 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Target Backdoor Attacks Against Speaker Recognition
Aug 13, 2025In this work, we propose a multi-target backdoor attack against speaker identification using position-independent clicking sounds as triggers. Unlike previous single-target approaches, our method targets up to 50 speakers simultaneously, achieving success rates of up to 95.04%. To simulate more realistic attack conditions, we vary the signal-to-noise ratio between speech and trigger, demonstrating a trade-off between stealth and effectiveness. We further extend the attack to the speaker verification task by selecting the most similar training speaker - based on cosine similarity - as a proxy target. The attack is most effective when target and enrolled speaker pairs are highly similar, reaching success rates of up to 90% in such cases.
Clean Label Attacks against SLU Systems
Sep 13, 2024
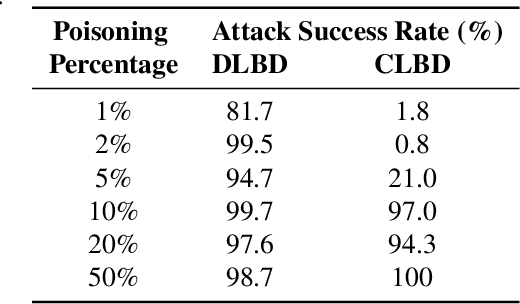

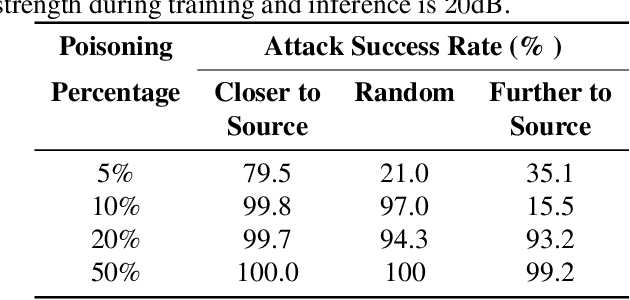
Poisoning backdoor attacks involve an adversary manipulating the training data to induce certain behaviors in the victim model by inserting a trigger in the signal at inference time. We adapted clean label backdoor (CLBD)-data poisoning attacks, which do not modify the training labels, on state-of-the-art speech recognition models that support/perform a Spoken Language Understanding task, achieving 99.8% attack success rate by poisoning 10% of the training data. We analyzed how varying the signal-strength of the poison, percent of samples poisoned, and choice of trigger impact the attack. We also found that CLBD attacks are most successful when applied to training samples that are inherently hard for a proxy model. Using this strategy, we achieved an attack success rate of 99.3% by poisoning a meager 1.5% of the training data. Finally, we applied two previously developed defenses against gradient-based attacks, and found that they attain mixed success against poisoning.
Unraveling Adversarial Examples against Speaker Identification -- Techniques for Attack Detection and Victim Model Classification
Feb 29, 2024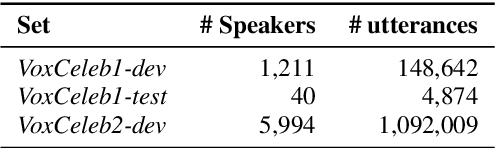
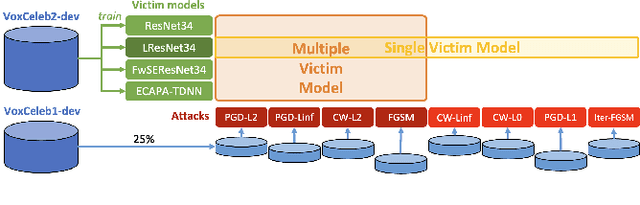
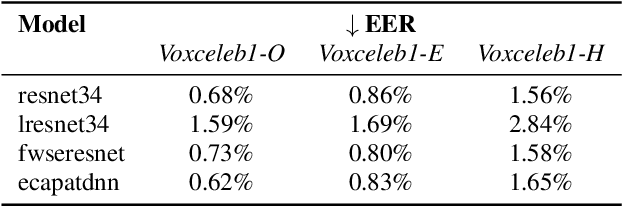
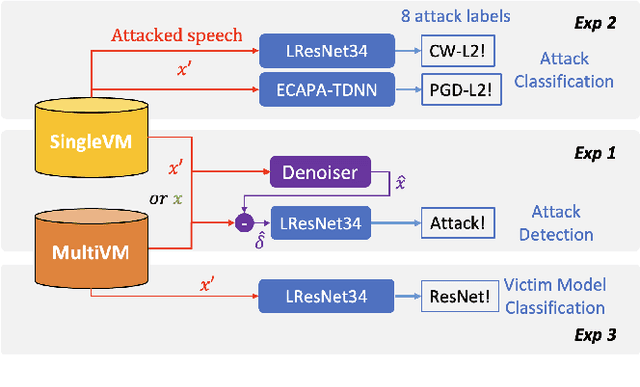
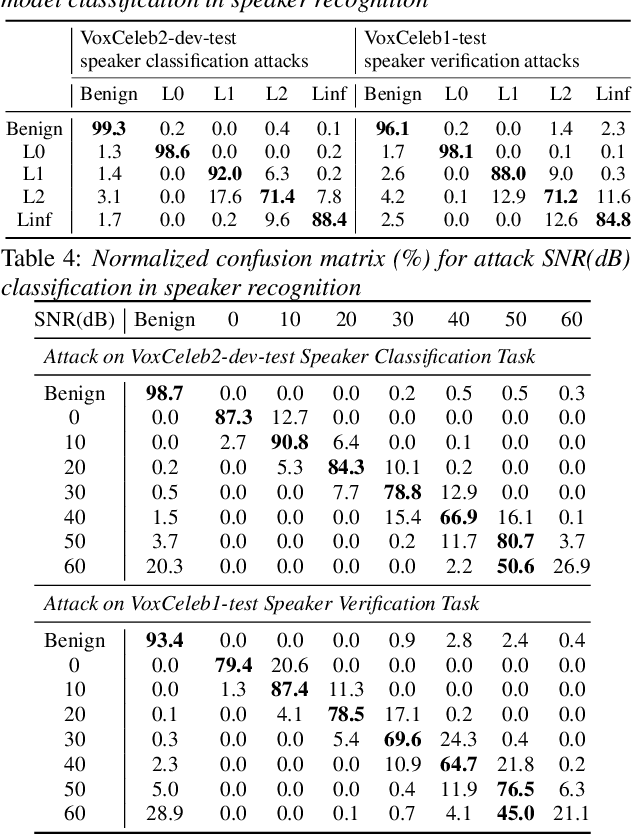
