 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTA-Vid: Generalized Test-Time Adaptation for Video Reasoning
Apr 01, 2026Recent video reasoning models have shown strong results on temporal and multimodal understanding, yet they depend on large-scale supervised data and multi-stage training pipelines, making them costly to train and difficult to adapt to new domains. In this work, we leverage the paradigm of Test-Time Reinforcement Learning on video-language data to allow for adapting a pretrained model to incoming video samples at test-time without explicit labels. The proposed test-time adaptation for video approach (TTA-Vid) combines two components that work simultaneously: (1) a test-time adaptation that performs step-by-step reasoning at inference time on multiple frame subsets. We then use a batch-aware frequency-based reward computed across different frame subsets as pseudo ground truth to update the model. It shows that the resulting model trained on a single batch or even a single sample from a dataset, is able to generalize at test-time to the whole dataset and even across datasets. Because the adaptation occurs entirely at test time, our method requires no ground-truth annotations or dedicated training splits. Additionally, we propose a multi-armed bandit strategy for adaptive frame selection that learns to prioritize informative frames, guided by the same reward formulation. Our evaluation shows that TTA-Vid yields consistent improvements across various video reasoning tasks and is able to outperform current state-of-the-art methods trained on large-scale data. This highlights the potential of test-time reinforcement learning for temporal multimodal understanding.
USAD: Universal Speech and Audio Representation via Distillation
Jun 23, 2025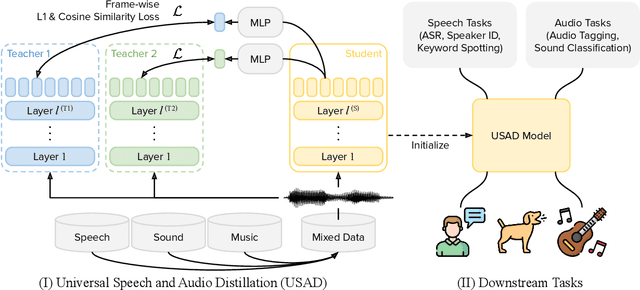
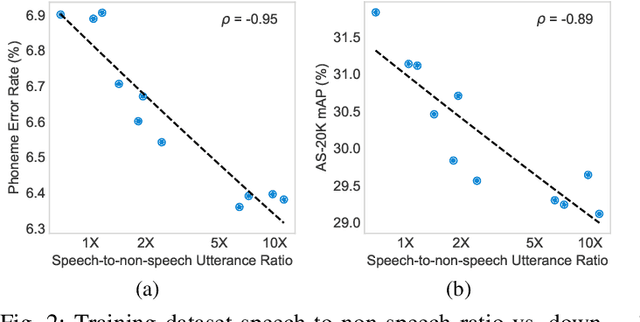
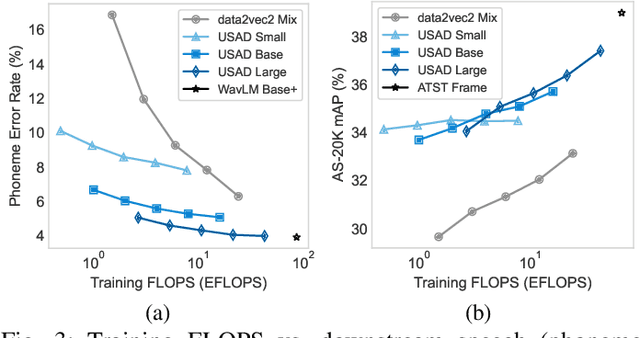
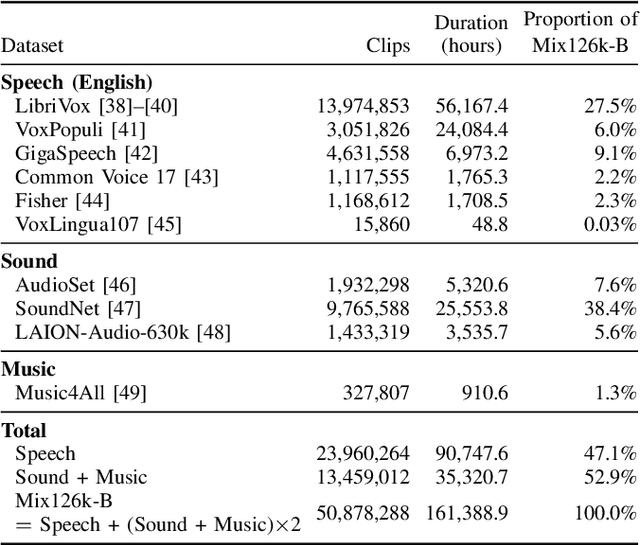
Self-supervised learning (SSL) has revolutionized audio representations, yet models often remain domain-specific, focusing on either speech or non-speech tasks. In this work, we present Universal Speech and Audio Distillation (USAD), a unified approach to audio representation learning that integrates diverse audio types - speech, sound, and music - into a single model. USAD employs efficient layer-to-layer distillation from domain-specific SSL models to train a student on a comprehensive audio dataset. USAD offers competitive performance across various benchmarks and datasets, including frame and instance-level speech processing tasks, audio tagging, and sound classification, achieving near state-of-the-art results with a single encoder on SUPERB and HEAR benchmarks.
