 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning about Reasoning: BAPO Bounds on Chain-of-Thought Token Complexity in LLMs
Feb 02, 2026Inference-time scaling via chain-of-thought (CoT) reasoning is a major driver of state-of-the-art LLM performance, but it comes with substantial latency and compute costs. We address a fundamental theoretical question: how many reasoning tokens are required to solve a problem as input size grows? By extending the bounded attention prefix oracle (BAPO) model--an abstraction of LLMs that quantifies the information flow required to solve a task--we prove lower bounds on the CoT tokens required for three canonical BAPO-hard tasks: binary majority, triplet matching, and graph reachability. We show that each requires $Ω(n)$ reasoning tokens when the input size is $n$. We complement these results with matching or near-matching upper bounds via explicit constructions. Finally, our experiments with frontier reasoning models show approximately linear reasoning token scaling on these tasks and failures when constrained to smaller reasoning budgets, consistent with our theoretical lower bounds. Together, our results identify fundamental bottlenecks in inference-time compute through CoT and offer a principled tool for analyzing optimal reasoning length.
Lost in Transmission: When and Why LLMs Fail to Reason Globally
May 13, 2025Despite their many successes, transformer-based large language models (LLMs) continue to struggle with tasks that require complex reasoning over large parts of their input. We argue that these failures arise due to capacity limits on the accurate flow of information within LLMs. To formalize this issue, we introduce the bounded attention prefix oracle (BAPO) model, a new computational framework that models bandwidth constraints on attention heads, the mechanism for internal communication in LLMs. We show that several important reasoning problems like graph reachability require high communication bandwidth for BAPOs to solve; we call these problems BAPO-hard. Our experiments corroborate our theoretical predictions: GPT-4, Claude, and Gemini succeed on BAPO-easy tasks and fail even on relatively small BAPO-hard tasks. BAPOs also reveal another benefit of chain of thought (CoT): we prove that breaking down a task using CoT can turn any BAPO-hard problem into a BAPO-easy one. Our results offer principled explanations for key LLM failures and suggest directions for architectures and inference methods that mitigate bandwidth limits.
LLMs Get Lost In Multi-Turn Conversation
May 09, 2025Large Language Models (LLMs) are conversational interfaces. As such, LLMs have the potential to assist their users not only when they can fully specify the task at hand, but also to help them define, explore, and refine what they need through multi-turn conversational exchange. Although analysis of LLM conversation logs has confirmed that underspecification occurs frequently in user instructions, LLM evaluation has predominantly focused on the single-turn, fully-specified instruction setting. In this work, we perform large-scale simulation experiments to compare LLM performance in single- and multi-turn settings. Our experiments confirm that all the top open- and closed-weight LLMs we test exhibit significantly lower performance in multi-turn conversations than single-turn, with an average drop of 39% across six generation tasks. Analysis of 200,000+ simulated conversations decomposes the performance degradation into two components: a minor loss in aptitude and a significant increase in unreliability. We find that LLMs often make assumptions in early turns and prematurely attempt to generate final solutions, on which they overly rely. In simpler terms, we discover that *when LLMs take a wrong turn in a conversation, they get lost and do not recover*.
Group Preference Alignment: Customized LLM Response Generation from In-Situ Conversations
Mar 11, 2025LLMs often fail to meet the specialized needs of distinct user groups due to their one-size-fits-all training paradigm \cite{lucy-etal-2024-one} and there is limited research on what personalization aspects each group expect. To address these limitations, we propose a group-aware personalization framework, Group Preference Alignment (GPA), that identifies context-specific variations in conversational preferences across user groups and then steers LLMs to address those preferences. Our approach consists of two steps: (1) Group-Aware Preference Extraction, where maximally divergent user-group preferences are extracted from real-world conversation logs and distilled into interpretable rubrics, and (2) Tailored Response Generation, which leverages these rubrics through two methods: a) Context-Tuned Inference (GAP-CT), that dynamically adjusts responses via context-dependent prompt instructions, and b) Rubric-Finetuning Inference (GPA-FT), which uses the rubrics to generate contrastive synthetic data for personalization of group-specific models via alignment. Experiments demonstrate that our framework significantly improves alignment of the output with respect to user preferences and outperforms baseline methods, while maintaining robust performance on standard benchmarks.
