 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels
May 13, 2024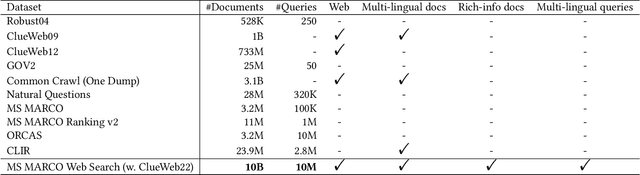
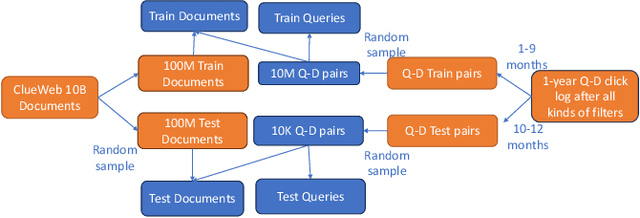
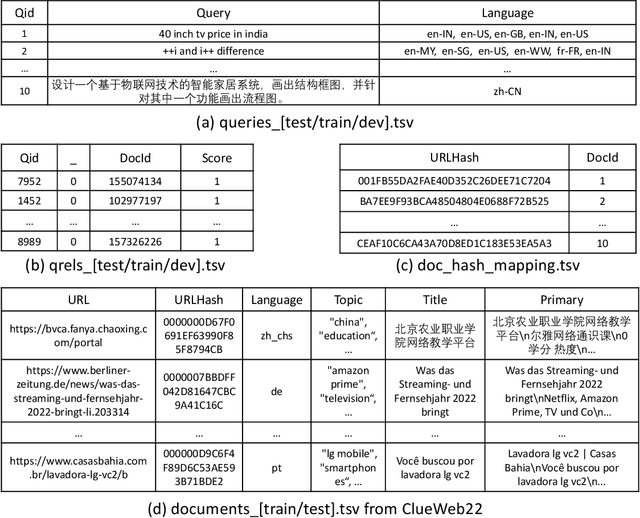
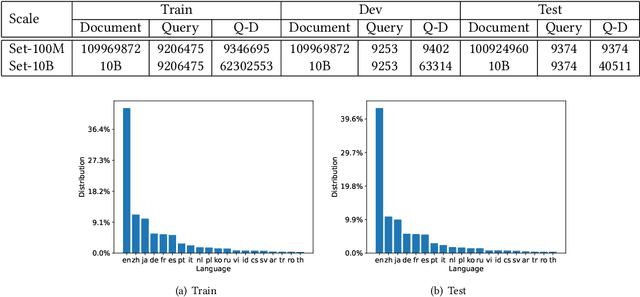
Recent breakthroughs in large models have highlighted the critical significance of data scale, labels and modals. In this paper, we introduce MS MARCO Web Search, the first large-scale information-rich web dataset, featuring millions of real clicked query-document labels. This dataset closely mimics real-world web document and query distribution, provides rich information for various kinds of downstream tasks and encourages research in various areas, such as generic end-to-end neural indexer models, generic embedding models, and next generation information access system with large language models. MS MARCO Web Search offers a retrieval benchmark with three web retrieval challenge tasks that demand innovations in both machine learning and information retrieval system research domains. As the first dataset that meets large, real and rich data requirements, MS MARCO Web Search paves the way for future advancements in AI and system research. MS MARCO Web Search dataset is available at: https://github.com/microsoft/MS-MARCO-Web-Search.