Omni-R1: Do You Really Need Audio to Fine-Tune Your Audio LLM?
May 14, 2025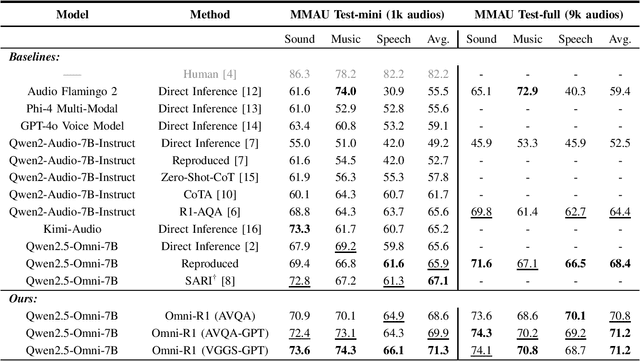
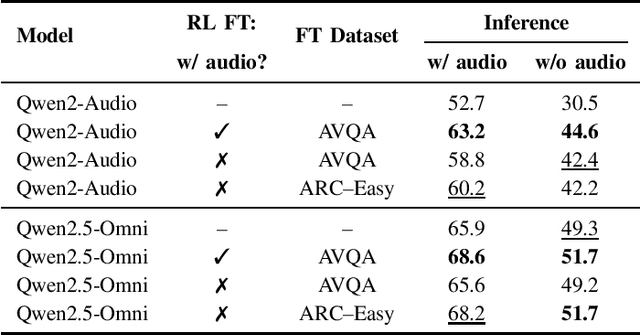
We propose Omni-R1 which fine-tunes a recent multi-modal LLM, Qwen2.5-Omni, on an audio question answering dataset with the reinforcement learning method GRPO. This leads to new State-of-the-Art performance on the recent MMAU benchmark. Omni-R1 achieves the highest accuracies on the sounds, music, speech, and overall average categories, both on the Test-mini and Test-full splits. To understand the performance improvement, we tested models both with and without audio and found that much of the performance improvement from GRPO could be attributed to better text-based reasoning. We also made a surprising discovery that fine-tuning without audio on a text-only dataset was effective at improving the audio-based performance.
CAV-MAE Sync: Improving Contrastive Audio-Visual Mask Autoencoders via Fine-Grained Alignment
May 02, 2025Recent advances in audio-visual learning have shown promising results in learning representations across modalities. However, most approaches rely on global audio representations that fail to capture fine-grained temporal correspondences with visual frames. Additionally, existing methods often struggle with conflicting optimization objectives when trying to jointly learn reconstruction and cross-modal alignment. In this work, we propose CAV-MAE Sync as a simple yet effective extension of the original CAV-MAE framework for self-supervised audio-visual learning. We address three key challenges: First, we tackle the granularity mismatch between modalities by treating audio as a temporal sequence aligned with video frames, rather than using global representations. Second, we resolve conflicting optimization goals by separating contrastive and reconstruction objectives through dedicated global tokens. Third, we improve spatial localization by introducing learnable register tokens that reduce semantic load on patch tokens. We evaluate the proposed approach on AudioSet, VGG Sound, and the ADE20K Sound dataset on zero-shot retrieval, classification and localization tasks demonstrating state-of-the-art performance and outperforming more complex architectures.
