 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming State Inertia in Full-Duplex Spoken Language Models via Activation Steering
Jun 09, 2026Full-duplex spoken language models (FD-SLMs) enable seamless speech interaction by allowing models to listen and speak simultaneously, yet the internal mechanism by which they coordinate listening and speaking remains underexplored. We analyze the predictive behavior encoded in FD-SLM hidden representations and find that they exhibit stream-specific predictive patterns: during listening, they preferentially predict the incoming user stream, whereas during speaking, they preferentially predict the model output stream. Building on this observation, we show that FD-SLMs dynamically modulate their internal predictive focus between two states: a generative state aligned with model output generation and a perceptive state aligned with incoming user input. However, this modulation can lag behind abrupt changes in conversational context. During user interruptions, the model remains transiently biased toward the generative state before transitioning into the perceptive state, causing it to miss the beginning of the incoming input. We term this delayed internal transition state inertia. To quantify its downstream impact, we introduce the Zero-Buffer Benchmark (ZBB), a diagnostic benchmark for evaluating immediate interruption comprehension when user speech begins abruptly. We evaluate this setting using response correctness and initial-word occurrence rate (IWOR). Finally, we mitigate state inertia through activation steering with a perception vector, a training-free intervention with little additional computational overhead. Across multiple state-of-the-art FD-SLMs, activation steering substantially improves interruption handling; for example, on PersonaPlex, it improves correctness from 28% to 45% and IWOR from 40% to 72% without any fine-tuning.
USAD 2.0: Scaling Representation Distillation for Universal Audio Understanding
Jun 04, 2026Audio encoders are critical to modern audio applications as large language models (LLMs) increasingly rely on a single encoder for diverse inputs. While self-supervised learning (SSL) has yielded strong domain-specific encoders like speech or music experts, multi-domain approaches like USAD and SPEAR remain limited in coverage and evaluation. Recent studies also suggest supervised encoders align better with audio LLMs. We present USAD 2.0, a universal encoder integrating knowledge from both SSL and supervised foundation models. USAD 2.0 introduces domain-aware distillation to address teacher mismatch, extends coverage to the music domain, and adds second-stage supervised distillation for downstream use. We further scale the model to one billion parameters via depth scaling. Experiments show USAD 2.0 achieves strong or state-of-the-art performance across probing and LLM-based evaluations.
Voxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Schrodinger Audio-Visual Editor: Object-Level Audiovisual Removal
