 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnraveling Adversarial Examples against Speaker Identification -- Techniques for Attack Detection and Victim Model Classification
Feb 29, 2024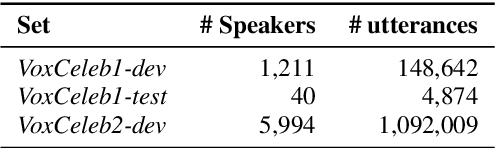
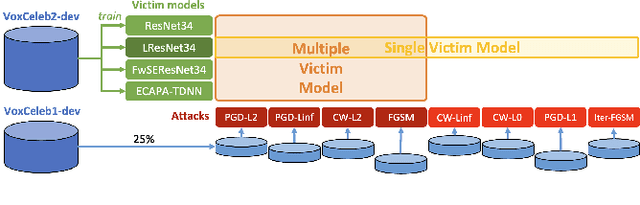
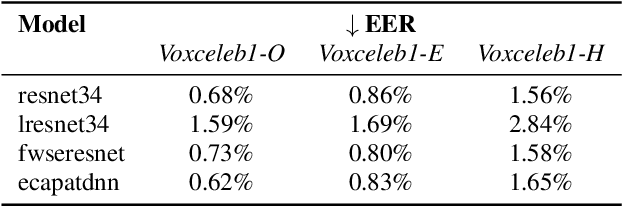
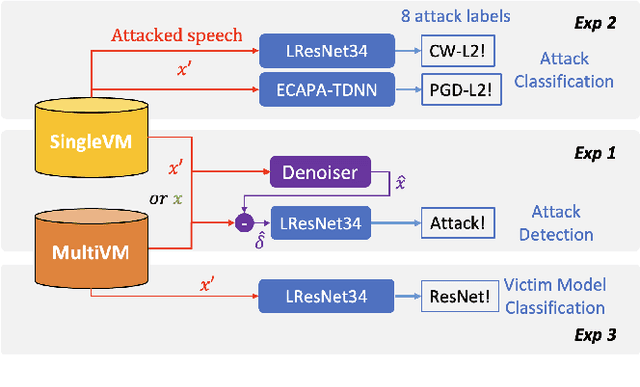
Adversarial examples have proven to threaten speaker identification systems, and several countermeasures against them have been proposed. In this paper, we propose a method to detect the presence of adversarial examples, i.e., a binary classifier distinguishing between benign and adversarial examples. We build upon and extend previous work on attack type classification by exploring new architectures. Additionally, we introduce a method for identifying the victim model on which the adversarial attack is carried out. To achieve this, we generate a new dataset containing multiple attacks performed against various victim models. We achieve an AUC of 0.982 for attack detection, with no more than a 0.03 drop in performance for unknown attacks. Our attack classification accuracy (excluding benign) reaches 86.48% across eight attack types using our LightResNet34 architecture, while our victim model classification accuracy reaches 72.28% across four victim models.
Leveraging Pretrained Image-text Models for Improving Audio-Visual Learning
Sep 08, 2023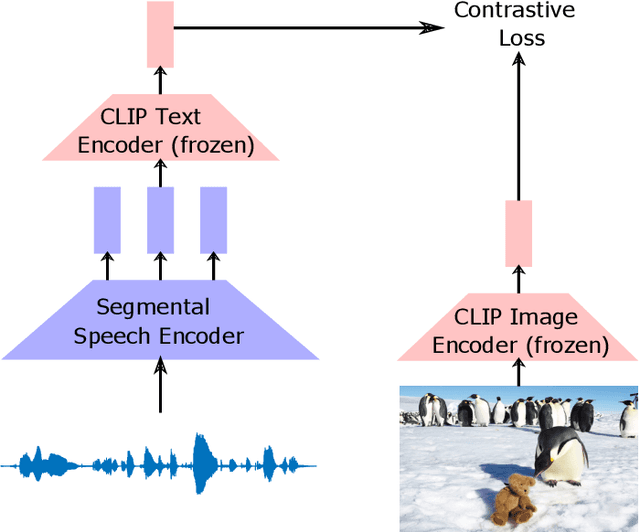
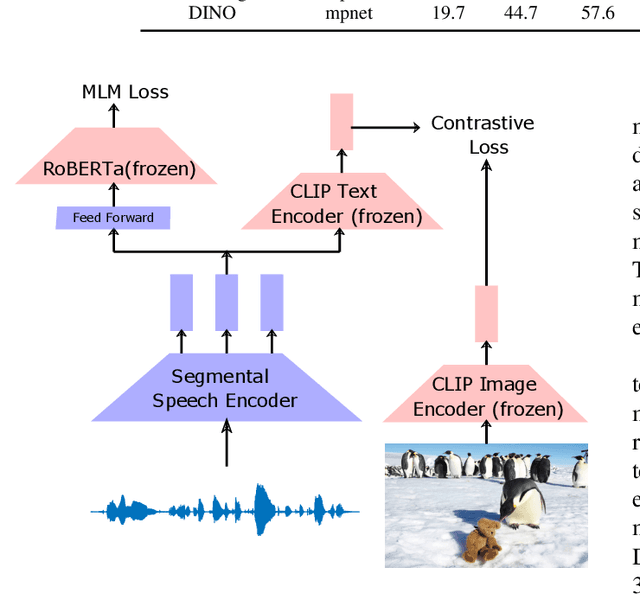
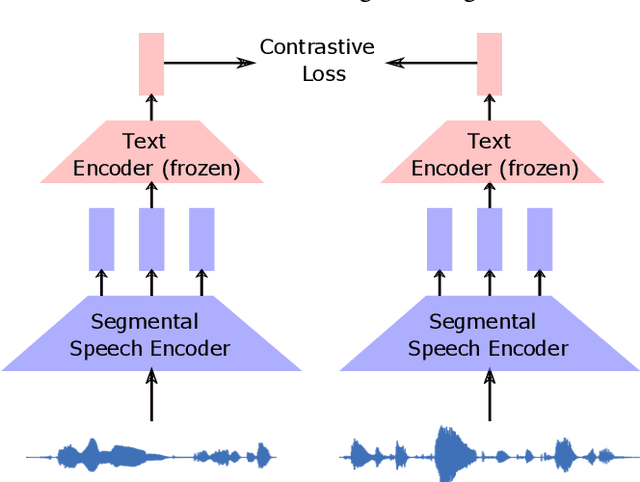
Visually grounded speech systems learn from paired images and their spoken captions. Recently, there have been attempts to utilize the visually grounded models trained from images and their corresponding text captions, such as CLIP, to improve speech-based visually grounded models' performance. However, the majority of these models only utilize the pretrained image encoder. Cascaded SpeechCLIP attempted to generate localized word-level information and utilize both the pretrained image and text encoders. Despite using both, they noticed a substantial drop in retrieval performance. We proposed Segmental SpeechCLIP which used a hierarchical segmental speech encoder to generate sequences of word-like units. We used the pretrained CLIP text encoder on top of these word-like unit representations and showed significant improvements over the cascaded variant of SpeechCLIP. Segmental SpeechCLIP directly learns the word embeddings as input to the CLIP text encoder bypassing the vocabulary embeddings. Here, we explore mapping audio to CLIP vocabulary embeddings via regularization and quantization. As our objective is to distill semantic information into the speech encoders, we explore the usage of large unimodal pretrained language models as the text encoders. Our method enables us to bridge image and text encoders e.g. DINO and RoBERTa trained with uni-modal data. Finally, we extend our framework in audio-only settings where only pairs of semantically related audio are available. Experiments show that audio-only systems perform close to the audio-visual system.