Researchy Questions: A Dataset of Multi-Perspective, Decompositional Questions for LLM Web Agents
Feb 27, 2024



Existing question answering (QA) datasets are no longer challenging to most powerful Large Language Models (LLMs). Traditional QA benchmarks like TriviaQA, NaturalQuestions, ELI5 and HotpotQA mainly study ``known unknowns'' with clear indications of both what information is missing, and how to find it to answer the question. Hence, good performance on these benchmarks provides a false sense of security. A yet unmet need of the NLP community is a bank of non-factoid, multi-perspective questions involving a great deal of unclear information needs, i.e. ``unknown uknowns''. We claim we can find such questions in search engine logs, which is surprising because most question-intent queries are indeed factoid. We present Researchy Questions, a dataset of search engine queries tediously filtered to be non-factoid, ``decompositional'' and multi-perspective. We show that users spend a lot of ``effort'' on these questions in terms of signals like clicks and session length, and that they are also challenging for GPT-4. We also show that ``slow thinking'' answering techniques, like decomposition into sub-questions shows benefit over answering directly. We release $\sim$ 100k Researchy Questions, along with the Clueweb22 URLs that were clicked.
Hyperbolic Graph Neural Networks at Scale: A Meta Learning Approach
Oct 29, 2023



The progress in hyperbolic neural networks (HNNs) research is hindered by their absence of inductive bias mechanisms, which are essential for generalizing to new tasks and facilitating scalable learning over large datasets. In this paper, we aim to alleviate these issues by learning generalizable inductive biases from the nodes' local subgraph and transfer them for faster learning over new subgraphs with a disjoint set of nodes, edges, and labels in a few-shot setting. We introduce a novel method, Hyperbolic GRAph Meta Learner (H-GRAM), that, for the tasks of node classification and link prediction, learns transferable information from a set of support local subgraphs in the form of hyperbolic meta gradients and label hyperbolic protonets to enable faster learning over a query set of new tasks dealing with disjoint subgraphs. Furthermore, we show that an extension of our meta-learning framework also mitigates the scalability challenges seen in HNNs faced by existing approaches. Our comparative analysis shows that H-GRAM effectively learns and transfers information in multiple challenging few-shot settings compared to other state-of-the-art baselines. Additionally, we demonstrate that, unlike standard HNNs, our approach is able to scale over large graph datasets and improve performance over its Euclidean counterparts.
Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Models
Oct 03, 2023



Standard Transformer-based language models (LMs) scale poorly to long contexts. We propose a solution based on dynamic contextual compression, which extends the Nugget approach of Qin & Van Durme (2023) from BERT-like frameworks to decoder-only LMs. Our method models history as compressed "nuggets" which are trained to allow for reconstruction, and it can be initialized with off-the-shelf models such as LLaMA. We demonstrate through experiments in language modeling, question answering, and summarization that Nugget2D retains capabilities in these tasks, while drastically reducing the overhead during decoding in terms of time and space. For example, in the experiments of autoencoding, Nugget2D can shrink context at a 20x compression ratio with a BLEU score of 98% for reconstruction, achieving nearly lossless encoding.
Contrastive Post-training Large Language Models on Data Curriculum
Oct 03, 2023



Alignment serves as an important step to steer large language models (LLMs) towards human preferences. In this paper, we explore contrastive post-training techniques for alignment by automatically constructing preference pairs from multiple models of varying strengths (e.g., InstructGPT, ChatGPT and GPT-4). We carefully compare the contrastive techniques of SLiC and DPO to SFT baselines and find that DPO provides a step-function improvement even after continueing SFT saturates. We also explore a data curriculum learning scheme for contrastive post-training, which starts by learning from "easier" pairs and transitioning to "harder" ones, which further improves alignment. Finally, we scale up our experiments to train with more data and larger models like Orca. Remarkably, contrastive post-training further improves the performance of Orca, already a state-of-the-art instruction learning model tuned with GPT-4 outputs, to exceed that of ChatGPT.
