 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpoken DialogSum: An Emotion-Rich Conversational Dataset for Spoken Dialogue Summarization
Dec 17, 2025


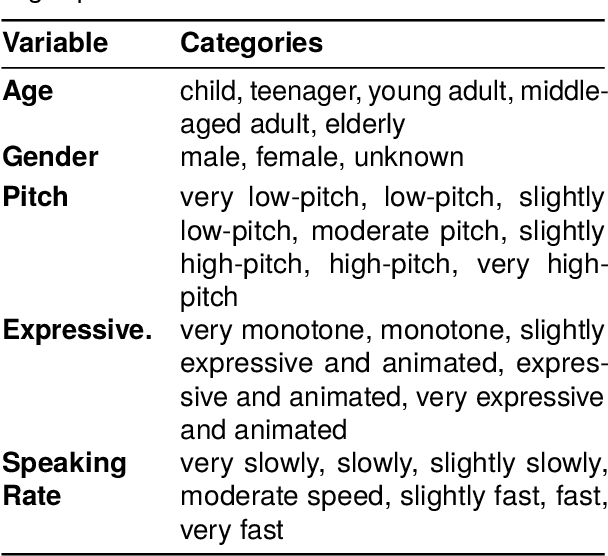
Recent audio language models can follow long conversations. However, research on emotion-aware or spoken dialogue summarization is constrained by the lack of data that links speech, summaries, and paralinguistic cues. We introduce Spoken DialogSum, the first corpus aligning raw conversational audio with factual summaries, emotion-rich summaries, and utterance-level labels for speaker age, gender, and emotion. The dataset is built in two stages: first, an LLM rewrites DialogSum scripts with Switchboard-style fillers and back-channels, then tags each utterance with emotion, pitch, and speaking rate. Second, an expressive TTS engine synthesizes speech from the tagged scripts, aligned with paralinguistic labels. Spoken DialogSum comprises 13,460 emotion-diverse dialogues, each paired with both a factual and an emotion-focused summary. We release an online demo at https://fatfat-emosum.github.io/EmoDialog-Sum-Audio-Samples/, with plans to release the full dataset in the near future. Baselines show that an Audio-LLM raises emotional-summary ROUGE-L by 28% relative to a cascaded ASR-LLM system, confirming the value of end-to-end speech modeling.
Multi-Target Backdoor Attacks Against Speaker Recognition
Aug 13, 2025In this work, we propose a multi-target backdoor attack against speaker identification using position-independent clicking sounds as triggers. Unlike previous single-target approaches, our method targets up to 50 speakers simultaneously, achieving success rates of up to 95.04%. To simulate more realistic attack conditions, we vary the signal-to-noise ratio between speech and trigger, demonstrating a trade-off between stealth and effectiveness. We further extend the attack to the speaker verification task by selecting the most similar training speaker - based on cosine similarity - as a proxy target. The attack is most effective when target and enrolled speaker pairs are highly similar, reaching success rates of up to 90% in such cases.
Enhancing Dialogue Annotation with Speaker Characteristics Leveraging a Frozen LLM
Aug 06, 2025In dialogue transcription pipelines, Large Language Models (LLMs) are frequently employed in post-processing to improve grammar, punctuation, and readability. We explore a complementary post-processing step: enriching transcribed dialogues by adding metadata tags for speaker characteristics such as age, gender, and emotion. Some of the tags are global to the entire dialogue, while some are time-variant. Our approach couples frozen audio foundation models, such as Whisper or WavLM, with a frozen LLAMA language model to infer these speaker attributes, without requiring task-specific fine-tuning of either model. Using lightweight, efficient connectors to bridge audio and language representations, we achieve competitive performance on speaker profiling tasks while preserving modularity and speed. Additionally, we demonstrate that a frozen LLAMA model can compare x-vectors directly, achieving an Equal Error Rate of 8.8% in some scenarios.