Regularizing Contrastive Predictive Coding for Speech Applications
Apr 26, 2023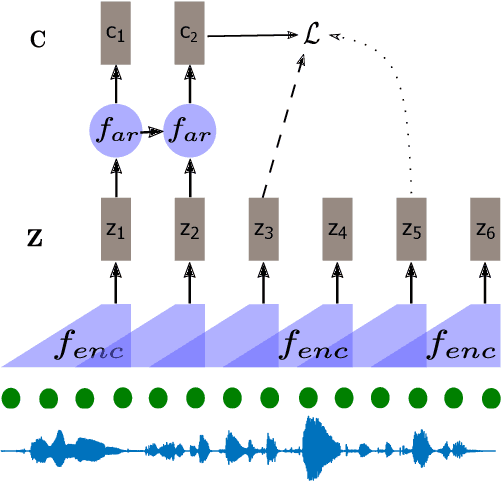
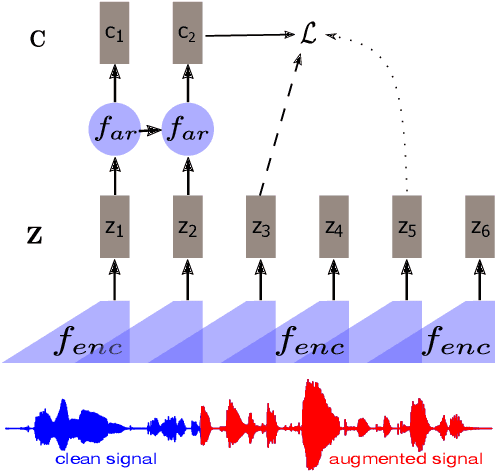
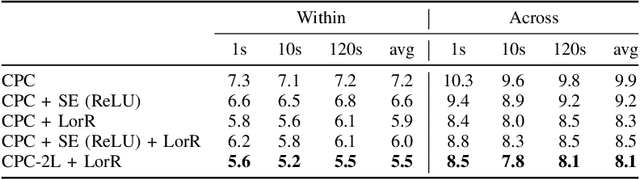
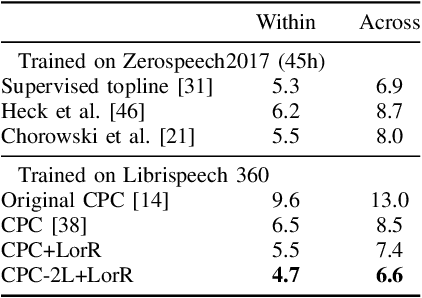
Self-supervised methods such as Contrastive predictive Coding (CPC) have greatly improved the quality of the unsupervised representations. These representations significantly reduce the amount of labeled data needed for downstream task performance, such as automatic speech recognition. CPC learns representations by learning to predict future frames given current frames. Based on the observation that the acoustic information, e.g., phones, changes slower than the feature extraction rate in CPC, we propose regularization techniques that impose slowness constraints on the features. Here we propose two regularization techniques: Self-expressing constraint and Left-or-Right regularization. We evaluate the proposed model on ABX and linear phone classification tasks, acoustic unit discovery, and automatic speech recognition. The regularized CPC trained on 100 hours of unlabeled data matches the performance of the baseline CPC trained on 360 hours of unlabeled data. We also show that our regularization techniques are complementary to data augmentation and can further boost the system's performance. In monolingual, cross-lingual, or multilingual settings, with/without data augmentation, regardless of the amount of data used for training, our regularized models outperformed the baseline CPC models on the ABX task.
Self-FiLM: Conditioning GANs with self-supervised representations for bandwidth extension based speaker recognition
Mar 07, 2023



Speech super-resolution/Bandwidth Extension (BWE) can improve downstream tasks like Automatic Speaker Verification (ASV). We introduce a simple novel technique called Self-FiLM to inject self-supervision into existing BWE models via Feature-wise Linear Modulation. We hypothesize that such information captures domain/environment information, which can give zero-shot generalization. Self-FiLM Conditional GAN (CGAN) gives 18% relative improvement in Equal Error Rate and 8.5% in minimum Decision Cost Function using state-of-the-art ASV system on SRE21 test. We further by 1) deep feature loss from time-domain models and 2) re-training of data2vec 2.0 models on naturalistic wideband (VoxCeleb) and telephone data (SRE Superset etc.). Lastly, we integrate self-supervision with CycleGAN to present a completely unsupervised solution that matches the semi-supervised performance.
