 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Test-Time Scaling: A Survey and a Diversity-Aware Method for Efficient Reasoning
Jun 05, 2025Test-Time Scaling (TTS) improves the reasoning performance of Large Language Models (LLMs) by allocating additional compute during inference. We conduct a structured survey of TTS methods and categorize them into sampling-based, search-based, and trajectory optimization strategies. We observe that reasoning-optimized models often produce less diverse outputs, which limits TTS effectiveness. To address this, we propose ADAPT (A Diversity Aware Prefix fine-Tuning), a lightweight method that applies prefix tuning with a diversity-focused data strategy. Experiments on mathematical reasoning tasks show that ADAPT reaches 80% accuracy using eight times less compute than strong baselines. Our findings highlight the essential role of generative diversity in maximizing TTS effectiveness.
Codec-SUPERB @ SLT 2024: A lightweight benchmark for neural audio codec models
Sep 21, 2024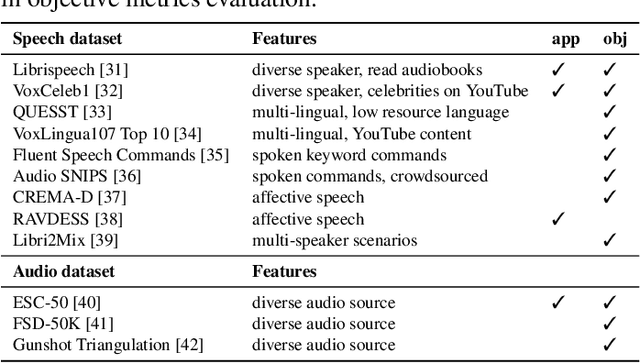
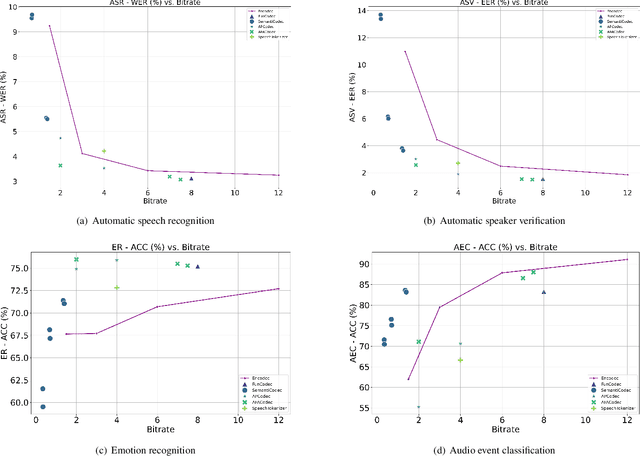
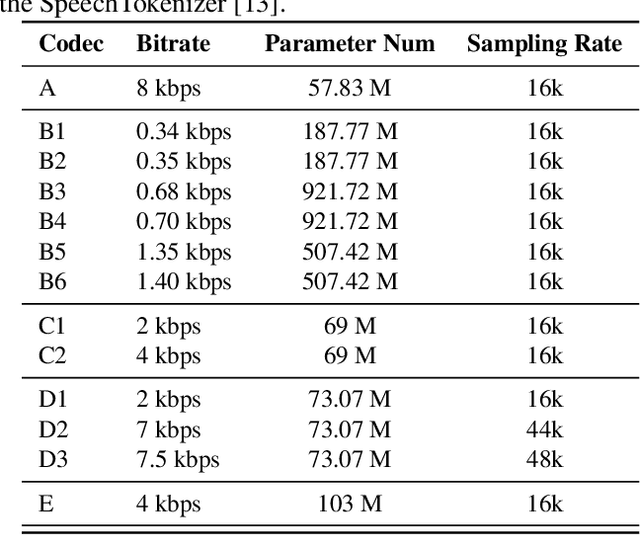
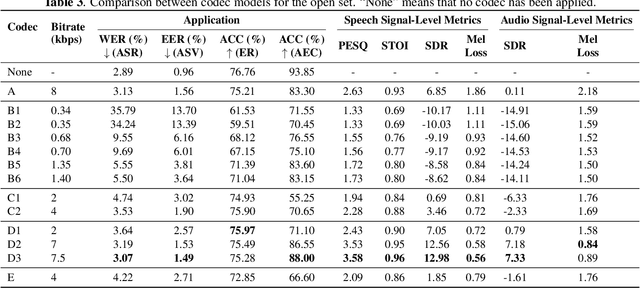
Neural audio codec models are becoming increasingly important as they serve as tokenizers for audio, enabling efficient transmission or facilitating speech language modeling. The ideal neural audio codec should maintain content, paralinguistics, speaker characteristics, and audio information even at low bitrates. Recently, numerous advanced neural codec models have been proposed. However, codec models are often tested under varying experimental conditions. As a result, we introduce the Codec-SUPERB challenge at SLT 2024, designed to facilitate fair and lightweight comparisons among existing codec models and inspire advancements in the field. This challenge brings together representative speech applications and objective metrics, and carefully selects license-free datasets, sampling them into small sets to reduce evaluation computation costs. This paper presents the challenge's rules, datasets, five participant systems, results, and findings.
