 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels
May 13, 2024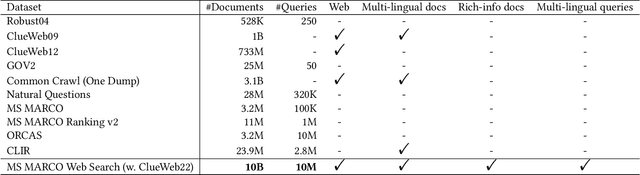
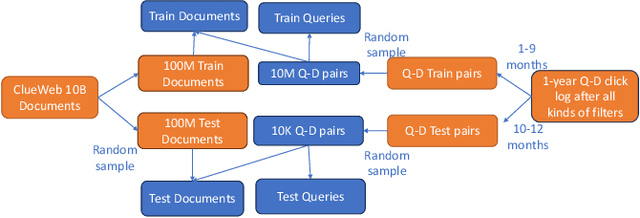
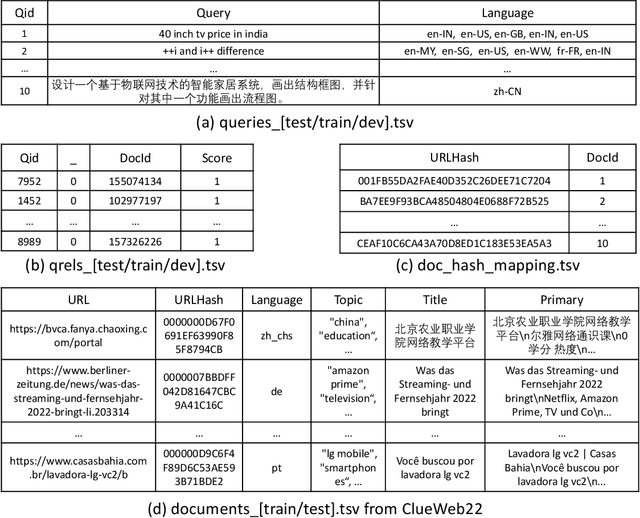
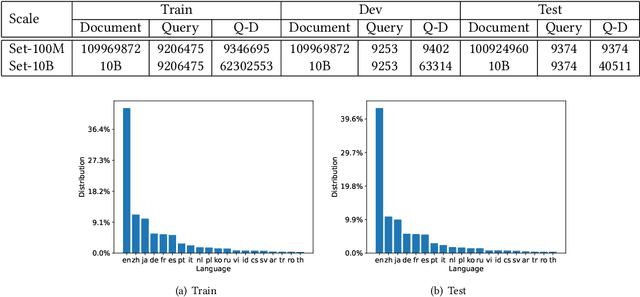
Recent breakthroughs in large models have highlighted the critical significance of data scale, labels and modals. In this paper, we introduce MS MARCO Web Search, the first large-scale information-rich web dataset, featuring millions of real clicked query-document labels. This dataset closely mimics real-world web document and query distribution, provides rich information for various kinds of downstream tasks and encourages research in various areas, such as generic end-to-end neural indexer models, generic embedding models, and next generation information access system with large language models. MS MARCO Web Search offers a retrieval benchmark with three web retrieval challenge tasks that demand innovations in both machine learning and information retrieval system research domains. As the first dataset that meets large, real and rich data requirements, MS MARCO Web Search paves the way for future advancements in AI and system research. MS MARCO Web Search dataset is available at: https://github.com/microsoft/MS-MARCO-Web-Search.