Time-domain speech super-resolution with GAN based modeling for telephony speaker verification
Sep 04, 2022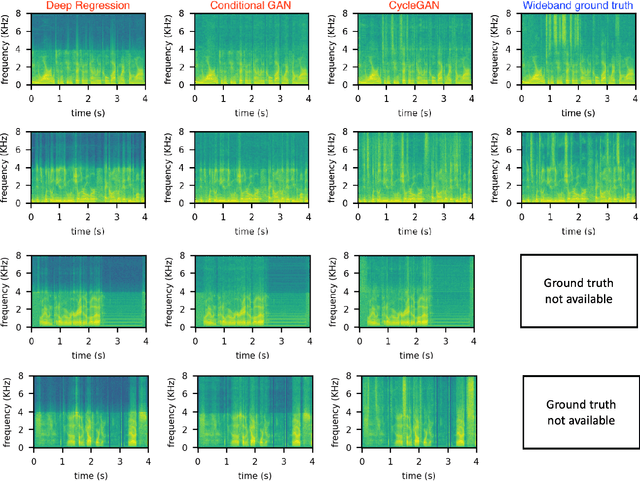
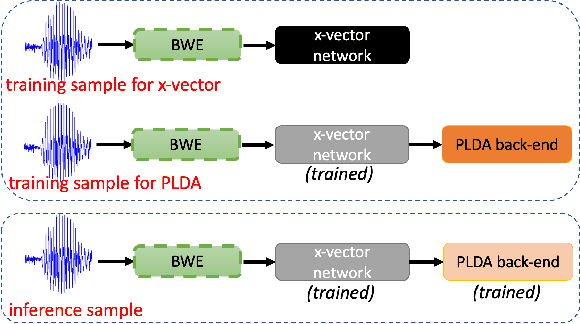
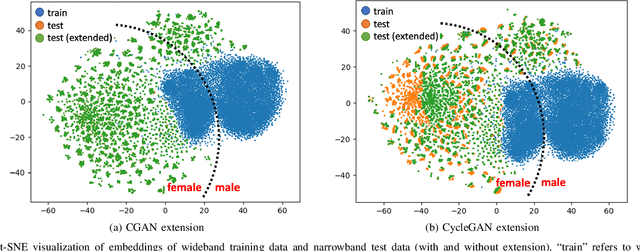
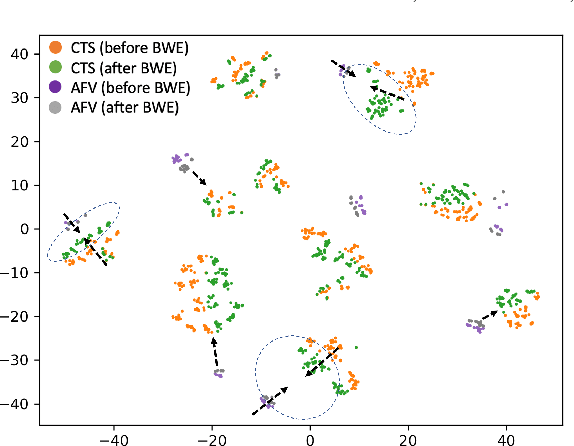
Automatic Speaker Verification (ASV) technology has become commonplace in virtual assistants. However, its performance suffers when there is a mismatch between the train and test domains. Mixed bandwidth training, i.e., pooling training data from both domains, is a preferred choice for developing a universal model that works for both narrowband and wideband domains. We propose complementing this technique by performing neural upsampling of narrowband signals, also known as bandwidth extension. Our main goal is to discover and analyze high-performing time-domain Generative Adversarial Network (GAN) based models to improve our downstream state-of-the-art ASV system. We choose GANs since they (1) are powerful for learning conditional distribution and (2) allow flexible plug-in usage as a pre-processor during the training of downstream task (ASV) with data augmentation. Prior works mainly focus on feature-domain bandwidth extension and limited experimental setups. We address these limitations by 1) using time-domain extension models, 2) reporting results on three real test sets, 2) extending training data, and 3) devising new test-time schemes. We compare supervised (conditional GAN) and unsupervised GANs (CycleGAN) and demonstrate average relative improvement in Equal Error Rate of 8.6% and 7.7%, respectively. For further analysis, we study changes in spectrogram visual quality, audio perceptual quality, t-SNE embeddings, and ASV score distributions. We show that our bandwidth extension leads to phenomena such as a shift of telephone (test) embeddings towards wideband (train) signals, a negative correlation of perceptual quality with downstream performance, and condition-independent score calibration.