Researchy Questions: A Dataset of Multi-Perspective, Decompositional Questions for LLM Web Agents
Feb 27, 2024



Existing question answering (QA) datasets are no longer challenging to most powerful Large Language Models (LLMs). Traditional QA benchmarks like TriviaQA, NaturalQuestions, ELI5 and HotpotQA mainly study ``known unknowns'' with clear indications of both what information is missing, and how to find it to answer the question. Hence, good performance on these benchmarks provides a false sense of security. A yet unmet need of the NLP community is a bank of non-factoid, multi-perspective questions involving a great deal of unclear information needs, i.e. ``unknown uknowns''. We claim we can find such questions in search engine logs, which is surprising because most question-intent queries are indeed factoid. We present Researchy Questions, a dataset of search engine queries tediously filtered to be non-factoid, ``decompositional'' and multi-perspective. We show that users spend a lot of ``effort'' on these questions in terms of signals like clicks and session length, and that they are also challenging for GPT-4. We also show that ``slow thinking'' answering techniques, like decomposition into sub-questions shows benefit over answering directly. We release $\sim$ 100k Researchy Questions, along with the Clueweb22 URLs that were clicked.
Codec-SUPERB: An In-Depth Analysis of Sound Codec Models
Feb 20, 2024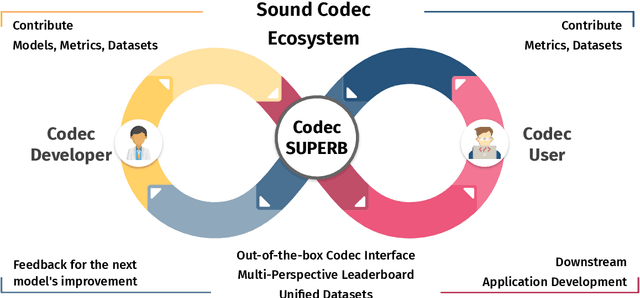
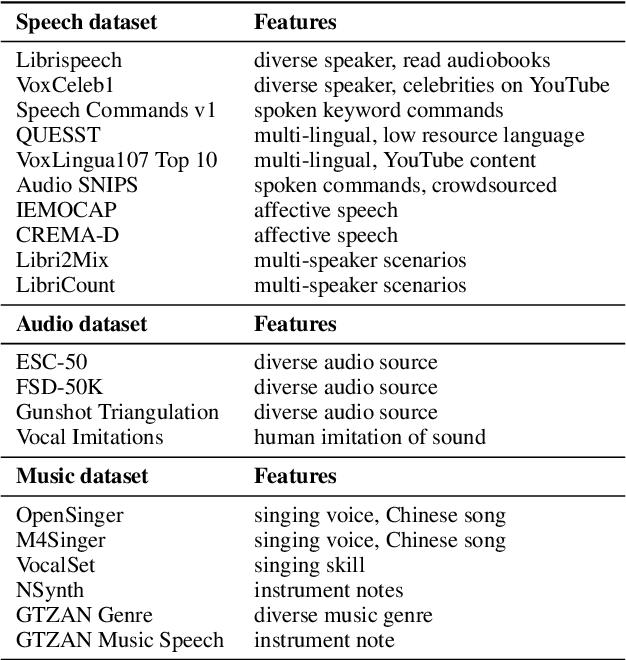
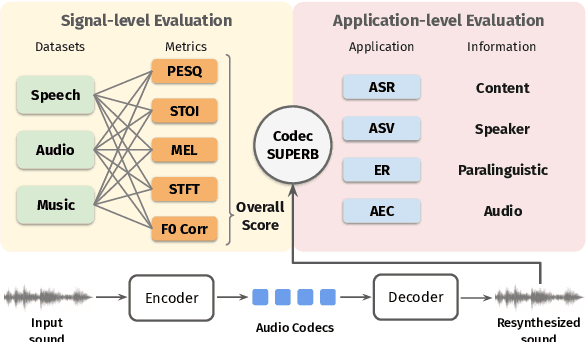
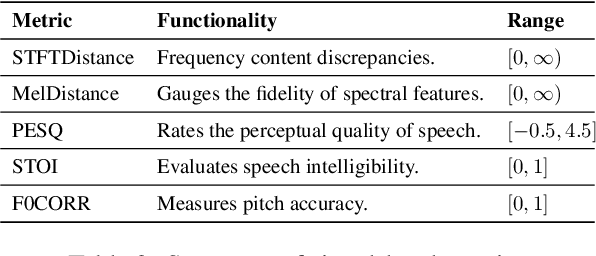
