 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Hint for Reinforcement Learning
Apr 01, 2026Group Relative Policy Optimization (GRPO) is widely used for reinforcement learning with verifiable rewards, but it often suffers from advantage collapse: when all rollouts in a group receive the same reward, the group yields zero relative advantage and thus no learning signal. For example, if a question is too hard for the reasoner, all sampled rollouts can be incorrect and receive zero reward. Recent work addresses this issue by adding hints or auxiliary scaffolds to such hard questions so that the reasoner produces mixed outcomes and recovers a non-zero update. However, existing hints are usually fixed rather than adapted to the current reasoner, and a hint that creates learning signal under the hinted input does not necessarily improve the no-hint policy used at test time. To this end, we propose Hint Learning for Reinforcement Learning (HiLL), a framework that jointly trains a hinter policy and a reasoner policy during RL. For each hard question, the hinter generates hints online conditioned on the current reasoner's incorrect rollout, allowing hint generation to adapt to the reasoner's evolving errors. We further introduce hint reliance, which measures how strongly correct hinted trajectories depend on the hint. We derive a transferability result showing that lower hint reliance implies stronger transfer from hinted success to no-hint success, and we use this result to define a transfer-weighted reward for training the hinter. Therefore, HiLL favors hints that not only recover informative GRPO groups, but also produce signals that are more likely to improve the original no-hint policy. Experiments across multiple benchmarks show that HiLL consistently outperforms GRPO and prior hint-based baselines, demonstrating the value of adaptive and transfer-aware hint learning for RL. The code is available at https://github.com/Andree-9/HiLL.
Learning to Self-Evolve
Mar 19, 2026We introduce Learning to Self-Evolve (LSE), a reinforcement learning framework that trains large language models (LLMs) to improve their own contexts at test time. We situate LSE in the setting of test-time self-evolution, where a model iteratively refines its context from feedback on seen problems to perform better on new ones. Existing approaches rely entirely on the inherent reasoning ability of the model and never explicitly train it for this task. LSE reduces the multi-step evolution problem to a single-step RL objective, where each context edit is rewarded by the improvement in downstream performance. We pair this objective with a tree-guided evolution loop. On Text-to-SQL generation (BIRD) and general question answering (MMLU-Redux), a 4B-parameter model trained with LSE outperforms self-evolving policies powered by GPT-5 and Claude Sonnet 4.5, as well as prompt optimization methods including GEPA and TextGrad, and transfers to guide other models without additional training. Our results highlight the effectiveness of treating self-evolution as a learnable skill.
Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning
Feb 11, 2026Recent advances in large language model (LLM) have empowered autonomous agents to perform complex tasks that require multi-turn interactions with tools and environments. However, scaling such agent training is limited by the lack of diverse and reliable environments. In this paper, we propose Agent World Model (AWM), a fully synthetic environment generation pipeline. Using this pipeline, we scale to 1,000 environments covering everyday scenarios, in which agents can interact with rich toolsets (35 tools per environment on average) and obtain high-quality observations. Notably, these environments are code-driven and backed by databases, providing more reliable and consistent state transitions than environments simulated by LLMs. Moreover, they enable more efficient agent interaction compared with collecting trajectories from realistic environments. To demonstrate the effectiveness of this resource, we perform large-scale reinforcement learning for multi-turn tool-use agents. Thanks to the fully executable environments and accessible database states, we can also design reliable reward functions. Experiments on three benchmarks show that training exclusively in synthetic environments, rather than benchmark-specific ones, yields strong out-of-distribution generalization. The code is available at https://github.com/Snowflake-Labs/agent-world-model.
ExCoT: Optimizing Reasoning for Text-to-SQL with Execution Feedback
Mar 25, 2025Text-to-SQL demands precise reasoning to convert natural language questions into structured queries. While large language models (LLMs) excel in many reasoning tasks, their ability to leverage Chain-of-Thought (CoT) reasoning for text-to-SQL remains underexplored. We identify critical limitations: zero-shot CoT offers minimal gains, and Direct Preference Optimization (DPO) applied without CoT yields marginal improvements. We propose ExCoT, a novel framework that iteratively optimizes open-source LLMs by combining CoT reasoning with off-policy and on-policy DPO, relying solely on execution accuracy as feedback. This approach eliminates the need for reward models or human-annotated preferences. Our experimental results demonstrate significant performance gains: ExCoT improves execution accuracy on BIRD dev set from 57.37% to 68.51% and on Spider test set from 78.81% to 86.59% for LLaMA-3 70B, with Qwen-2.5-Coder demonstrating similar improvements. Our best model achieves state-of-the-art performance in the single-model setting on both BIRD and Spider datasets, notably achieving 68.53% on the BIRD test set.