Non-Contrastive Self-Supervised Learning of Utterance-Level Speech Representations
Aug 10, 2022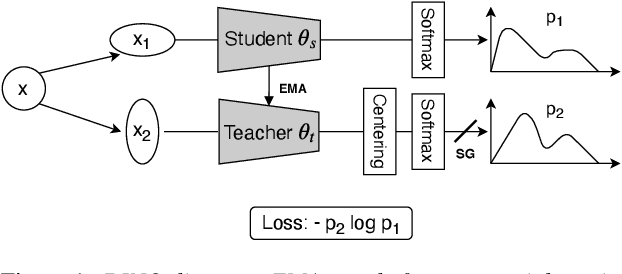
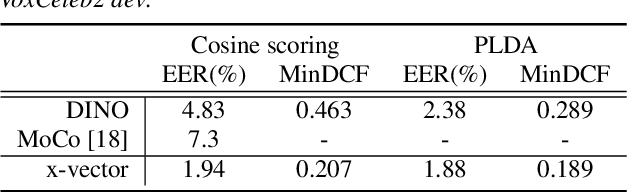
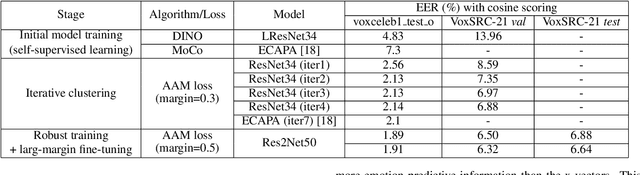
Considering the abundance of unlabeled speech data and the high labeling costs, unsupervised learning methods can be essential for better system development. One of the most successful methods is contrastive self-supervised methods, which require negative sampling: sampling alternative samples to contrast with the current sample (anchor). However, it is hard to ensure if all the negative samples belong to classes different from the anchor class without labels. This paper applies a non-contrastive self-supervised learning method on an unlabeled speech corpus to learn utterance-level embeddings. We used DIstillation with NO labels (DINO), proposed in computer vision, and adapted it to the speech domain. Unlike the contrastive methods, DINO does not require negative sampling. These embeddings were evaluated on speaker verification and emotion recognition. In speaker verification, the unsupervised DINO embedding with cosine scoring provided 4.38% EER on the VoxCeleb1 test trial. This outperforms the best contrastive self-supervised method by 40% relative in EER. An iterative pseudo-labeling training pipeline, not requiring speaker labels, further improved the EER to 1.89%. In emotion recognition, the DINO embedding performed 60.87, 79.21, and 56.98% in micro-f1 score on IEMOCAP, Crema-D, and MSP-Podcast, respectively. The results imply the generality of the DINO embedding to different speech applications.
Joint domain adaptation and speech bandwidth extension using time-domain GANs for speaker verification
Mar 30, 2022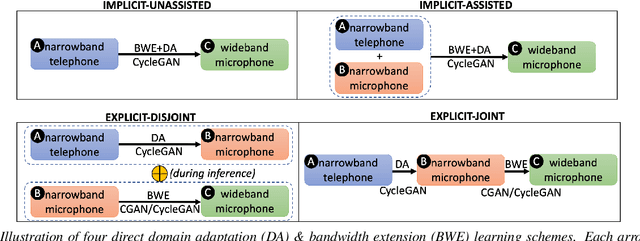
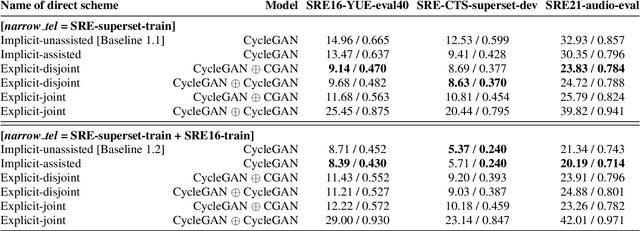
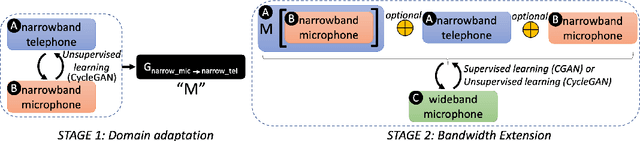

Speech systems developed for a particular choice of acoustic domain and sampling frequency do not translate easily to others. The usual practice is to learn domain adaptation and bandwidth extension models independently. Contrary to this, we propose to learn both tasks together. Particularly, we learn to map narrowband conversational telephone speech to wideband microphone speech. We developed parallel and non-parallel learning solutions which utilize both paired and unpaired data. First, we first discuss joint and disjoint training of multiple generative models for our tasks. Then, we propose a two-stage learning solution where we use a pre-trained domain adaptation system for pre-processing in bandwidth extension training. We evaluated our schemes on a Speaker Verification downstream task. We used the JHU-MIT experimental setup for NIST SRE21, which comprises SRE16, SRE-CTS Superset and SRE21. Our results provide the first evidence that learning both tasks is better than learning just one. On SRE16, our best system achieves 22% relative improvement in Equal Error Rate w.r.t. a direct learning baseline and 8% w.r.t. a strong bandwidth expansion system.