Adversarial examples have proven to threaten speaker identification systems, and several countermeasures against them have been proposed. In this paper, we propose a method to detect the presence of adversarial examples, i.e., a binary classifier distinguishing between benign and adversarial examples. We build upon and extend previous work on attack type classification by exploring new architectures. Additionally, we introduce a method for identifying the victim model on which the adversarial attack is carried out. To achieve this, we generate a new dataset containing multiple attacks performed against various victim models. We achieve an AUC of 0.982 for attack detection, with no more than a 0.03 drop in performance for unknown attacks. Our attack classification accuracy (excluding benign) reaches 86.48% across eight attack types using our LightResNet34 architecture, while our victim model classification accuracy reaches 72.28% across four victim models.
Defense against Adversarial Attacks on Hybrid Speech Recognition using Joint Adversarial Fine-tuning with Denoiser
Apr 08, 2022
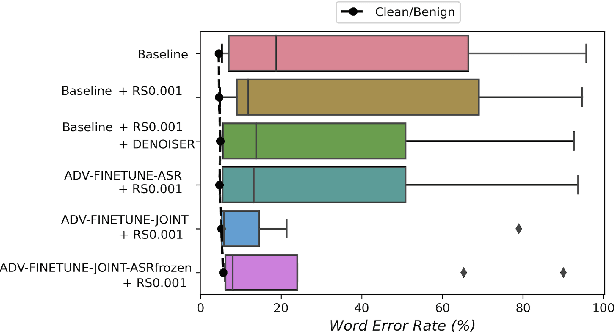

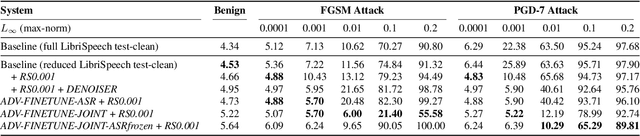
Adversarial attacks are a threat to automatic speech recognition (ASR) systems, and it becomes imperative to propose defenses to protect them. In this paper, we perform experiments to show that K2 conformer hybrid ASR is strongly affected by white-box adversarial attacks. We propose three defenses--denoiser pre-processor, adversarially fine-tuning ASR model, and adversarially fine-tuning joint model of ASR and denoiser. Our evaluation shows denoiser pre-processor (trained on offline adversarial examples) fails to defend against adaptive white-box attacks. However, adversarially fine-tuning the denoiser using a tandem model of denoiser and ASR offers more robustness. We evaluate two variants of this defense--one updating parameters of both models and the second keeping ASR frozen. The joint model offers a mean absolute decrease of 19.3\% ground truth (GT) WER with reference to baseline against fast gradient sign method (FGSM) attacks with different $L_\infty$ norms. The joint model with frozen ASR parameters gives the best defense against projected gradient descent (PGD) with 7 iterations, yielding a mean absolute increase of 22.3\% GT WER with reference to baseline; and against PGD with 500 iterations, yielding a mean absolute decrease of 45.08\% GT WER and an increase of 68.05\% adversarial target WER.