LEAD: Liberal Feature-based Distillation for Dense Retrieval
Dec 10, 2022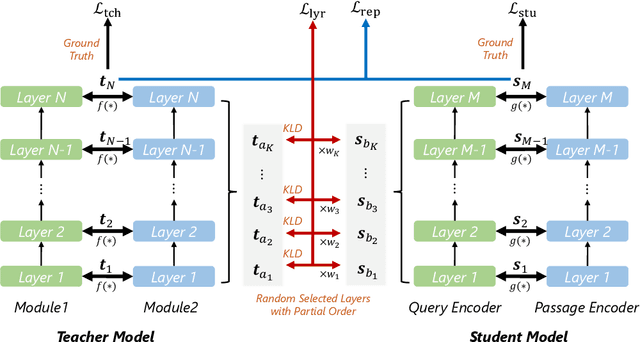
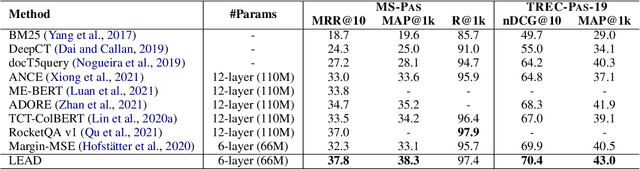
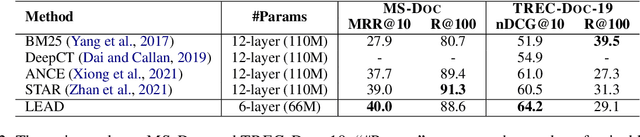
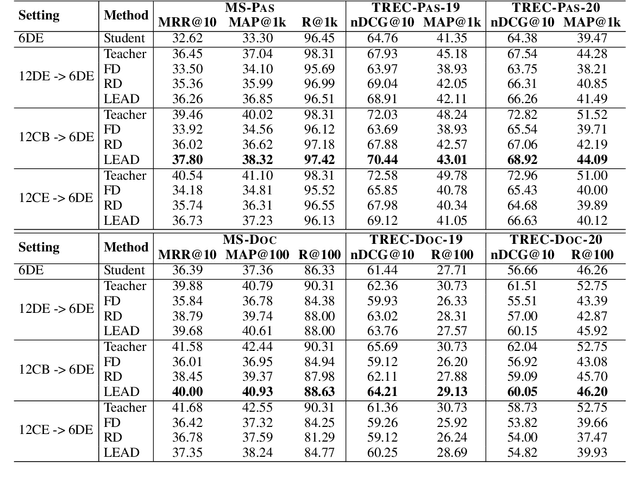
Knowledge distillation is often used to transfer knowledge from a strong teacher model to a relatively weak student model. Traditional knowledge distillation methods include response-based methods and feature-based methods. Response-based methods are used the most widely but suffer from lower upper limit of model performance, while feature-based methods have constraints on the vocabularies and tokenizers. In this paper, we propose a tokenizer-free method liberal feature-based distillation (LEAD). LEAD aligns the distribution between teacher model and student model, which is effective, extendable, portable and has no requirements on vocabularies, tokenizer, or model architecture. Extensive experiments show the effectiveness of LEAD on several widely-used benchmarks, including MS MARCO Passage, TREC Passage 19, TREC Passage 20, MS MARCO Document, TREC Document 19 and TREC Document 20.
PROD: Progressive Distillation for Dense Retrieval
Sep 27, 2022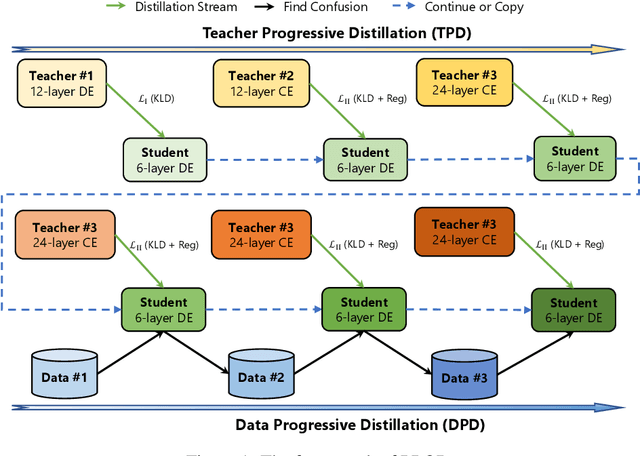
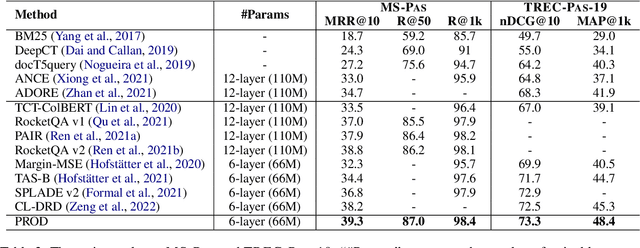
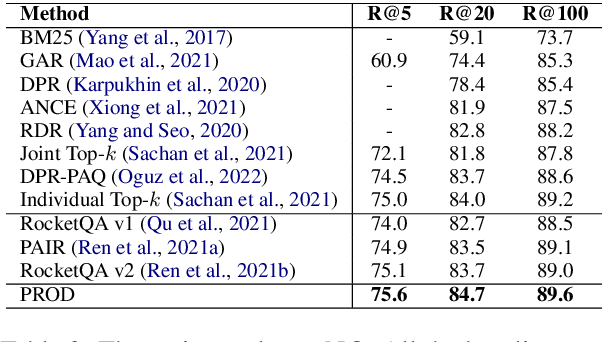
Knowledge distillation is an effective way to transfer knowledge from a strong teacher to an efficient student model. Ideally, we expect the better the teacher is, the better the student. However, this expectation does not always come true. It is common that a better teacher model results in a bad student via distillation due to the nonnegligible gap between teacher and student. To bridge the gap, we propose PROD, a PROgressive Distillation method, for dense retrieval. PROD consists of a teacher