Dec 14, 2025Joint editing of audio and visual content is crucial for precise and controllable content creation. This new task poses challenges due to the limitations of paired audio-visual data before and after targeted edits, and the heterogeneity across modalities. To address the data and modeling challenges in joint audio-visual editing, we introduce SAVEBench, a paired audiovisual dataset with text and mask conditions to enable object-grounded source-to-target learning. With SAVEBench, we train the Schrodinger Audio-Visual Editor (SAVE), an end-to-end flow-matching model that edits audio and video in parallel while keeping them aligned throughout processing. SAVE incorporates a Schrodinger Bridge that learns a direct transport from source to target audiovisual mixtures. Our evaluation demonstrates that the proposed SAVE model is able to remove the target objects in audio and visual content while preserving the remaining content, with stronger temporal synchronization and audiovisual semantic correspondence compared with pairwise combinations of an audio editor and a video editor.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
USAD: Universal Speech and Audio Representation via Distillation
Jun 23, 2025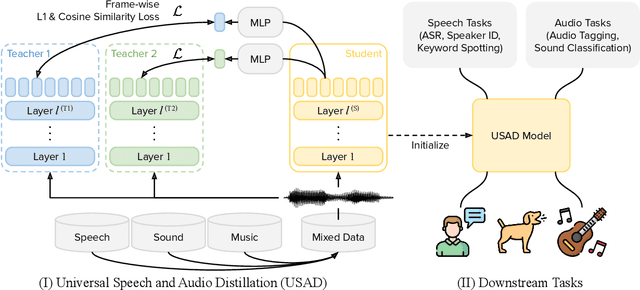
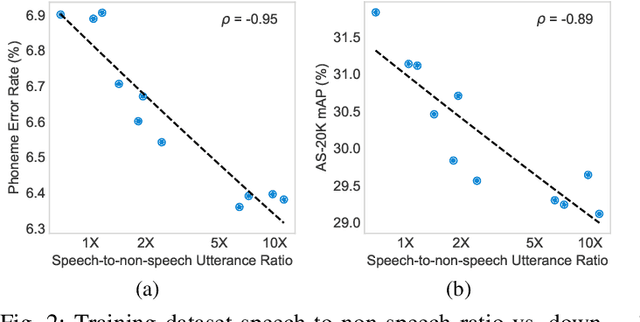
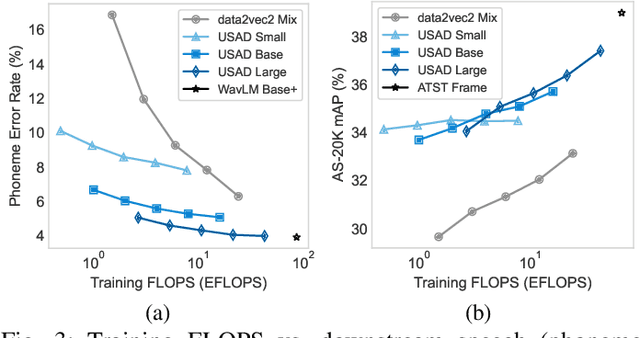
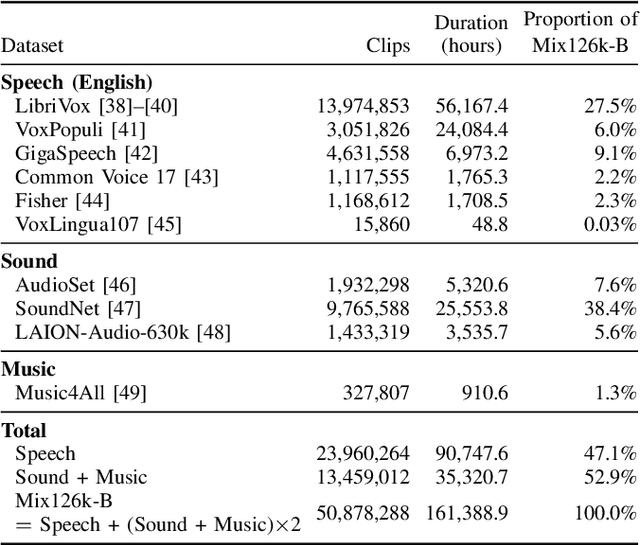
Self-supervised learning (SSL) has revolutionized audio representations, yet models often remain domain-specific, focusing on either speech or non-speech tasks. In this work, we present Universal Speech and Audio Distillation (USAD), a unified approach to audio representation learning that integrates diverse audio types - speech, sound, and music - into a single model. USAD employs efficient layer-to-layer distillation from domain-specific SSL models to train a student on a comprehensive audio dataset. USAD offers competitive performance across various benchmarks and datasets, including frame and instance-level speech processing tasks, audio tagging, and sound classification, achieving near state-of-the-art results with a single encoder on SUPERB and HEAR benchmarks.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Full-Duplex-Bench: A Benchmark to Evaluate Full-duplex Spoken Dialogue Models on Turn-taking Capabilities
Mar 06, 2025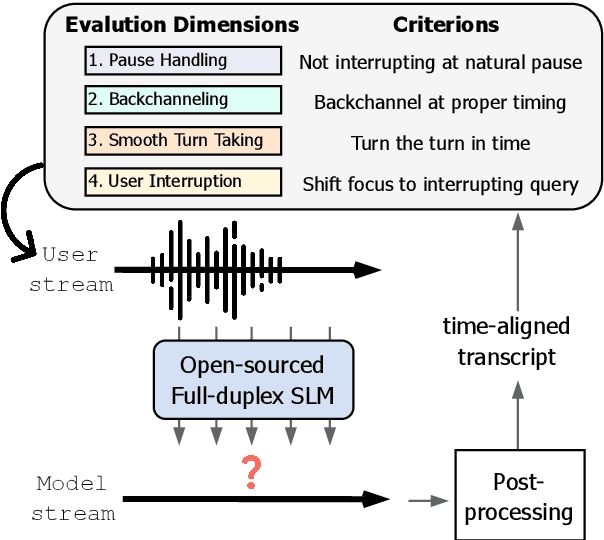
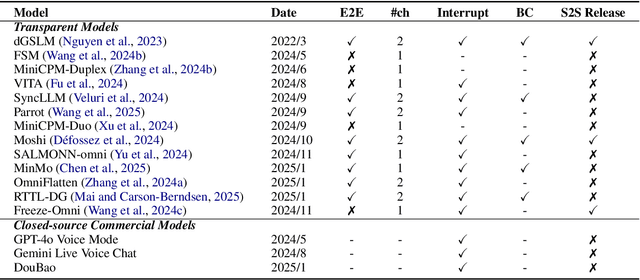
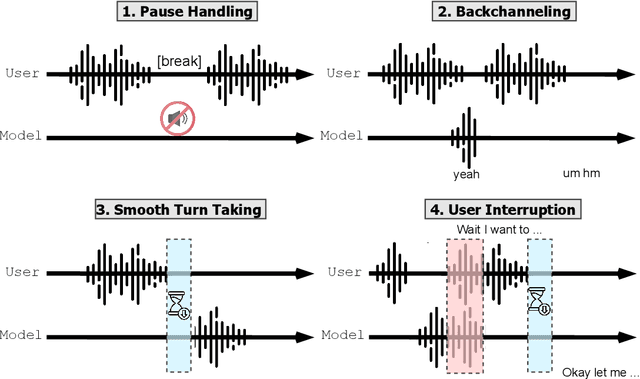

Spoken dialogue modeling introduces unique challenges beyond text-based language modeling, demanding robust turn-taking, backchanneling, and real-time interaction. Although most Spoken Dialogue Models (SDMs) rely on half-duplex processing (handling speech one turn at a time), emerging full-duplex SDMs can listen and speak simultaneously, enabling more natural and engaging conversations. However, current evaluations of such models remain limited, often focusing on turn-based metrics or high-level corpus analyses (e.g., turn gaps, pauses). To address this gap, we present Full-Duplex-Bench, a new benchmark that systematically evaluates key conversational behaviors: pause handling, backchanneling, turn-taking, and interruption management. Our framework uses automatic metrics for consistent and reproducible assessments of SDMs' interactive performance. By offering an open and standardized evaluation benchmark, we aim to advance spoken dialogue modeling and encourage the development of more interactive and natural dialogue systems.