Simplifying Distributed Neural Network Training on Massive Graphs: Randomized Partitions Improve Model Aggregation
May 17, 2023



Distributed training of GNNs enables learning on massive graphs (e.g., social and e-commerce networks) that exceed the storage and computational capacity of a single machine. To reach performance comparable to centralized training, distributed frameworks focus on maximally recovering cross-instance node dependencies with either communication across instances or periodic fallback to centralized training, which create overhead and limit the framework scalability. In this work, we present a simplified framework for distributed GNN training that does not rely on the aforementioned costly operations, and has improved scalability, convergence speed and performance over the state-of-the-art approaches. Specifically, our framework (1) assembles independent trainers, each of which asynchronously learns a local model on locally-available parts of the training graph, and (2) only conducts periodic (time-based) model aggregation to synchronize the local models. Backed by our theoretical analysis, instead of maximizing the recovery of cross-instance node dependencies -- which has been considered the key behind closing the performance gap between model aggregation and centralized training -- , our framework leverages randomized assignment of nodes or super-nodes (i.e., collections of original nodes) to partition the training graph such that it improves data uniformity and minimizes the discrepancy of gradient and loss function across instances. In our experiments on social and e-commerce networks with up to 1.3 billion edges, our proposed RandomTMA and SuperTMA approaches -- despite using less training data -- achieve state-of-the-art performance and 2.31x speedup compared to the fastest baseline, and show better robustness to trainer failures.
You Only Transfer What You Share: Intersection-Induced Graph Transfer Learning for Link Prediction
Feb 27, 2023



Link prediction is central to many real-world applications, but its performance may be hampered when the graph of interest is sparse. To alleviate issues caused by sparsity, we investigate a previously overlooked phenomenon: in many cases, a densely connected, complementary graph can be found for the original graph. The denser graph may share nodes with the original graph, which offers a natural bridge for transferring meaningful knowledge. We identify this setting as Graph Intersection-induced Transfer Learning (GITL), which is motivated by practical applications in e-commerce or academic co-authorship predictions. We develop a framework to effectively leverage the structural prior in this setting. We first create an intersection subgraph using the shared nodes between the two graphs, then transfer knowledge from the source-enriched intersection subgraph to the full target graph. In the second step, we consider two approaches: a modified label propagation, and a multi-layer perceptron (MLP) model in a teacher-student regime. Experimental results on proprietary e-commerce datasets and open-source citation graphs show that the proposed workflow outperforms existing transfer learning baselines that do not explicitly utilize the intersection structure.
Search Behavior Prediction: A Hypergraph Perspective
Nov 29, 2022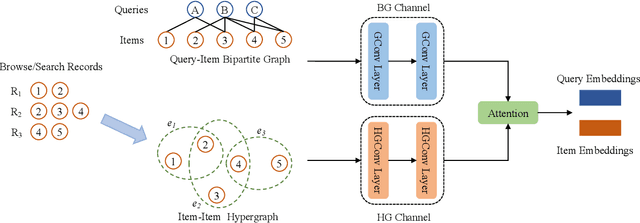
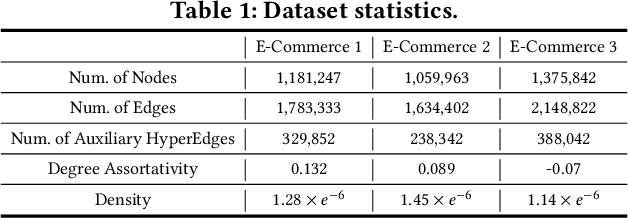
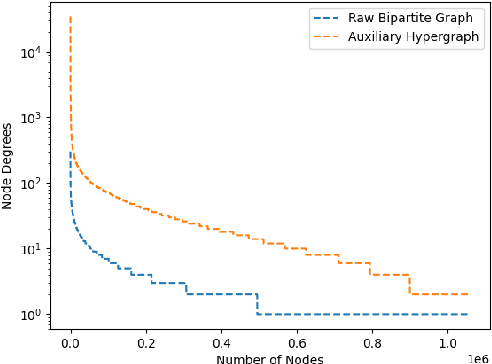
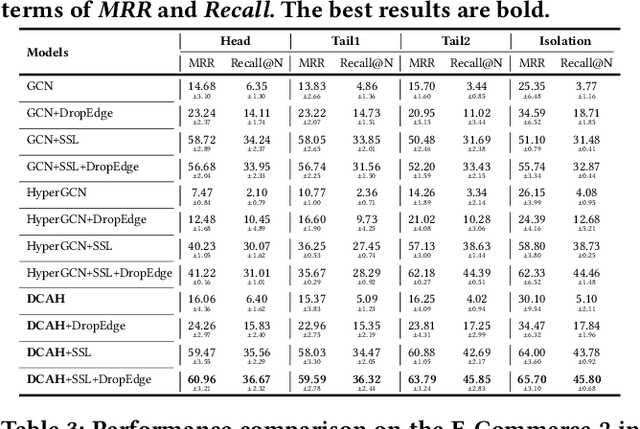