The sound codec's dual roles in minimizing data transmission latency and serving as tokenizers underscore its critical importance. Recent years have witnessed significant developments in codec models. The ideal sound codec should preserve content, paralinguistics, speakers, and audio information. However, the question of which codec achieves optimal sound information preservation remains unanswered, as in different papers, models are evaluated on their selected experimental settings. This study introduces Codec-SUPERB, an acronym for Codec sound processing Universal PERformance Benchmark. It is an ecosystem designed to assess codec models across representative sound applications and signal-level metrics rooted in sound domain knowledge.Codec-SUPERB simplifies result sharing through an online leaderboard, promoting collaboration within a community-driven benchmark database, thereby stimulating new development cycles for codecs. Furthermore, we undertake an in-depth analysis to offer insights into codec models from both application and signal perspectives, diverging from previous codec papers mainly concentrating on signal-level comparisons. Finally, we will release codes, the leaderboard, and data to accelerate progress within the community.
Towards audio language modeling -- an overview
Feb 20, 2024Neural audio codecs are initially introduced to compress audio data into compact codes to reduce transmission latency. Researchers recently discovered the potential of codecs as suitable tokenizers for converting continuous audio into discrete codes, which can be employed to develop audio language models (LMs). Numerous high-performance neural audio codecs and codec-based LMs have been developed. The paper aims to provide a thorough and systematic overview of the neural audio codec models and codec-based LMs.