Rhythm Features for Speaker Identification
Jun 07, 2025While deep learning models have demonstrated robust performance in speaker recognition tasks, they primarily rely on low-level audio features learned empirically from spectrograms or raw waveforms. However, prior work has indicated that idiosyncratic speaking styles heavily influence the temporal structure of linguistic units in speech signals (rhythm). This makes rhythm a strong yet largely overlooked candidate for a speech identity feature. In this paper, we test this hypothesis by applying deep learning methods to perform text-independent speaker identification from rhythm features. Our findings support the usefulness of rhythmic information for speaker recognition tasks but also suggest that high intra-subject variability in ad-hoc speech can degrade its effectiveness.
SoloSpeech: Enhancing Intelligibility and Quality in Target Speech Extraction through a Cascaded Generative Pipeline
May 25, 2025Target Speech Extraction (TSE) aims to isolate a target speaker's voice from a mixture of multiple speakers by leveraging speaker-specific cues, typically provided as auxiliary audio (a.k.a. cue audio). Although recent advancements in TSE have primarily employed discriminative models that offer high perceptual quality, these models often introduce unwanted artifacts, reduce naturalness, and are sensitive to discrepancies between training and testing environments. On the other hand, generative models for TSE lag in perceptual quality and intelligibility. To address these challenges, we present SoloSpeech, a novel cascaded generative pipeline that integrates compression, extraction, reconstruction, and correction processes. SoloSpeech features a speaker-embedding-free target extractor that utilizes conditional information from the cue audio's latent space, aligning it with the mixture audio's latent space to prevent mismatches. Evaluated on the widely-used Libri2Mix dataset, SoloSpeech achieves the new state-of-the-art intelligibility and quality in target speech extraction and speech separation tasks while demonstrating exceptional generalization on out-of-domain data and real-world scenarios.
Vox-Profile: A Speech Foundation Model Benchmark for Characterizing Diverse Speaker and Speech Traits
May 20, 2025We introduce Vox-Profile, a comprehensive benchmark to characterize rich speaker and speech traits using speech foundation models. Unlike existing works that focus on a single dimension of speaker traits, Vox-Profile provides holistic and multi-dimensional profiles that reflect both static speaker traits (e.g., age, sex, accent) and dynamic speech properties (e.g., emotion, speech flow). This benchmark is grounded in speech science and linguistics, developed with domain experts to accurately index speaker and speech characteristics. We report benchmark experiments using over 15 publicly available speech datasets and several widely used speech foundation models that target various static and dynamic speaker and speech properties. In addition to benchmark experiments, we showcase several downstream applications supported by Vox-Profile. First, we show that Vox-Profile can augment existing speech recognition datasets to analyze ASR performance variability. Vox-Profile is also used as a tool to evaluate the performance of speech generation systems. Finally, we assess the quality of our automated profiles through comparison with human evaluation and show convergent validity. Vox-Profile is publicly available at: https://github.com/tiantiaf0627/vox-profile-release.
Demographic Attributes Prediction from Speech Using WavLM Embeddings
Feb 17, 2025This paper introduces a general classifier based on WavLM features, to infer demographic characteristics, such as age, gender, native language, education, and country, from speech. Demographic feature prediction plays a crucial role in applications like language learning, accessibility, and digital forensics, enabling more personalized and inclusive technologies. Leveraging pretrained models for embedding extraction, the proposed framework identifies key acoustic and linguistic fea-tures associated with demographic attributes, achieving a Mean Absolute Error (MAE) of 4.94 for age prediction and over 99.81% accuracy for gender classification across various datasets. Our system improves upon existing models by up to relative 30% in MAE and up to relative 10% in accuracy and F1 scores across tasks, leveraging a diverse range of datasets and large pretrained models to ensure robustness and generalizability. This study offers new insights into speaker diversity and provides a strong foundation for future research in speech-based demographic profiling.