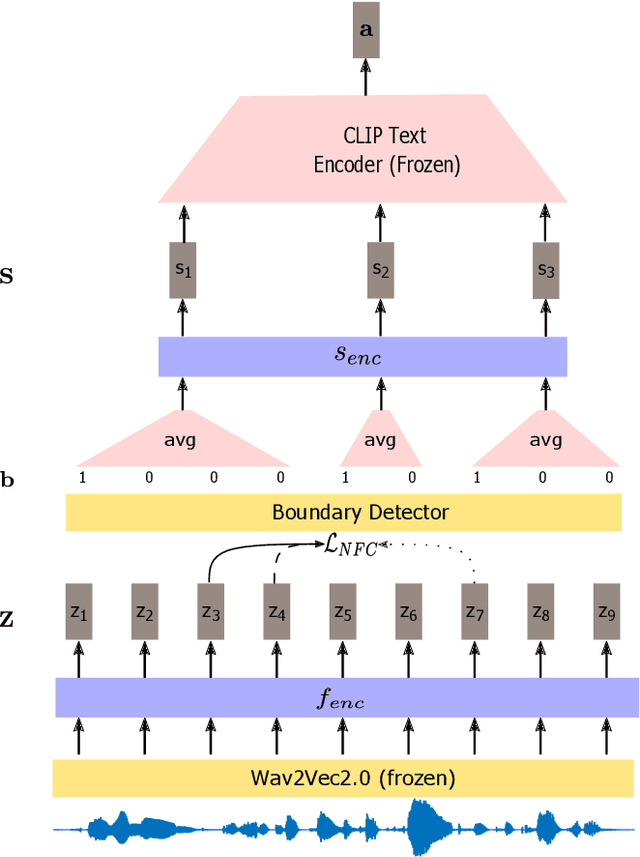
Unsupervised Speech Segmentation and Variable Rate Representation Learning using Segmental Contrastive Predictive Coding
Oct 08, 2021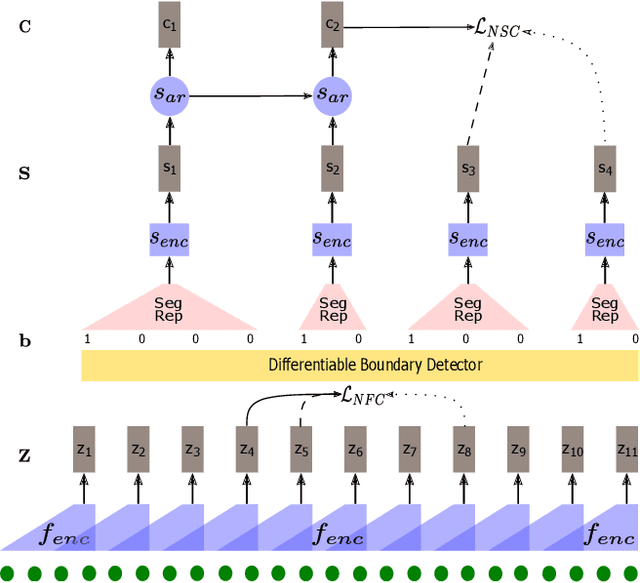
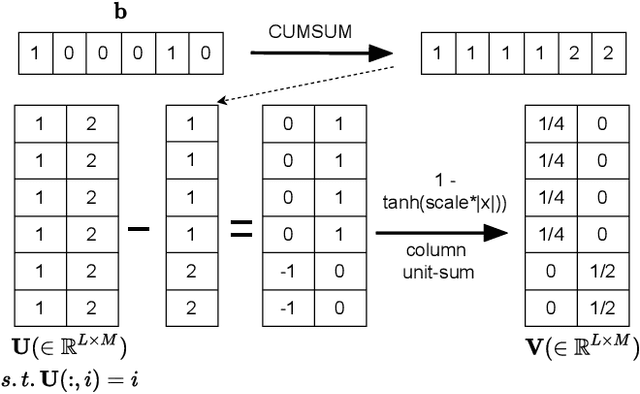
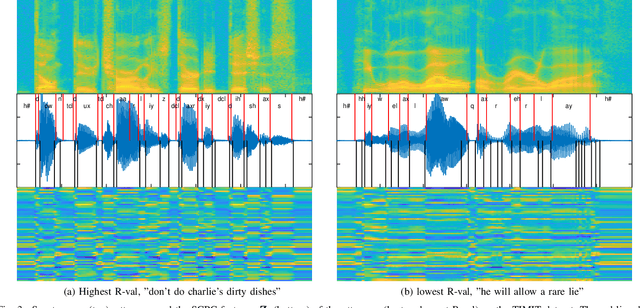
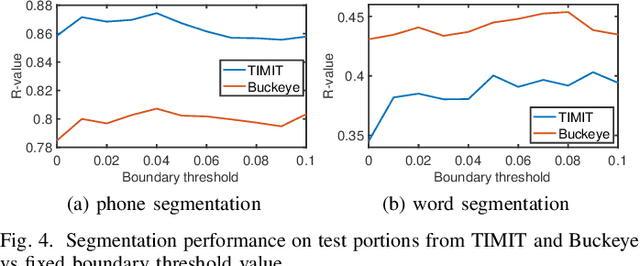
Typically, unsupervised segmentation of speech into the phone and word-like units are treated as separate tasks and are often done via different methods which do not fully leverage the inter-dependence of the two tasks. Here, we unify them and propose a technique that can jointly perform both, showing that these two tasks indeed benefit from each other. Recent attempts employ self-supervised learning, such as contrastive predictive coding (CPC), where the next frame is predicted given past context. However, CPC only looks at the audio signal's frame-level structure. We overcome this limitation with a segmental contrastive predictive coding (SCPC) framework to model the signal structure at a higher level, e.g., phone level. A convolutional neural network learns frame-level representation from the raw waveform via noise-contrastive estimation (NCE). A differentiable boundary detector finds variable-length segments, which are then used to optimize a segment encoder via NCE to learn segment representations. The differentiable boundary detector allows us to train frame-level and segment-level encoders jointly. Experiments show that our single model outperforms existing phone and word segmentation methods on TIMIT and Buckeye datasets. We discover that phone class impacts the boundary detection performance, and the boundaries between successive vowels or