mWhisper-Flamingo for Multilingual Audio-Visual Noise-Robust Speech Recognition
Feb 03, 2025Audio-Visual Speech Recognition (AVSR) combines lip-based video with audio and can improve performance in noise, but most methods are trained only on English data. One limitation is the lack of large-scale multilingual video data, which makes it hard hard to train models from scratch. In this work, we propose mWhisper-Flamingo for multilingual AVSR which combines the strengths of a pre-trained audio model (Whisper) and video model (AV-HuBERT). To enable better multi-modal integration and improve the noisy multilingual performance, we introduce decoder modality dropout where the model is trained both on paired audio-visual inputs and separate audio/visual inputs. mWhisper-Flamingo achieves state-of-the-art WER on MuAViC, an AVSR dataset of 9 languages. Audio-visual mWhisper-Flamingo consistently outperforms audio-only Whisper on all languages in noisy conditions.
State-Space Large Audio Language Models
Nov 24, 2024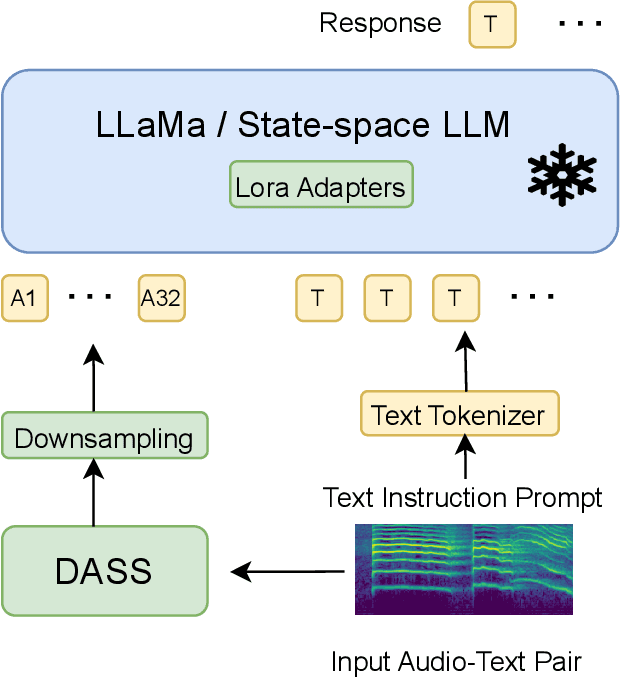
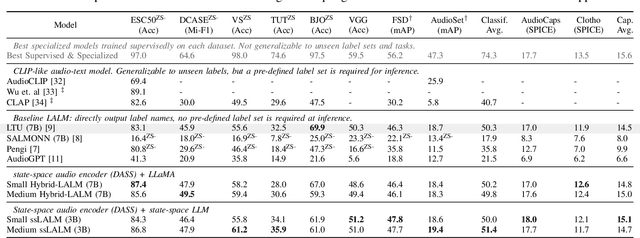

Large Audio Language Models (LALM) combine the audio perception models and the Large Language Models (LLM) and show a remarkable ability to reason about the input audio, infer the meaning, and understand the intent. However, these systems rely on Transformers which scale quadratically with the input sequence lengths which poses computational challenges in deploying these systems in memory and time-constrained scenarios. Recently, the state-space models (SSMs) have emerged as an alternative to transformer networks. While there have been successful attempts to replace transformer-based audio perception models with state-space ones, state-space-based LALMs remain unexplored. First, we begin by replacing the transformer-based audio perception module and then replace the transformer-based LLM and propose the first state-space-based LALM. Experimental results demonstrate that space-based LALM despite having a significantly lower number of parameters performs competitively with transformer-based LALMs on close-ended tasks on a variety of datasets.
