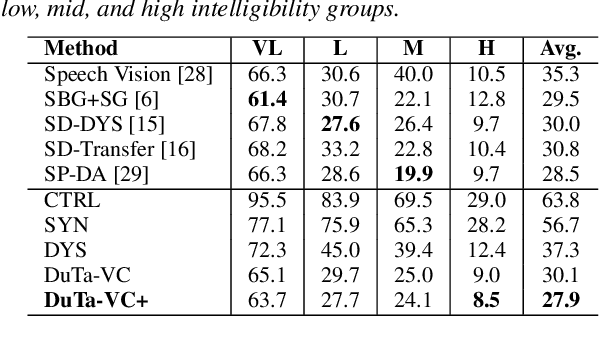
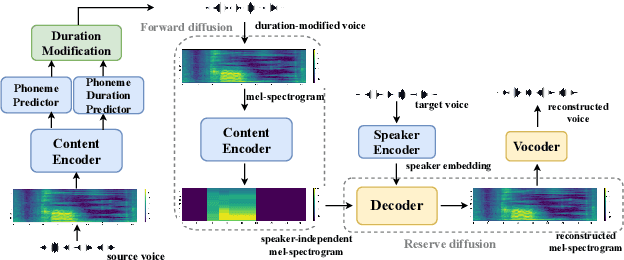
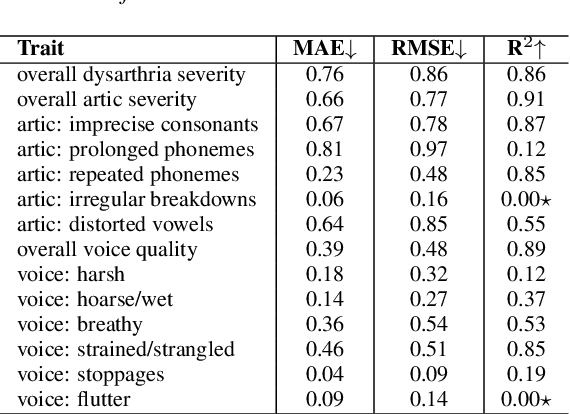
We present a novel typical-to-atypical voice conversion approach (DuTa-VC), which (i) can be trained with nonparallel data (ii) first introduces diffusion probabilistic model (iii) preserves the target speaker identity (iv) is aware of the phoneme duration of the target speaker. DuTa-VC consists of three parts: an encoder transforms the source mel-spectrogram into a duration-modified speaker-independent mel-spectrogram, a decoder performs the reverse diffusion to generate the target mel-spectrogram, and a vocoder is applied to reconstruct the waveform. Objective evaluations conducted on the UASpeech show that DuTa-VC is able to capture severity characteristics of dysarthric speech, reserves speaker identity, and significantly improves dysarthric speech recognition as a data augmentation. Subjective evaluations by two expert speech pathologists validate that DuTa-VC can preserve the severity and type of dysarthria of the target speakers in the synthesized speech.