 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodec-SUPERB: An In-Depth Analysis of Sound Codec Models
Feb 20, 2024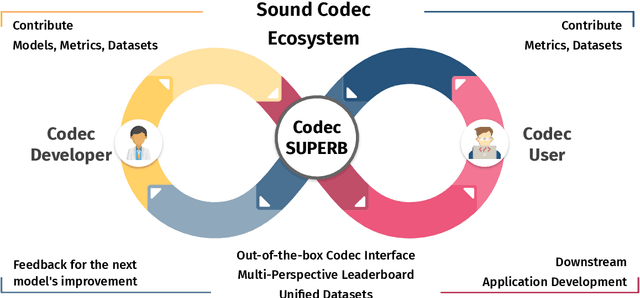
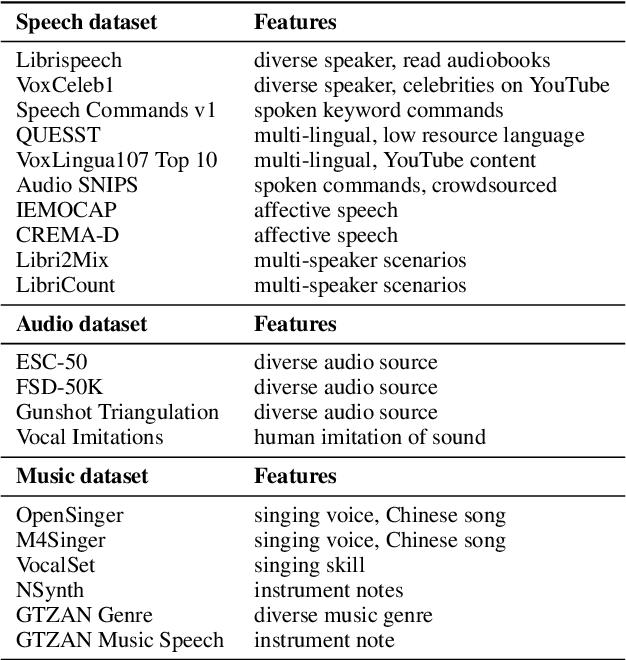
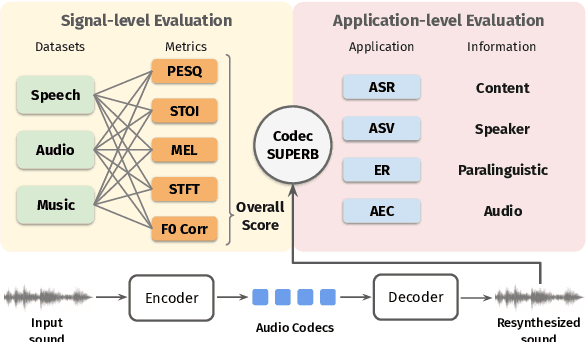
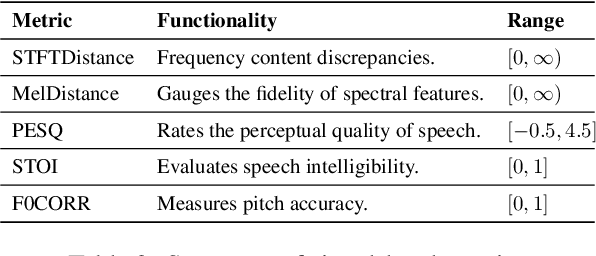
The sound codec's dual roles in minimizing data transmission latency and serving as tokenizers underscore its critical importance. Recent years have witnessed significant developments in codec models. The ideal sound codec should preserve content, paralinguistics, speakers, and audio information. However, the question of which codec achieves optimal sound information preservation remains unanswered, as in different papers, models are evaluated on their selected experimental settings. This study introduces Codec-SUPERB, an acronym for Codec sound processing Universal PERformance Benchmark. It is an ecosystem designed to assess codec models across representative sound applications and signal-level metrics rooted in sound domain knowledge.Codec-SUPERB simplifies result sharing through an online leaderboard, promoting collaboration within a community-driven benchmark database, thereby stimulating new development cycles for codecs. Furthermore, we undertake an in-depth analysis to offer insights into codec models from both application and signal perspectives, diverging from previous codec papers mainly concentrating on signal-level comparisons. Finally, we will release codes, the leaderboard, and data to accelerate progress within the community.
GSQA: An End-to-End Model for Generative Spoken Question Answering
Dec 25, 2023In recent advancements in spoken question answering (QA), end-to-end models have made significant strides. However, previous research has primarily focused on extractive span selection. While this extractive-based approach is effective when answers are present directly within the input, it falls short in addressing abstractive questions, where answers are not directly extracted but inferred from the given information. To bridge this gap, we introduce the first end-to-end Generative Spoken Question Answering (GSQA) model that empowers the system to engage in abstractive reasoning. The challenge in training our GSQA model lies in the absence of a spoken abstractive QA dataset. We propose using text models for initialization and leveraging the extractive QA dataset to transfer knowledge from the text generative model to the spoken generative model. Experimental results indicate that our model surpasses the previous extractive model by 3% on extractive QA datasets. Furthermore, the GSQA model has only been fine-tuned on the spoken extractive QA dataset. Despite not having seen any spoken abstractive QA data, it can still closely match the performance of the cascade model. In conclusion, our GSQA model shows the potential to generalize to a broad spectrum of questions, thus further expanding the spoken question answering capabilities of abstractive QA. Our code is available at https://voidful.github.io/GSQA