 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClean Label Attacks against SLU Systems
Paper and Code
Sep 13, 2024
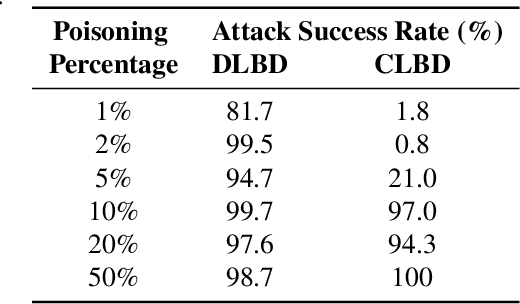

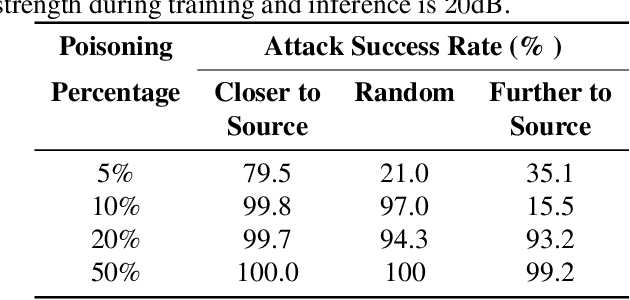
Poisoning backdoor attacks involve an adversary manipulating the training data to induce certain behaviors in the victim model by inserting a trigger in the signal at inference time. We adapted clean label backdoor (CLBD)-data poisoning attacks, which do not modify the training labels, on state-of-the-art speech recognition models that support/perform a Spoken Language Understanding task, achieving 99.8% attack success rate by poisoning 10% of the training data. We analyzed how varying the signal-strength of the poison, percent of samples poisoned, and choice of trigger impact the attack. We also found that CLBD attacks are most successful when applied to training samples that are inherently hard for a proxy model. Using this strategy, we achieved an attack success rate of 99.3% by poisoning a meager 1.5% of the training data. Finally, we applied two previously developed defenses against gradient-based attacks, and found that they attain mixed success against poisoning.