 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of Building Verifiers for Computer Use Agents
Apr 05, 2026Verifying the success of computer use agent (CUA) trajectories is a critical challenge: without reliable verification, neither evaluation nor training signal can be trusted. In this paper, we present lessons learned from building a best-in-class verifier for web tasks we call the Universal Verifier. We design the Universal Verifier around four key principles: 1) constructing rubrics with meaningful, non-overlapping criteria to reduce noise; 2) separating process and outcome rewards that yield complementary signals, capturing cases where an agent follows the right steps but gets blocked or succeeds through an unexpected path; 3) distinguishing between controllable and uncontrollable failures scored via a cascading-error-free strategy for finer-grained failure understanding; and 4) a divide-and-conquer context management scheme that attends to all screenshots in a trajectory, improving reliability on longer task horizons. We validate these findings on CUAVerifierBench, a new set of CUA trajectories with both process and outcome human labels, showing that our Universal Verifier agrees with humans as often as humans agree with each other. We report a reduction in false positive rates to near zero compared to baselines like WebVoyager ($\geq$ 45\%) and WebJudge ($\geq$ 22\%). We emphasize that these gains stem from the cumulative effect of the design choices above. We also find that an auto-research agent achieves 70\% of expert quality in 5\% of the time, but fails to discover all strategies required to replicate the Universal Verifier. We open-source our Universal Verifier system along with CUAVerifierBench; available at https://github.com/microsoft/fara.
Explorer: Scaling Exploration-driven Web Trajectory Synthesis for Multimodal Web Agents
Feb 19, 2025Recent success in large multimodal models (LMMs) has sparked promising applications of agents capable of autonomously completing complex web tasks. While open-source LMM agents have made significant advances in offline evaluation benchmarks, their performance still falls substantially short of human-level capabilities in more realistic online settings. A key bottleneck is the lack of diverse and large-scale trajectory-level datasets across various domains, which are expensive to collect. In this paper, we address this challenge by developing a scalable recipe to synthesize the largest and most diverse trajectory-level dataset to date, containing over 94K successful multimodal web trajectories, spanning 49K unique URLs, 720K screenshots, and 33M web elements. In particular, we leverage extensive web exploration and refinement to obtain diverse task intents. The average cost is 28 cents per successful trajectory, making it affordable to a wide range of users in the community. Leveraging this dataset, we train Explorer, a multimodal web agent, and demonstrate strong performance on both offline and online web agent benchmarks such as Mind2Web-Live, Multimodal-Mind2Web, and MiniWob++. Additionally, our experiments highlight data scaling as a key driver for improving web agent capabilities. We hope this study makes state-of-the-art LMM-based agent research at a larger scale more accessible.
LLM-Rubric: A Multidimensional, Calibrated Approach to Automated Evaluation of Natural Language Texts
Dec 31, 2024This paper introduces a framework for the automated evaluation of natural language texts. A manually constructed rubric describes how to assess multiple dimensions of interest. To evaluate a text, a large language model (LLM) is prompted with each rubric question and produces a distribution over potential responses. The LLM predictions often fail to agree well with human judges -- indeed, the humans do not fully agree with one another. However, the multiple LLM distributions can be $\textit{combined}$ to $\textit{predict}$ each human judge's annotations on all questions, including a summary question that assesses overall quality or relevance. LLM-Rubric accomplishes this by training a small feed-forward neural network that includes both judge-specific and judge-independent parameters. When evaluating dialogue systems in a human-AI information-seeking task, we find that LLM-Rubric with 9 questions (assessing dimensions such as naturalness, conciseness, and citation quality) predicts human judges' assessment of overall user satisfaction, on a scale of 1--4, with RMS error $< 0.5$, a $2\times$ improvement over the uncalibrated baseline.
* Updated version of 17 June 2024
AgentInstruct: Toward Generative Teaching with Agentic Flows
Jul 03, 2024



Synthetic data is becoming increasingly important for accelerating the development of language models, both large and small. Despite several successful use cases, researchers also raised concerns around model collapse and drawbacks of imitating other models. This discrepancy can be attributed to the fact that synthetic data varies in quality and diversity. Effective use of synthetic data usually requires significant human effort in curating the data. We focus on using synthetic data for post-training, specifically creating data by powerful models to teach a new skill or behavior to another model, we refer to this setting as Generative Teaching. We introduce AgentInstruct, an extensible agentic framework for automatically creating large amounts of diverse and high-quality synthetic data. AgentInstruct can create both the prompts and responses, using only raw data sources like text documents and code files as seeds. We demonstrate the utility of AgentInstruct by creating a post training dataset of 25M pairs to teach language models different skills, such as text editing, creative writing, tool usage, coding, reading comprehension, etc. The dataset can be used for instruction tuning of any base model. We post-train Mistral-7b with the data. When comparing the resulting model Orca-3 to Mistral-7b-Instruct (which uses the same base model), we observe significant improvements across many benchmarks. For example, 40% improvement on AGIEval, 19% improvement on MMLU, 54% improvement on GSM8K, 38% improvement on BBH and 45% improvement on AlpacaEval. Additionally, it consistently outperforms other models such as LLAMA-8B-instruct and GPT-3.5-turbo.