AdvEst: Adversarial Perturbation Estimation to Classify and Detect Adversarial Attacks against Speaker Identification
Apr 08, 2022
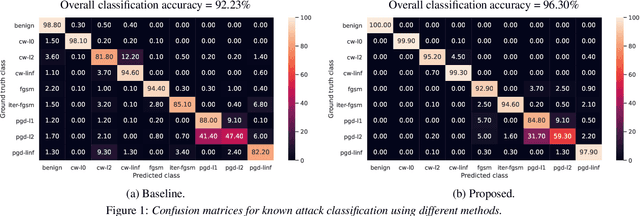

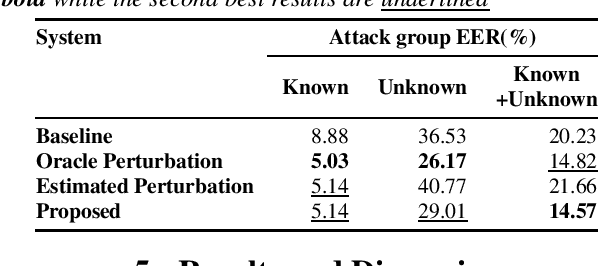
Adversarial attacks pose a severe security threat to the state-of-the-art speaker identification systems, thereby making it vital to propose countermeasures against them. Building on our previous work that used representation learning to classify and detect adversarial attacks, we propose an improvement to it using AdvEst, a method to estimate adversarial perturbation. First, we prove our claim that training the representation learning network using adversarial perturbations as opposed to adversarial examples (consisting of the combination of clean signal and adversarial perturbation) is beneficial because it eliminates nuisance information. At inference time, we use a time-domain denoiser to estimate the adversarial perturbations from adversarial examples. Using our improved representation learning approach to obtain attack embeddings (signatures), we evaluate their performance for three applications: known attack classification, attack verification, and unknown attack detection. We show that common attacks in the literature (Fast Gradient Sign Method (FGSM), Projected Gradient Descent (PGD), Carlini-Wagner (CW) with different Lp threat models) can be classified with an accuracy of ~96%. We also detect unknown attacks with an equal error rate (EER) of ~9%, which is absolute improvement of ~12% from our previous work.
Representation Learning to Classify and Detect Adversarial Attacks against Speaker and Speech Recognition Systems
Jul 09, 2021
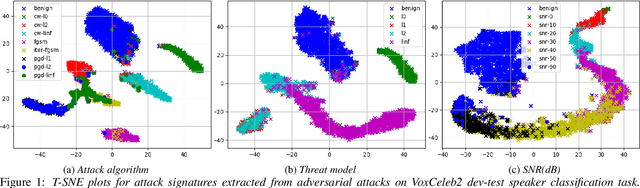
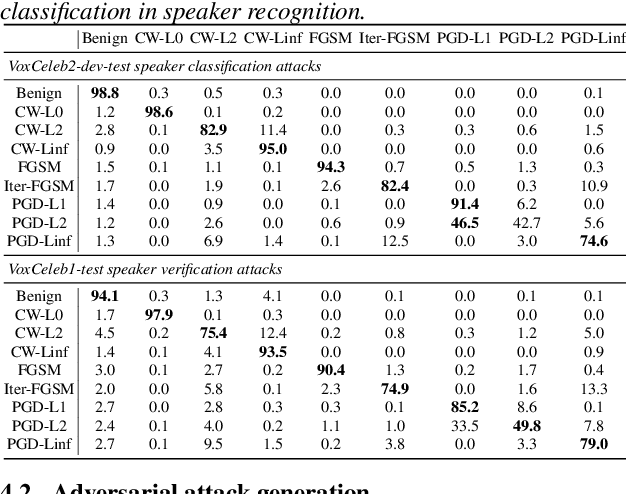
Adversarial attacks have become a major threat for machine learning applications. There is a growing interest in studying these attacks in the audio domain, e.g, speech and speaker recognition; and find defenses against them. In this work, we focus on using representation learning to classify/detect attacks w.r.t. the attack algorithm, threat model or signal-to-adversarial-noise ratio. We found that common attacks in the literature can be classified with accuracies as high as 90%. Also, representations trained to classify attacks against speaker identification can be used also to classify attacks against speaker verification and speech recognition. We also tested an attack verification task, where we need to decide whether two speech utterances contain the same attack. We observed that our models did not generalize well to attack algorithms not included in the attack representation model training. Motivated by this, we evaluated an unknown attack detection task. We were able to detect unknown attacks with equal error rates of about 19%, which is promising.