Detecting Neurodegenerative Diseases using Frame-Level Handwriting Embeddings
Feb 10, 2025In this study, we explored the use of spectrograms to represent handwriting signals for assessing neurodegenerative diseases, including 42 healthy controls (CTL), 35 subjects with Parkinson's Disease (PD), 21 with Alzheimer's Disease (AD), and 15 with Parkinson's Disease Mimics (PDM). We applied CNN and CNN-BLSTM models for binary classification using both multi-channel fixed-size and frame-based spectrograms. Our results showed that handwriting tasks and spectrogram channel combinations significantly impacted classification performance. The highest F1-score (89.8%) was achieved for AD vs. CTL, while PD vs. CTL reached 74.5%, and PD vs. PDM scored 77.97%. CNN consistently outperformed CNN-BLSTM. Different sliding window lengths were tested for constructing frame-based spectrograms. A 1-second window worked best for AD, longer windows improved PD classification, and window length had little effect on PD vs. PDM.
CA-SSLR: Condition-Aware Self-Supervised Learning Representation for Generalized Speech Processing
Dec 05, 2024We introduce Condition-Aware Self-Supervised Learning Representation (CA-SSLR), a generalist conditioning model broadly applicable to various speech-processing tasks. Compared to standard fine-tuning methods that optimize for downstream models, CA-SSLR integrates language and speaker embeddings from earlier layers, making the SSL model aware of the current language and speaker context. This approach reduces the reliance on input audio features while preserving the integrity of the base SSLR. CA-SSLR improves the model's capabilities and demonstrates its generality on unseen tasks with minimal task-specific tuning. Our method employs linear modulation to dynamically adjust internal representations, enabling fine-grained adaptability without significantly altering the original model behavior. Experiments show that CA-SSLR reduces the number of trainable parameters, mitigates overfitting, and excels in under-resourced and unseen tasks. Specifically, CA-SSLR achieves a 10% relative reduction in LID errors, a 37% improvement in ASR CER on the ML-SUPERB benchmark, and a 27% decrease in SV EER on VoxCeleb-1, demonstrating its effectiveness.
Clean Label Attacks against SLU Systems
Sep 13, 2024
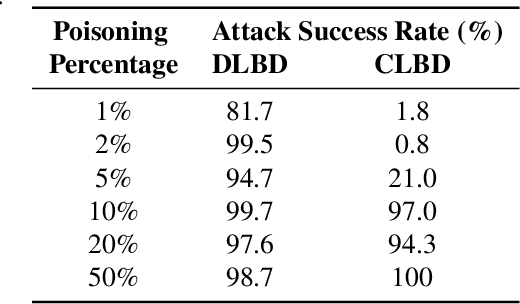

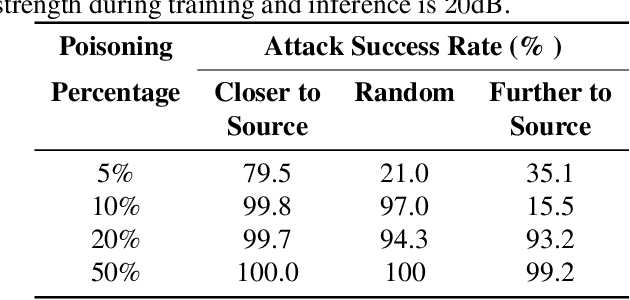
Poisoning backdoor attacks involve an adversary manipulating the training data to induce certain behaviors in the victim model by inserting a trigger in the signal at inference time. We adapted clean label backdoor (CLBD)-data poisoning attacks, which do not modify the training labels, on state-of-the-art speech recognition models that support/perform a Spoken Language Understanding task, achieving 99.8% attack success rate by poisoning 10% of the training data. We analyzed how varying the signal-strength of the poison, percent of samples poisoned, and choice of trigger impact the attack. We also found that CLBD attacks are most successful when applied to training samples that are inherently hard for a proxy model. Using this strategy, we achieved an attack success rate of 99.3% by poisoning a meager 1.5% of the training data. Finally, we applied two previously developed defenses against gradient-based attacks, and found that they attain mixed success against poisoning.