GenTool: Enhancing Tool Generalization in Language Models through Zero-to-One and Weak-to-Strong Simulation
Feb 26, 2025Large Language Models (LLMs) can enhance their capabilities as AI assistants by integrating external tools, allowing them to access a wider range of information. While recent LLMs are typically fine-tuned with tool usage examples during supervised fine-tuning (SFT), questions remain about their ability to develop robust tool-usage skills and can effectively generalize to unseen queries and tools. In this work, we present GenTool, a novel training framework that prepares LLMs for diverse generalization challenges in tool utilization. Our approach addresses two fundamental dimensions critical for real-world applications: Zero-to-One Generalization, enabling the model to address queries initially lacking a suitable tool by adopting and utilizing one when it becomes available, and Weak-to-Strong Generalization, allowing models to leverage enhanced versions of existing tools to solve queries. To achieve this, we develop synthetic training data simulating these two dimensions of tool usage and introduce a two-stage fine-tuning approach: optimizing tool ranking, then refining tool selection. Through extensive experiments across four generalization scenarios, we demonstrate that our method significantly enhances the tool-usage capabilities of LLMs ranging from 1B to 8B parameters, achieving performance that surpasses GPT-4o. Furthermore, our analysis also provides valuable insights into the challenges LLMs encounter in tool generalization.
Rethinking Node Representation Interpretation through Relation Coherence
Nov 01, 2024Understanding node representations in graph-based models is crucial for uncovering biases ,diagnosing errors, and building trust in model decisions. However, previous work on explainable AI for node representations has primarily emphasized explanations (reasons for model predictions) rather than interpretations (mapping representations to understandable concepts). Furthermore, the limited research that focuses on interpretation lacks validation, and thus the reliability of such methods is unclear. We address this gap by proposing a novel interpretation method-Node Coherence Rate for Representation Interpretation (NCI)-which quantifies how well different node relations are captured in node representations. We also propose a novel method (IME) to evaluate the accuracy of different interpretation methods. Our experimental results demonstrate that NCI reduces the error of the previous best approach by an average of 39%. We then apply NCI to derive insights about the node representations produced by several graph-based methods and assess their quality in unsupervised settings.
Improving Node Representation by Boosting Target-Aware Contrastive Loss
Oct 04, 2024Graphs model complex relationships between entities, with nodes and edges capturing intricate connections. Node representation learning involves transforming nodes into low-dimensional embeddings. These embeddings are typically used as features for downstream tasks. Therefore, their quality has a significant impact on task performance. Existing approaches for node representation learning span (semi-)supervised, unsupervised, and self-supervised paradigms. In graph domains, (semi-)supervised learning often only optimizes models based on class labels, neglecting other abundant graph signals, which limits generalization. While self-supervised or unsupervised learning produces representations that better capture underlying graph signals, the usefulness of these captured signals for downstream target tasks can vary. To bridge this gap, we introduce Target-Aware Contrastive Learning (Target-aware CL) which aims to enhance target task performance by maximizing the mutual information between the target task and node representations with a self-supervised learning process. This is achieved through a sampling function, XGBoost Sampler (XGSampler), to sample proper positive examples for the proposed Target-Aware Contrastive Loss (XTCL). By minimizing XTCL, Target-aware CL increases the mutual information between the target task and node representations, such that model generalization is improved. Additionally, XGSampler enhances the interpretability of each signal by showing the weights for sampling the proper positive examples. We show experimentally that XTCL significantly improves the performance on two target tasks: node classification and link prediction tasks, compared to state-of-the-art models.
WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback
Aug 28, 2024



As large language models (LLMs) continue to advance, aligning these models with human preferences has emerged as a critical challenge. Traditional alignment methods, relying on human or LLM annotated datasets, are limited by their resource-intensive nature, inherent subjectivity, and the risk of feedback loops that amplify model biases. To overcome these limitations, we introduce WildFeedback, a novel framework that leverages real-time, in-situ user interactions to create preference datasets that more accurately reflect authentic human values. WildFeedback operates through a three-step process: feedback signal identification, preference data construction, and user-guided evaluation. We applied this framework to a large corpus of user-LLM conversations, resulting in a rich preference dataset that reflects genuine user preferences. This dataset captures the nuances of user preferences by identifying and classifying feedback signals within natural conversations, thereby enabling the construction of more representative and context-sensitive alignment data. Our extensive experiments demonstrate that LLMs fine-tuned on WildFeedback exhibit significantly improved alignment with user preferences, as evidenced by both traditional benchmarks and our proposed user-guided evaluation. By incorporating real-time feedback from actual users, WildFeedback addresses the scalability, subjectivity, and bias challenges that plague existing approaches, marking a significant step toward developing LLMs that are more responsive to the diverse and evolving needs of their users. In summary, WildFeedback offers a robust, scalable solution for aligning LLMs with true human values, setting a new standard for the development and evaluation of user-centric language models.