DASS: Distilled Audio State Space Models Are Stronger and More Duration-Scalable Learners
Jul 04, 2024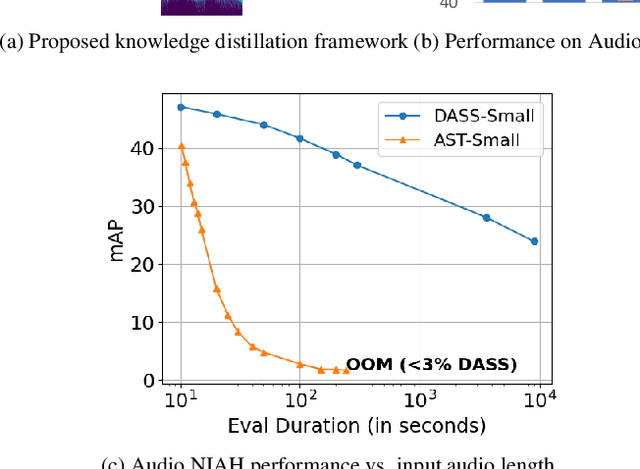

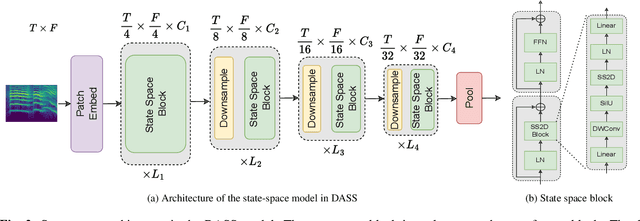
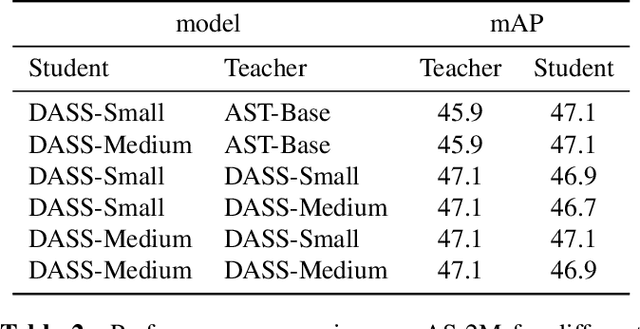
State-space models (SSMs) have emerged as an alternative to Transformers for audio modeling due to their high computational efficiency with long inputs. While recent efforts on Audio SSMs have reported encouraging results, two main limitations remain: First, in 10-second short audio tagging tasks, Audio SSMs still underperform compared to Transformer-based models such as Audio Spectrogram Transformer (AST). Second, although Audio SSMs theoretically support long audio inputs, their actual performance with long audio has not been thoroughly evaluated. To address these limitations, in this paper, 1) We applied knowledge distillation in audio space model training, resulting in a model called Knowledge Distilled Audio SSM (DASS). To the best of our knowledge, it is the first SSM that outperforms the Transformers on AudioSet and achieves an mAP of 47.6; and 2) We designed a new test called Audio Needle In A Haystack (Audio NIAH). We find that DASS, trained with only 10-second audio clips, can retrieve sound events in audio recordings up to 2.5 hours long, while the AST model fails when the input is just 50 seconds, demonstrating SSMs are indeed more duration scalable.
Audio-Visual Neural Syntax Acquisition
Oct 11, 2023



We study phrase structure induction from visually-grounded speech. The core idea is to first segment the speech waveform into sequences of word segments, and subsequently induce phrase structure using the inferred segment-level continuous representations. We present the Audio-Visual Neural Syntax Learner (AV-NSL) that learns phrase structure by listening to audio and looking at images, without ever being exposed to text. By training on paired images and spoken captions, AV-NSL exhibits the capability to infer meaningful phrase structures that are comparable to those derived by naturally-supervised text parsers, for both English and German. Our findings extend prior work in unsupervised language acquisition from speech and grounded grammar induction, and present one approach to bridge the gap between the two topics.