Adversarial Attacks and Defenses for Speech Recognition Systems
Mar 31, 2021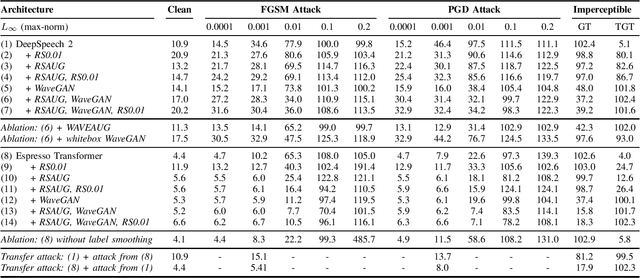
The ubiquitous presence of machine learning systems in our lives necessitates research into their vulnerabilities and appropriate countermeasures. In particular, we investigate the effectiveness of adversarial attacks and defenses against automatic speech recognition (ASR) systems. We select two ASR models - a thoroughly studied DeepSpeech model and a more recent Espresso framework Transformer encoder-decoder model. We investigate two threat models: a denial-of-service scenario where fast gradient-sign method (FGSM) or weak projected gradient descent (PGD) attacks are used to degrade the model's word error rate (WER); and a targeted scenario where a more potent imperceptible attack forces the system to recognize a specific phrase. We find that the attack transferability across the investigated ASR systems is limited. To defend the model, we use two preprocessing defenses: randomized smoothing and WaveGAN-based vocoder, and find that they significantly improve the model's adversarial robustness. We show that a WaveGAN vocoder can be a useful countermeasure to adversarial attacks on ASR systems - even when it is jointly attacked with the ASR, the target phrases' word error rate is high.
Adversarial Attacks and Defenses for Speaker Identification Systems
Jan 22, 2021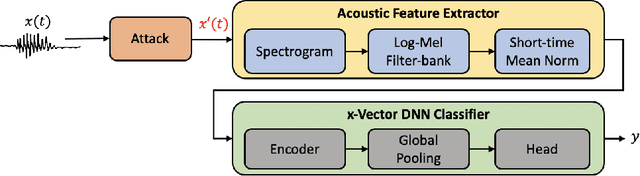
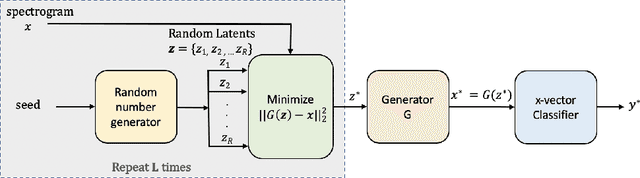

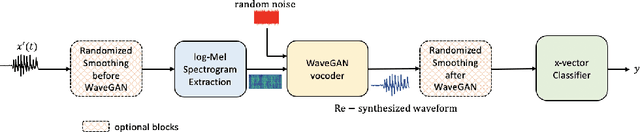
Research in automatic speaker recognition (SR) has been undertaken for several decades, reaching great performance. However, researchers discovered potential loopholes in these technologies like spoofing attacks. Quite recently, a new genre of attack, termed adversarial attacks, has been proved to be fatal in computer vision and it is vital to study their effects on SR systems. This paper examines how state-of-the-art speaker identification (SID) systems are vulnerable to adversarial attacks and how to defend against them. We investigated adversarial attacks common in the literature like fast gradient sign method (FGSM), iterative-FGSM / basic iterative method (BIM) and Carlini-Wagner (CW). Furthermore, we propose four pre-processing defenses against these attacks - randomized smoothing, DefenseGAN, variational autoencoder (VAE) and WaveGAN vocoder. We found that SID is extremely vulnerable under Iterative FGSM and CW attacks. Randomized smoothing defense robustified the system for imperceptible BIM and CW attacks recovering classification accuracies ~97%. Defenses based on generative models (DefenseGAN, VAE and WaveGAN) project adversarial examples (outside manifold) back into the clean manifold. In the case that attacker cannot adapt the attack to the defense (black-box defense), WaveGAN performed the best, being close to clean condition (Accuracy>97%). However, if the attack is adapted to the defense - assuming the attacker has access to the defense model (white-box defense), VAE and WaveGAN protection dropped significantly-50% and 37% accuracy for CW attack. To counteract this,we combined randomized smoothing with VAE or WaveGAN. We found that smoothing followed by WaveGAN vocoder was the most effective defense overall. As a black-box defense, it provides 93% average accuracy. As white-box defense, accuracy only degraded for iterative attacks with perceptible perturbations (L>=0.01).