Although the bipartite shopping graphs are straightforward to model search behavior, they suffer from two challenges: 1) The majority of items are sporadically searched and hence have noisy/sparse query associations, leading to a \textit{long-tail} distribution. 2) Infrequent queries are more likely to link to popular items, leading to another hurdle known as \textit{disassortative mixing}. To address these two challenges, we go beyond the bipartite graph to take a hypergraph perspective, introducing a new paradigm that leverages \underline{auxiliary} information from anonymized customer engagement sessions to assist the \underline{main task} of query-item link prediction. This auxiliary information is available at web scale in the form of search logs. We treat all items appearing in the same customer session as a single hyperedge. The hypothesis is that items in a customer session are unified by a common shopping interest. With these hyperedges, we augment the original bipartite graph into a new \textit{hypergraph}. We develop a \textit{\textbf{D}ual-\textbf{C}hannel \textbf{A}ttention-Based \textbf{H}ypergraph Neural Network} (\textbf{DCAH}), which synergizes information from two potentially noisy sources (original query-item edges and item-item hyperedges). In this way, items on the tail are better connected due to the extra hyperedges, thereby enhancing their link prediction performance. We further integrate DCAH with self-supervised graph pre-training and/or DropEdge training, both of which effectively alleviate disassortative mixing. Extensive experiments on three proprietary E-Commerce datasets show that DCAH yields significant improvements of up to \textbf{24.6\% in mean reciprocal rank (MRR)} and \textbf{48.3\% in recall} compared to GNN-based baselines. Our source code is available at \url{https://github.com/amazon-science/dual-channel-hypergraph-neural-network}.
Text Enriched Sparse Hyperbolic Graph Convolutional Networks
Jul 07, 2022

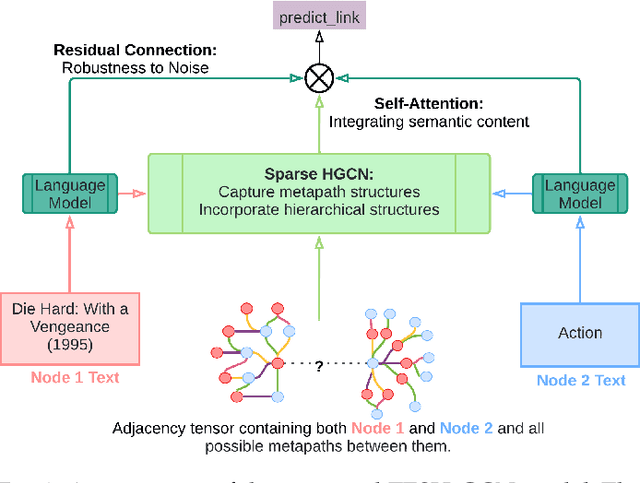
Heterogeneous networks, which connect informative nodes containing text with different edge types, are routinely used to store and process information in various real-world applications. Graph Neural Networks (GNNs) and their hyperbolic variants provide a promising approach to encode such networks in a low-dimensional latent space through neighborhood aggregation and hierarchical feature extraction, respectively. However, these approaches typically ignore metapath structures and the available semantic information. Furthermore, these approaches are sensitive to the noise present in the training data. To tackle these limitations, in this paper, we propose Text Enriched Sparse Hyperbolic Graph Convolution Network (TESH-GCN) to capture the graph's metapath structures using semantic signals and further improve prediction in large heterogeneous graphs. In TESH-GCN, we extract semantic node information, which successively acts as a connection signal to extract relevant nodes' local neighborhood and graph-level metapath features from the sparse adjacency tensor in a reformulated hyperbolic graph convolution layer. These extracted features in conjunction with semantic features from the language model (for robustness) are used for the final downstream task. Experiments on various heterogeneous graph datasets show that our model outperforms the current state-of-the-art approaches by a large margin on the task of link prediction. We also report a reduction in both the training time and model parameters compared to the existing hyperbolic approaches through a reformulated hyperbolic graph convolution. Furthermore, we illustrate the robustness of our model by experimenting with different levels of simulated noise in both the graph structure and text, and also, present a mechanism to explain TESH-GCN's prediction by analyzing the extracted metapaths.