semivowels are the most difficult to identify. Finally, we use SCPC to extract speech features at the segment level rather than at uniformly spaced frame level (e.g., 10 ms) and produce variable rate representations that change according to the contents of the utterance. We can lower the feature extraction rate from the typical 100 Hz to as low as 14.5 Hz on average while still outperforming the MFCC features on the linear phone classification task.
Beyond Isolated Utterances: Conversational Emotion Recognition
Sep 13, 2021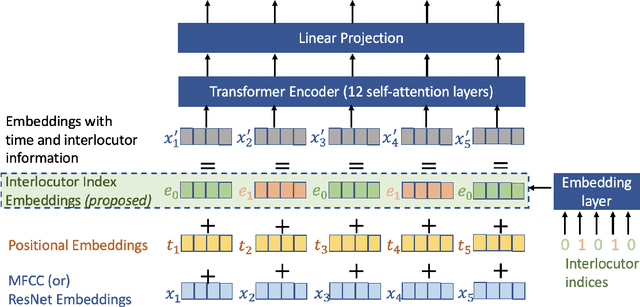

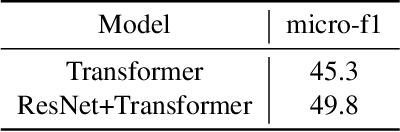
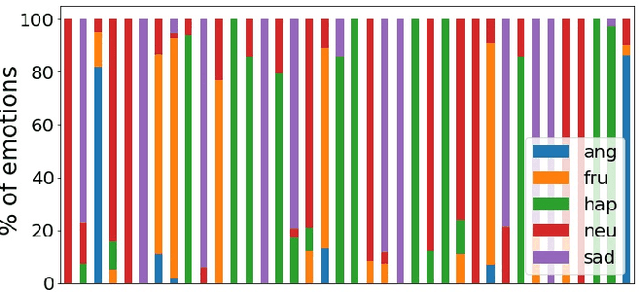
Speech emotion recognition is the task of recognizing the speaker's emotional state given a recording of their utterance. While most of the current approaches focus on inferring emotion from isolated utterances, we argue that this is not sufficient to achieve conversational emotion recognition (CER) which deals with recognizing emotions in conversations. In this work, we propose several approaches for CER by treating it as a sequence labeling task. We investigated transformer architecture for CER and, compared it with ResNet-34 and BiLSTM architectures in both contextual and context-less scenarios using IEMOCAP corpus. Based on the inner workings of the self-attention mechanism, we proposed DiverseCatAugment (DCA), an augmentation scheme, which improved the transformer model performance by an absolute 3.3% micro-f1 on conversations and 3.6% on isolated utterances. We further enhanced the performance by introducing an interlocutor-aware transformer model where we learn a dictionary of interlocutor index embeddings to exploit diarized conversations.