Exploratory Preference Optimization: Harnessing Implicit Q*-Approximation for Sample-Efficient RLHF
May 31, 2024

Reinforcement learning from human feedback (RLHF) has emerged as a central tool for language model alignment. We consider online exploration in RLHF, which exploits interactive access to human or AI feedback by deliberately encouraging the model to produce diverse, maximally informative responses. By allowing RLHF to confidently stray from the pre-trained model, online exploration offers the possibility of novel, potentially super-human capabilities, but its full potential as a paradigm for language model training has yet to be realized, owing to computational and statistical bottlenecks in directly adapting existing reinforcement learning techniques. We propose a new algorithm for online exploration in RLHF, Exploratory Preference Optimization (XPO), which is simple and practical -- a one-line change to (online) Direct Preference Optimization (DPO; Rafailov et al., 2023) -- yet enjoys the strongest known provable guarantees and promising empirical performance. XPO augments the DPO objective with a novel and principled exploration bonus, empowering the algorithm to explore outside the support of the initial model and human feedback data. In theory, we show that XPO is provably sample-efficient and converges to a near-optimal language model policy under natural exploration conditions, irrespective of whether the initial model has good coverage. Our analysis, which builds on the observation that DPO implicitly performs a form of $Q^{\star}$-approximation (or, Bellman error minimization), combines previously disparate techniques from language modeling and theoretical reinforcement learning in a serendipitous fashion through the perspective of KL-regularized Markov decision processes. Empirically, we find that XPO is more sample-efficient than non-exploratory DPO variants in a preliminary evaluation.
MS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels
May 13, 2024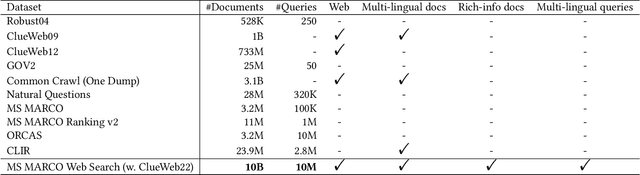
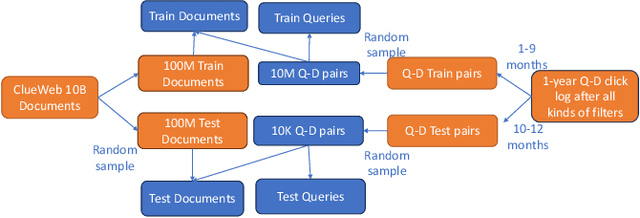
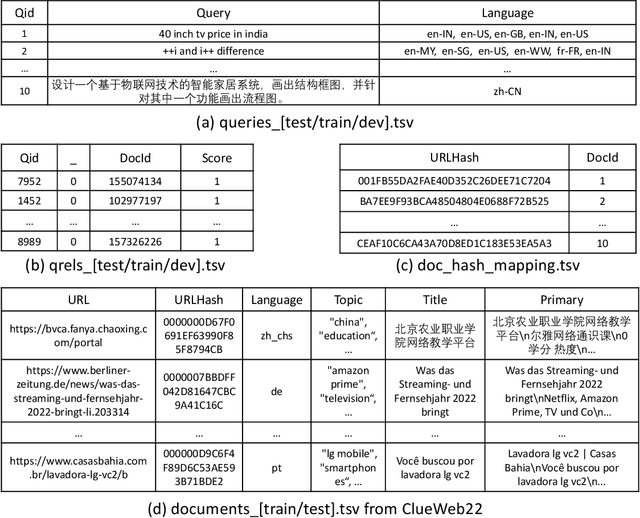
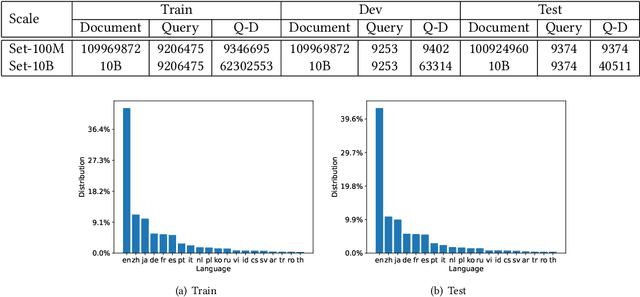
Recent breakthroughs in large models have highlighted the critical significance of data scale, labels and modals. In this paper, we introduce MS MARCO Web Search, the first large-scale information-rich web dataset, featuring millions of real clicked query-document labels. This dataset closely mimics real-world web document and query distribution, provides rich information for various kinds of downstream tasks and encourages research in various areas, such as generic end-to-end neural indexer models, generic embedding models, and next generation information access system with large language models. MS MARCO Web Search offers a retrieval benchmark with three web retrieval challenge tasks that demand innovations in both machine learning and information retrieval system research domains. As the first dataset that meets large, real and rich data requirements, MS MARCO Web Search paves the way for future advancements in AI and system research. MS MARCO Web Search dataset is available at: https://github.com/microsoft/MS-MARCO-Web-Search.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Direct Nash Optimization: Teaching Language Models to Self-Improve with General Preferences