LLMExplainer: Large Language Model based Bayesian Inference for Graph Explanation Generation
Jul 23, 2024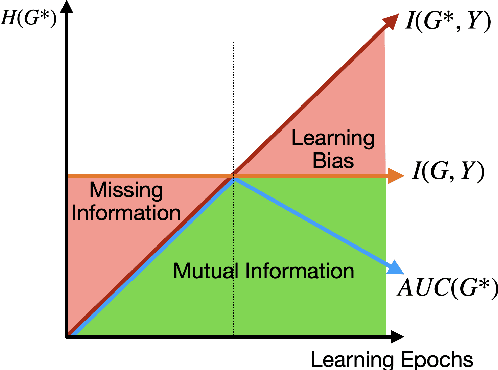
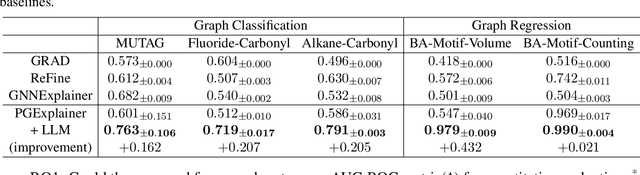
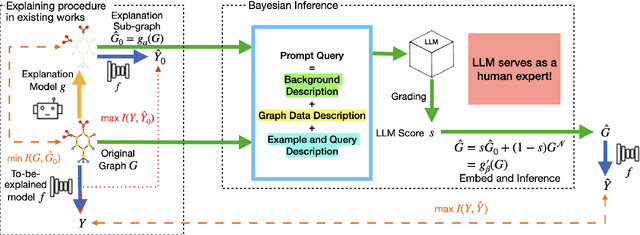

Recent studies seek to provide Graph Neural Network (GNN) interpretability via multiple unsupervised learning models. Due to the scarcity of datasets, current methods easily suffer from learning bias. To solve this problem, we embed a Large Language Model (LLM) as knowledge into the GNN explanation network to avoid the learning bias problem. We inject LLM as a Bayesian Inference (BI) module to mitigate learning bias. The efficacy of the BI module has been proven both theoretically and experimentally. We conduct experiments on both synthetic and real-world datasets. The innovation of our work lies in two parts: 1. We provide a novel view of the possibility of an LLM functioning as a Bayesian inference to improve the performance of existing algorithms; 2. We are the first to discuss the learning bias issues in the GNN explanation problem.
On Overcoming Miscalibrated Conversational Priors in LLM-based Chatbots
Jun 01, 2024

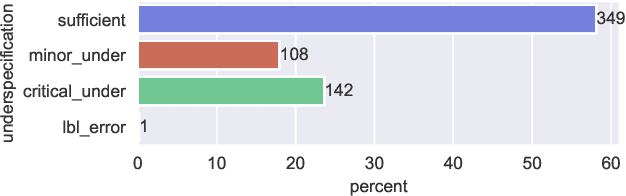

We explore the use of Large Language Model (LLM-based) chatbots to power recommender systems. We observe that the chatbots respond poorly when they encounter under-specified requests (e.g., they make incorrect assumptions, hedge with a long response, or refuse to answer). We conjecture that such miscalibrated response tendencies (i.e., conversational priors) can be attributed to LLM fine-tuning using annotators -- single-turn annotations may not capture multi-turn conversation utility, and the annotators' preferences may not even be representative of users interacting with a recommender system. We first analyze public LLM chat logs to conclude that query under-specification is common. Next, we study synthetic recommendation problems with configurable latent item utilities and frame them as Partially Observed Decision Processes (PODP). We find that pre-trained LLMs can be sub-optimal for PODPs and derive better policies that clarify under-specified queries when appropriate. Then, we re-calibrate LLMs by prompting them with learned control messages to approximate the improved policy. Finally, we show empirically that our lightweight learning approach effectively uses logged conversation data to re-calibrate the response strategies of LLM-based chatbots for recommendation tasks.