GSQA: An End-to-End Model for Generative Spoken Question Answering
Dec 25, 2023In recent advancements in spoken question answering (QA), end-to-end models have made significant strides. However, previous research has primarily focused on extractive span selection. While this extractive-based approach is effective when answers are present directly within the input, it falls short in addressing abstractive questions, where answers are not directly extracted but inferred from the given information. To bridge this gap, we introduce the first end-to-end Generative Spoken Question Answering (GSQA) model that empowers the system to engage in abstractive reasoning. The challenge in training our GSQA model lies in the absence of a spoken abstractive QA dataset. We propose using text models for initialization and leveraging the extractive QA dataset to transfer knowledge from the text generative model to the spoken generative model. Experimental results indicate that our model surpasses the previous extractive model by 3% on extractive QA datasets. Furthermore, the GSQA model has only been fine-tuned on the spoken extractive QA dataset. Despite not having seen any spoken abstractive QA data, it can still closely match the performance of the cascade model. In conclusion, our GSQA model shows the potential to generalize to a broad spectrum of questions, thus further expanding the spoken question answering capabilities of abstractive QA. Our code is available at https://voidful.github.io/GSQA
Towards General-Purpose Text-Instruction-Guided Voice Conversion
Sep 25, 2023



This paper introduces a novel voice conversion (VC) model, guided by text instructions such as "articulate slowly with a deep tone" or "speak in a cheerful boyish voice". Unlike traditional methods that rely on reference utterances to determine the attributes of the converted speech, our model adds versatility and specificity to voice conversion. The proposed VC model is a neural codec language model which processes a sequence of discrete codes, resulting in the code sequence of converted speech. It utilizes text instructions as style prompts to modify the prosody and emotional information of the given speech. In contrast to previous approaches, which often rely on employing separate encoders like prosody and content encoders to handle different aspects of the source speech, our model handles various information of speech in an end-to-end manner. Experiments have demonstrated the impressive capabilities of our model in comprehending instructions and delivering reasonable results.
ML-SUPERB: Multilingual Speech Universal PERformance Benchmark
May 18, 2023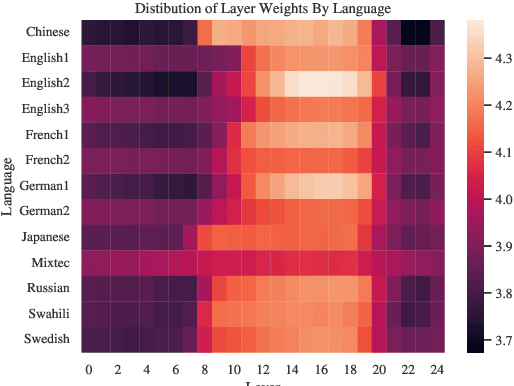
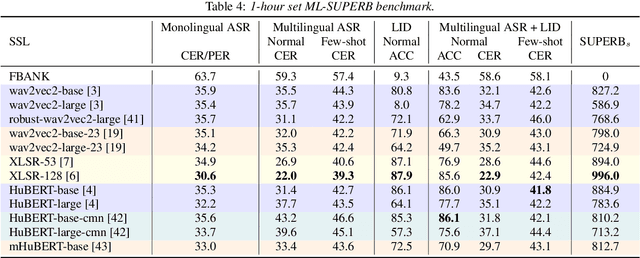
Speech processing Universal PERformance Benchmark (SUPERB) is a leaderboard to benchmark the performance of Self-Supervised Learning (SSL) models on various speech processing tasks. However, SUPERB largely considers English speech in its evaluation. This paper presents multilingual SUPERB (ML-SUPERB), covering 143 languages (ranging from high-resource to endangered), and considering both automatic speech recognition and language identification. Following the concept of SUPERB, ML-SUPERB utilizes frozen SSL features and employs a simple framework for multilingual tasks by learning a shallow downstream model. Similar to the SUPERB benchmark, we find speech SSL models can significantly improve performance compared to FBANK features. Furthermore, we find that multilingual models do not always perform better than their monolingual counterparts. We will release ML-SUPERB as a challenge with organized datasets and reproducible training scripts for future multilingual representation research.
T5lephone: Bridging Speech and Text Self-supervised Models for Spoken Language Understanding via Phoneme level T5
Nov 01, 2022In Spoken language understanding (SLU), a natural solution is concatenating pre-trained speech models (e.g. HuBERT) and pretrained language models (PLM, e.g. T5). Most previous works use pretrained language models with subword-based tokenization. However, the granularity of input units affects the alignment of speech model outputs and language model inputs, and PLM with character-based tokenization is underexplored. In this work, we conduct extensive studies on how PLMs with different tokenization strategies affect spoken language understanding task including spoken question answering (SQA) and speech translation (ST). We further extend the idea to create T5lephone(pronounced as telephone), a variant of T5 that is pretrained using phonemicized text. We initialize T5lephone with existing PLMs to pretrain it using relatively lightweight computational resources. We reached state-of-the-art on NMSQA, and the T5lephone model exceeds T5 with other types of units on end-to-end SQA and ST.