Leveraging Pretrained Image-text Models for Improving Audio-Visual Learning
Sep 08, 2023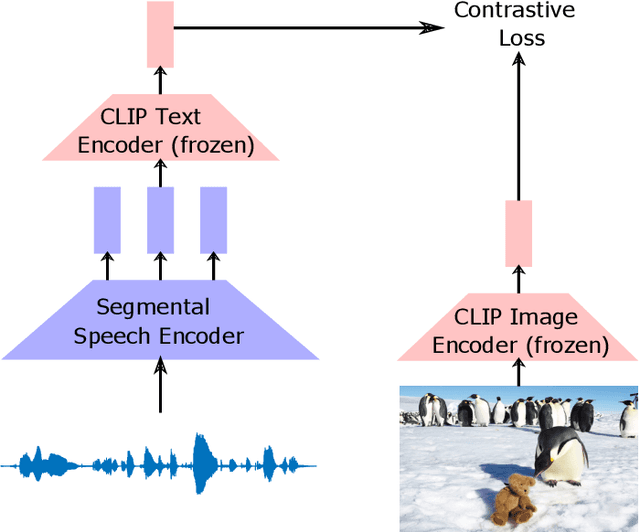
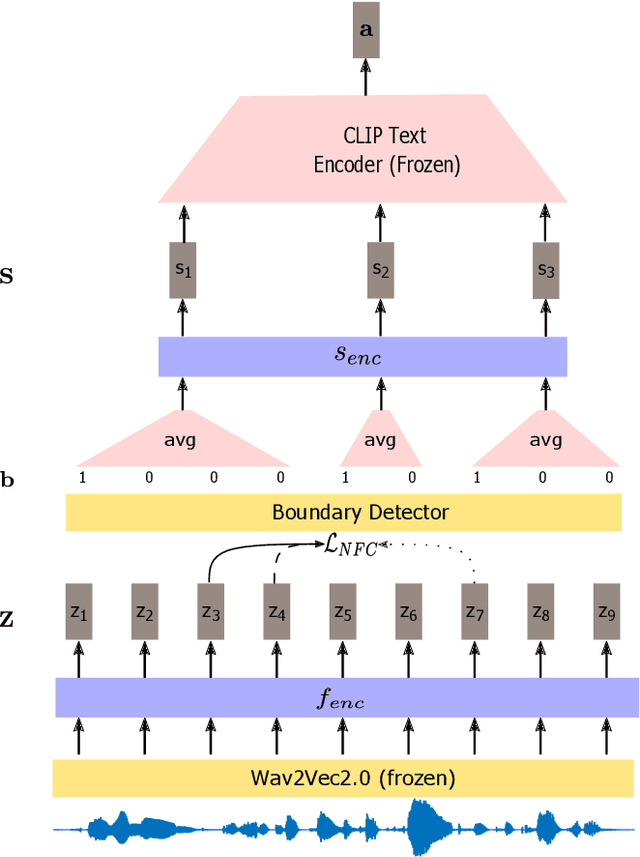
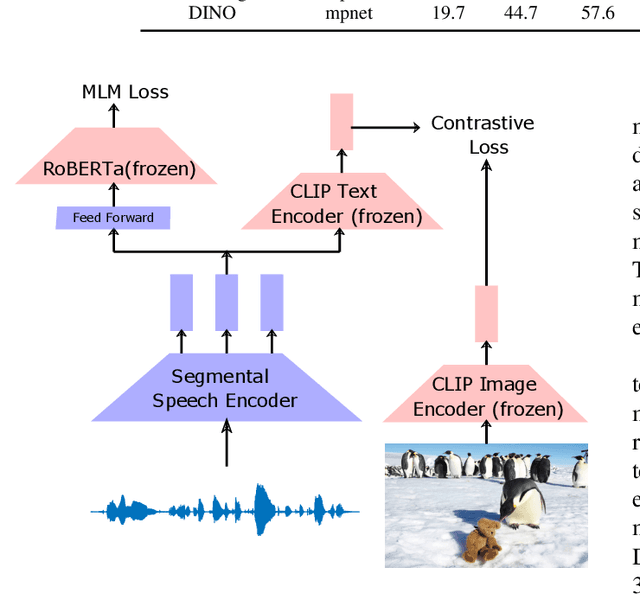
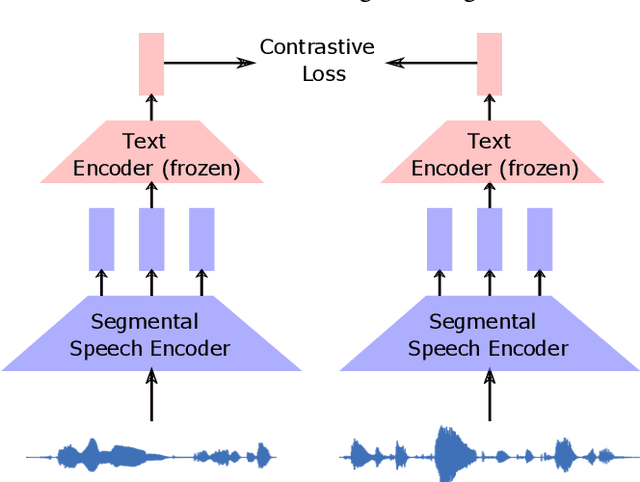
Visually grounded speech systems learn from paired images and their spoken captions. Recently, there have been attempts to utilize the visually grounded models trained from images and their corresponding text captions, such as CLIP, to improve speech-based visually grounded models' performance. However, the majority of these models only utilize the pretrained image encoder. Cascaded SpeechCLIP attempted to generate localized word-level information and utilize both the pretrained image and text encoders. Despite using both, they noticed a substantial drop in retrieval performance. We proposed Segmental SpeechCLIP which used a hierarchical segmental speech encoder to generate sequences of word-like units. We used the pretrained CLIP text encoder on top of these word-like unit representations and showed significant improvements over the cascaded variant of SpeechCLIP. Segmental SpeechCLIP directly learns the word embeddings as input to the CLIP text encoder bypassing the vocabulary embeddings. Here, we explore mapping audio to CLIP vocabulary embeddings via regularization and quantization. As our objective is to distill semantic information into the speech encoders, we explore the usage of large unimodal pretrained language models as the text encoders. Our method enables us to bridge image and text encoders e.g. DINO and RoBERTa trained with uni-modal data. Finally, we extend our framework in audio-only settings where only pairs of semantically related audio are available. Experiments show that audio-only systems perform close to the audio-visual system.