Shopping Queries Dataset: A Large-Scale ESCI Benchmark for Improving Product Search
Jun 14, 2022


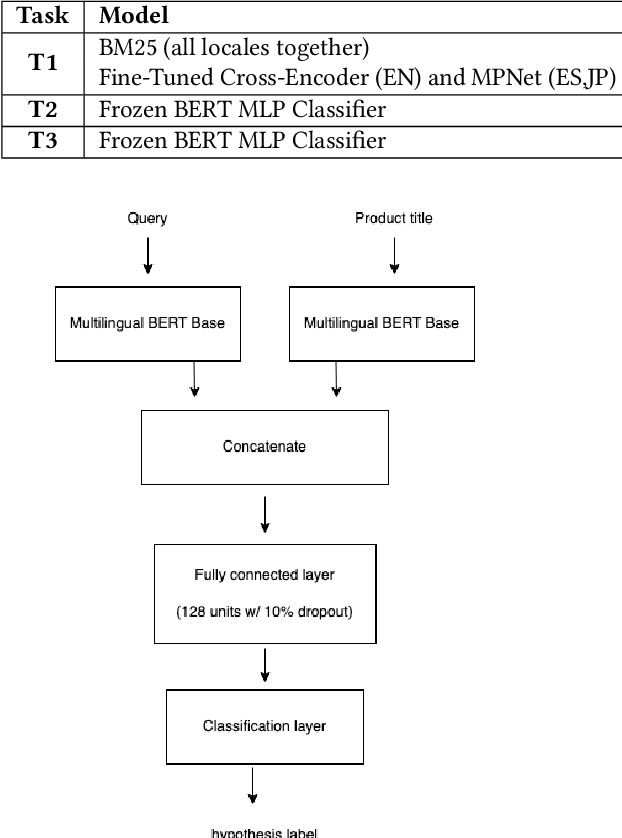
Improving the quality of search results can significantly enhance users experience and engagement with search engines. In spite of several recent advancements in the fields of machine learning and data mining, correctly classifying items for a particular user search query has been a long-standing challenge, which still has a large room for improvement. This paper introduces the "Shopping Queries Dataset", a large dataset of difficult Amazon search queries and results, publicly released with the aim of fostering research in improving the quality of search results. The dataset contains around 130 thousand unique queries and 2.6 million manually labeled (query,product) relevance judgements. The dataset is multilingual with queries in English, Japanese, and Spanish. The Shopping Queries Dataset is being used in one of the KDDCup'22 challenges. In this paper, we describe the dataset and present three evaluation tasks along with baseline results: (i) ranking the results list, (ii) classifying product results into relevance categories, and (iii) identifying substitute products for a given query. We anticipate that this data will become the gold standard for future research in the topic of product search.