DUAL: Discrete Spoken Unit Adaptive Learning for Textless Spoken Question Answering
Mar 26, 2022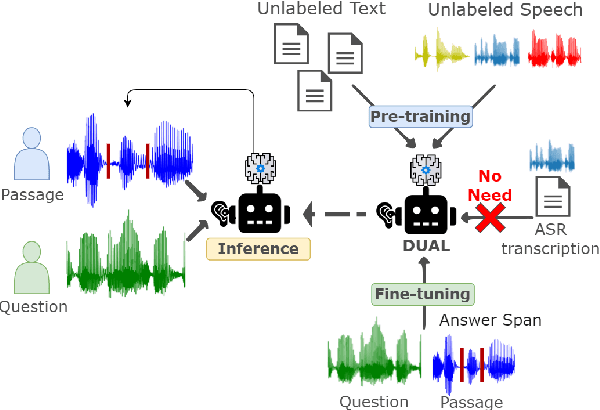
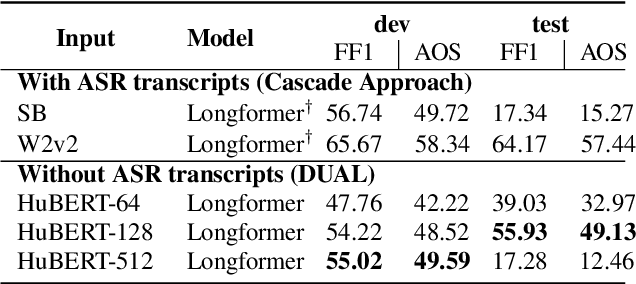
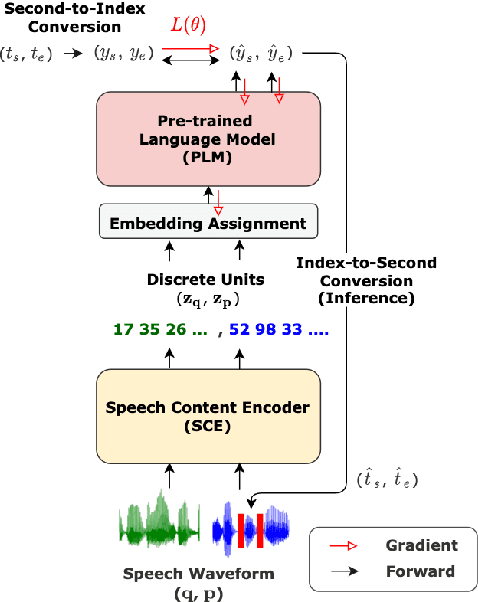
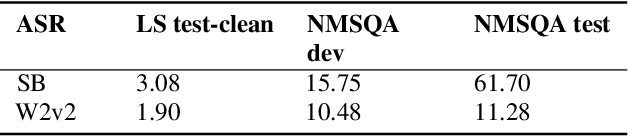
Spoken Question Answering (SQA) is to find the answer from a spoken document given a question, which is crucial for personal assistants when replying to the queries from the users. Existing SQA methods all rely on Automatic Speech Recognition (ASR) transcripts. Not only does ASR need to be trained with massive annotated data that are time and cost-prohibitive to collect for low-resourced languages, but more importantly, very often the answers to the questions include name entities or out-of-vocabulary words that cannot be recognized correctly. Also, ASR aims to minimize recognition errors equally over all words, including many function words irrelevant to the SQA task. Therefore, SQA without ASR transcripts (textless) is always highly desired, although known to be very difficult. This work proposes Discrete Spoken Unit Adaptive Learning (DUAL), leveraging unlabeled data for pre-training and fine-tuned by the SQA downstream task. The time intervals of spoken answers can be directly predicted from spoken documents. We also release a new SQA benchmark corpus, NMSQA, for data with more realistic scenarios. We empirically showed that DUAL yields results comparable to those obtained by cascading ASR and text QA model and robust to real-world data. Our code and model will be open-sourced.