Representation Learning to Classify and Detect Adversarial Attacks against Speaker and Speech Recognition Systems
Jul 09, 2021
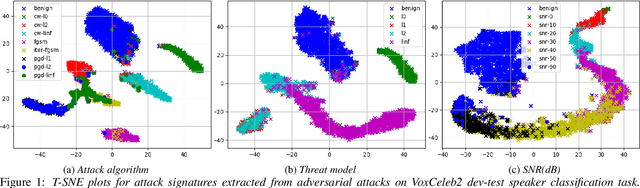
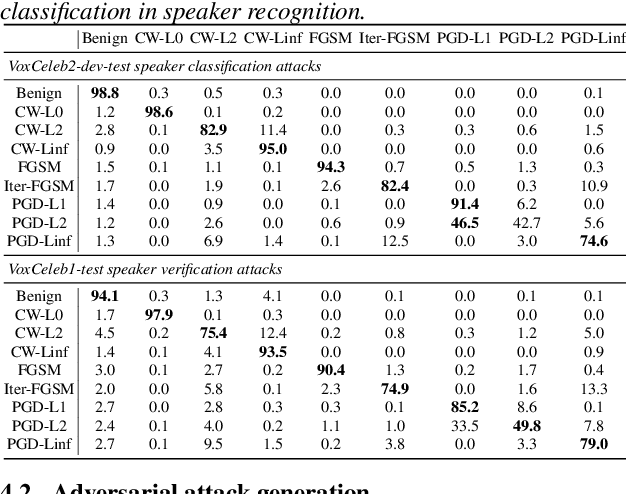
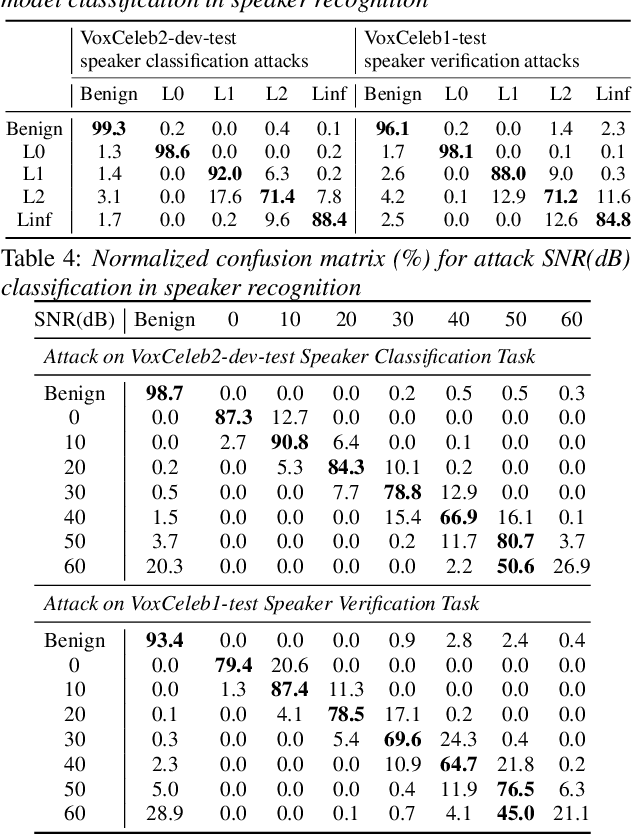
Adversarial attacks have become a major threat for machine learning applications. There is a growing interest in studying these attacks in the audio domain, e.g, speech and speaker recognition; and find defenses against them. In this work, we focus on using representation learning to classify/detect attacks w.r.t. the attack algorithm, threat model or signal-to-adversarial-noise ratio. We found that common attacks in the literature can be classified with accuracies as high as 90%. Also, representations trained to classify attacks against speaker identification can be used also to classify attacks against speaker verification and speech recognition. We also tested an attack verification task, where we need to decide whether two speech utterances contain the same attack. We observed that our models did not generalize well to attack algorithms not included in the attack representation model training. Motivated by this, we evaluated an unknown attack detection task. We were able to detect unknown attacks with equal error rates of about 19%, which is promising.