StarCoder 2 and The Stack v2: The Next Generation
Feb 29, 2024



The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
Contrastive Post-training Large Language Models on Data Curriculum
Oct 03, 2023



Alignment serves as an important step to steer large language models (LLMs) towards human preferences. In this paper, we explore contrastive post-training techniques for alignment by automatically constructing preference pairs from multiple models of varying strengths (e.g., InstructGPT, ChatGPT and GPT-4). We carefully compare the contrastive techniques of SLiC and DPO to SFT baselines and find that DPO provides a step-function improvement even after continueing SFT saturates. We also explore a data curriculum learning scheme for contrastive post-training, which starts by learning from "easier" pairs and transitioning to "harder" ones, which further improves alignment. Finally, we scale up our experiments to train with more data and larger models like Orca. Remarkably, contrastive post-training further improves the performance of Orca, already a state-of-the-art instruction learning model tuned with GPT-4 outputs, to exceed that of ChatGPT.
LongCoder: A Long-Range Pre-trained Language Model for Code Completion
Jun 26, 2023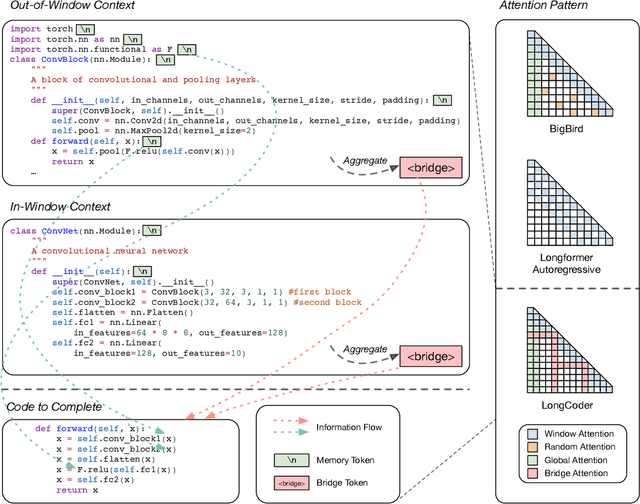
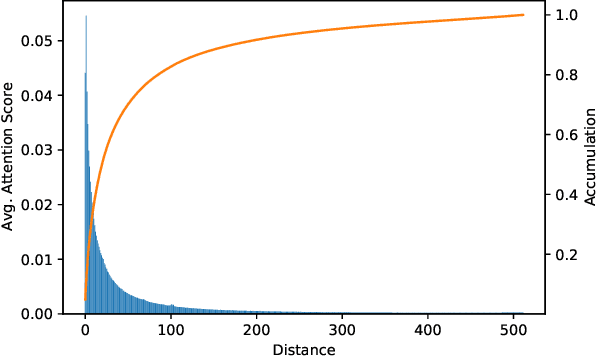
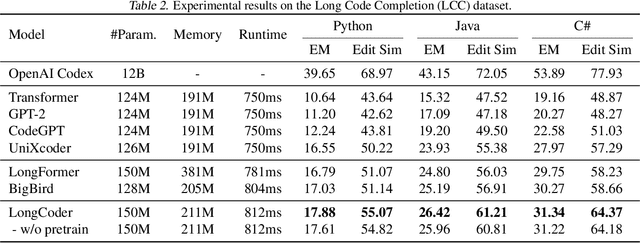
In this paper, we introduce a new task for code completion that focuses on handling long code input and propose a sparse Transformer model, called LongCoder, to address this task. LongCoder employs a sliding window mechanism for self-attention and introduces two types of globally accessible tokens - bridge tokens and memory tokens - to improve performance and efficiency. Bridge tokens are inserted throughout the input sequence to aggregate local information and facilitate global interaction, while memory tokens are included to highlight important statements that may be invoked later and need to be memorized, such as package imports and definitions of classes, functions, or structures. We conduct experiments on a newly constructed dataset that contains longer code context and the publicly available CodeXGLUE benchmark. Experimental results demonstrate that LongCoder achieves superior performance on code completion tasks compared to previous models while maintaining comparable efficiency in terms of computational resources during inference. All the codes and data are available at https://github.com/microsoft/CodeBERT.
RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems
Jun 05, 2023
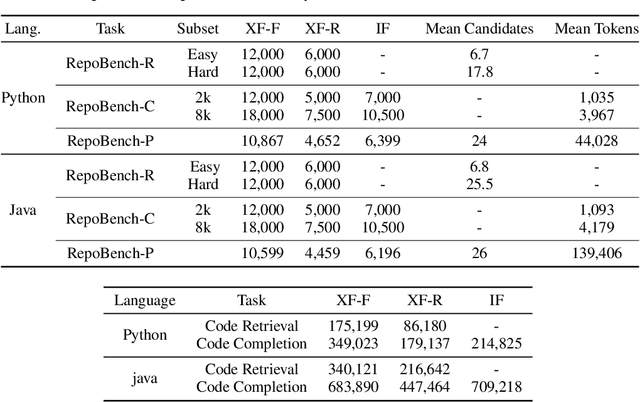
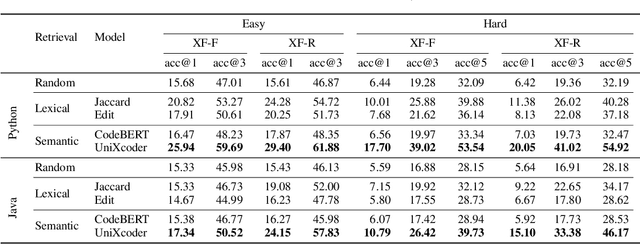
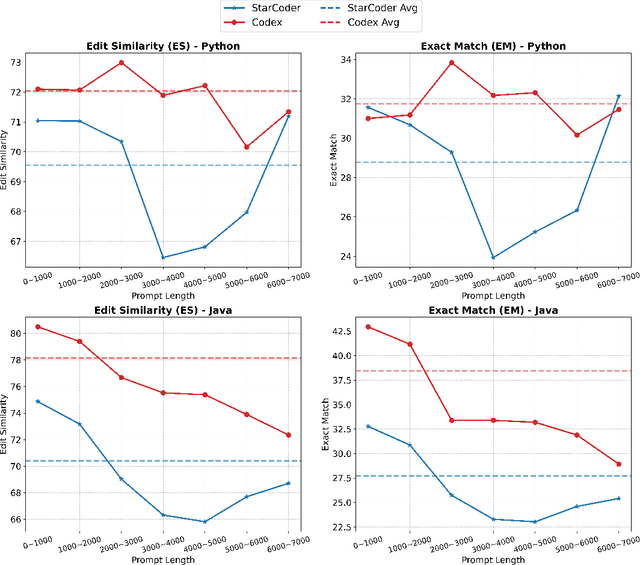
Large Language Models (LLMs) have greatly advanced code auto-completion systems, with a potential for substantial productivity enhancements for developers. However, current benchmarks mainly focus on single-file tasks, leaving an assessment gap for more complex, real-world, multi-file programming scenarios. To fill this gap, we introduce RepoBench, a new benchmark specifically designed for evaluating repository-level code auto-completion systems. RepoBench consists of three interconnected evaluation tasks: RepoBench-R (Retrieval), RepoBench-C (Code Completion), and RepoBench-P (Pipeline). Each task respectively measures the system's ability to retrieve the most relevant code snippets from other files as cross-file context, predict the next line of code with cross-file and in-file context, and handle complex tasks that require a combination of both retrieval and next-line prediction. RepoBench aims to facilitate a more complete comparison of performance and encouraging continuous improvement in auto-completion systems. RepoBench is publicly available at https://github.com/Leolty/repobench.
Small Models are Valuable Plug-ins for Large Language Models
May 15, 2023Large language models (LLMs) such as GPT-3 and GPT-4 are powerful but their weights are often publicly unavailable and their immense sizes make the models difficult to be tuned with common hardware. As a result, effectively tuning these models with large-scale supervised data can be challenging. As an alternative, In-Context Learning (ICL) can only use a small number of supervised examples due to context length limits. In this paper, we propose Super In-Context Learning (SuperICL) which allows black-box LLMs to work with locally fine-tuned smaller models, resulting in superior performance on supervised tasks. Our experiments demonstrate that SuperICL can improve performance beyond state-of-the-art fine-tuned models while addressing the instability problem of in-context learning. Furthermore, SuperICL can enhance the capabilities of smaller models, such as multilinguality and interpretability.
Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data
Apr 04, 2023Chat models, such as ChatGPT, have shown impressive capabilities and have been rapidly adopted across numerous domains. However, these models are only accessible through a restricted API, creating barriers for new research and progress in the field. We propose a pipeline that can automatically generate a high-quality multi-turn chat corpus by leveraging ChatGPT to engage in a conversation with itself. Subsequently, we employ parameter-efficient tuning to enhance LLaMA, an open-source large language model. The resulting model, named Baize, demonstrates good performance in multi-turn dialogues with guardrails that minimize potential risks. The Baize models and data are released for research purposes only at https://github.com/project-baize/baize. An online demo is also available at https://huggingface.co/spaces/project-baize/baize-lora-7B.