progressive distillation and a data progressive distillation to gradually improve the student. We conduct extensive experiments on five widely-used benchmarks, MS MARCO Passage, TREC Passage 19, TREC Document 19, MS MARCO Document and Natural Questions, where PROD achieves the state-of-the-art within the distillation methods for dense retrieval. The code and models will be released.
Aligning the Pretraining and Finetuning Objectives of Language Models
Feb 05, 2020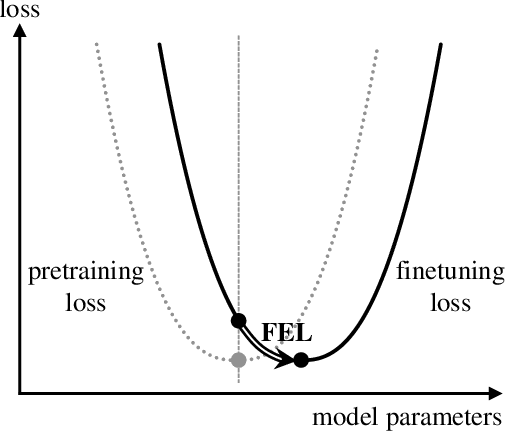
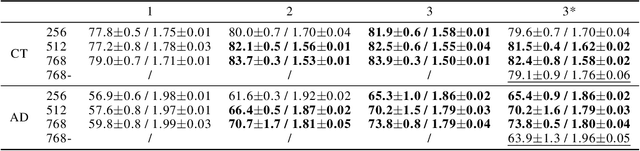
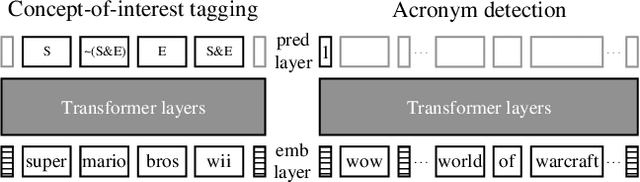
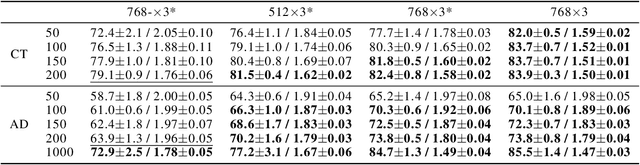
We demonstrate that explicitly aligning the pretraining objectives to the finetuning objectives in language model training significantly improves the finetuning task performance and reduces the minimum amount of finetuning examples required. The performance margin gained from objective alignment allows us to build language models with smaller sizes for tasks with less available training data. We provide empirical evidence of these claims by applying objective alignment to concept-of-interest tagging and acronym detection tasks. We found that, with objective alignment, our 768 by 3 and 512 by 3 transformer language models can reach accuracy of 83.9%/82.5% for concept-of-interest tagging and 73.8%/70.2% for acronym detection using only 200 finetuning examples per task, outperforming the 768 by 3 model pretrained without objective alignment by +4.8%/+3.4% and +9.9%/+6.3%. We name finetuning small language models in the presence of hundreds of training examples or less "Few Example learning". In practice, Few Example Learning enabled by objective alignment not only saves human labeling costs, but also makes it possible to leverage language models in more real-time applications.