Regularizing Contrastive Predictive Coding for Speech Applications
Apr 26, 2023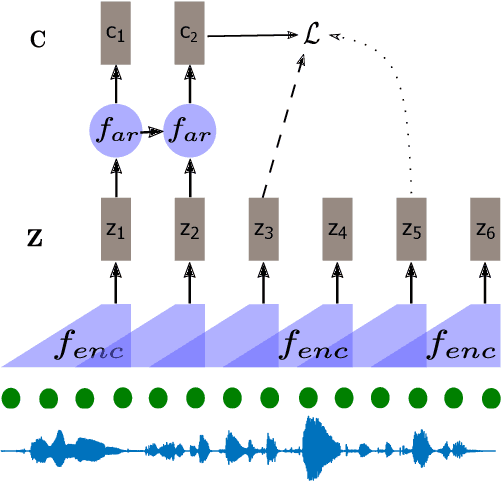
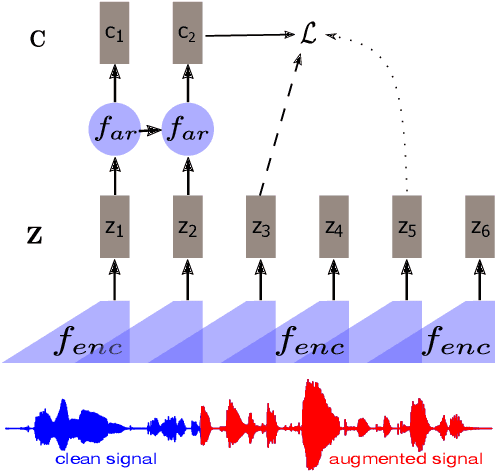
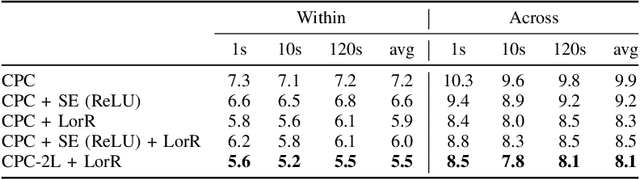
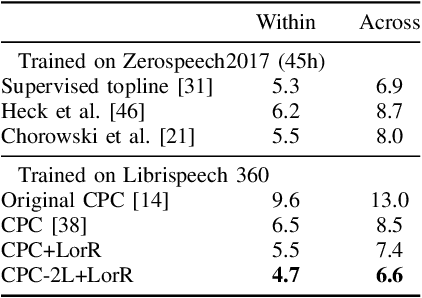
Self-supervised methods such as Contrastive predictive Coding (CPC) have greatly improved the quality of the unsupervised representations. These representations significantly reduce the amount of labeled data needed for downstream task performance, such as automatic speech recognition. CPC learns representations by learning to predict future frames given current frames. Based on the observation that the acoustic information, e.g., phones, changes slower than the feature extraction rate in CPC, we propose regularization techniques that impose slowness constraints on the features. Here we propose two regularization techniques: Self-expressing constraint and Left-or-Right regularization. We evaluate the proposed model on ABX and linear phone classification tasks, acoustic unit discovery, and automatic speech recognition. The regularized CPC trained on 100 hours of unlabeled data matches the performance of the baseline CPC trained on 360 hours of unlabeled data. We also show that our regularization techniques are complementary to data augmentation and can further boost the system's performance. In monolingual, cross-lingual, or multilingual settings, with/without data augmentation, regardless of the amount of data used for training, our regularized models outperformed the baseline CPC models on the ABX task.