Apr 04, 2024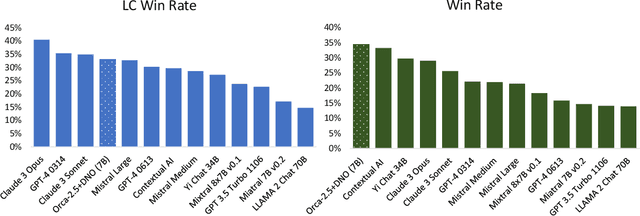
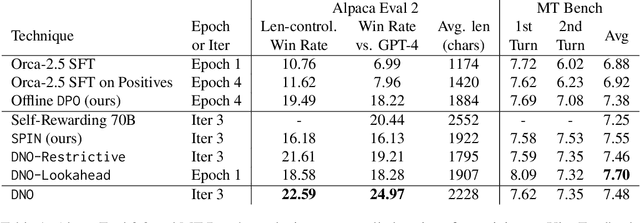
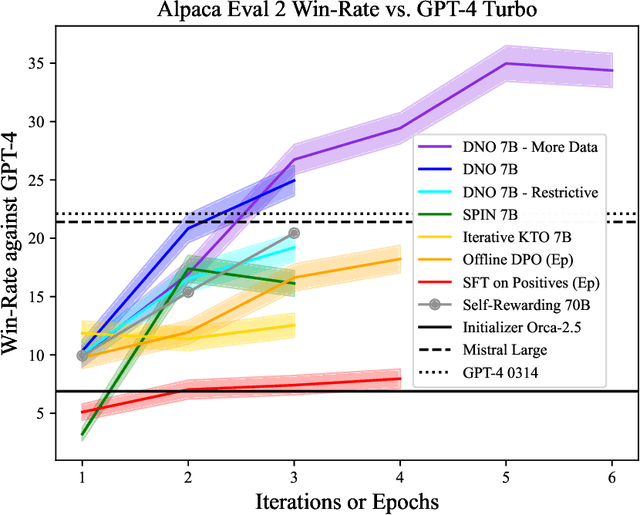
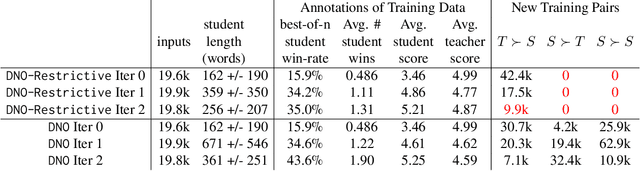
This paper studies post-training large language models (LLMs) using preference feedback from a powerful oracle to help a model iteratively improve over itself. The typical approach for post-training LLMs involves Reinforcement Learning from Human Feedback (RLHF), which traditionally separates reward learning and subsequent policy optimization. However, such a reward maximization approach is limited by the nature of "point-wise" rewards (such as Bradley-Terry model), which fails to express complex intransitive or cyclic preference relations. While advances on RLHF show reward learning and policy optimization can be merged into a single contrastive objective for stability, they yet still remain tethered to the reward maximization framework. Recently, a new wave of research sidesteps the reward maximization presumptions in favor of directly optimizing over "pair-wise" or general preferences. In this paper, we introduce Direct Nash Optimization (DNO), a provable and scalable algorithm that marries the simplicity and stability of contrastive learning with theoretical generality from optimizing general preferences. Because DNO is a batched on-policy algorithm using a regression-based objective, its implementation is straightforward and efficient. Moreover, DNO enjoys monotonic improvement across iterations that help it improve even over a strong teacher (such as GPT-4). In our experiments, a resulting 7B parameter Orca-2.5 model aligned by DNO achieves the state-of-the-art win-rate against GPT-4-Turbo of 33% on AlpacaEval 2.0 (even after controlling for response length), an absolute gain of 26% (7% to 33%) over the initializing model. It outperforms models with far more parameters, including Mistral Large, Self-Rewarding LM (70B parameters), and older versions of GPT-4.
Researchy Questions: A Dataset of Multi-Perspective, Decompositional Questions for LLM Web Agents
Feb 27, 2024



Existing question answering (QA) datasets are no longer challenging to most powerful Large Language Models (LLMs). Traditional QA benchmarks like TriviaQA, NaturalQuestions, ELI5 and HotpotQA mainly study ``known unknowns'' with clear indications of both what information is missing, and how to find it to answer the question. Hence, good performance on these benchmarks provides a false sense of security. A yet unmet need of the NLP community is a bank of non-factoid, multi-perspective questions involving a great deal of unclear information needs, i.e. ``unknown uknowns''. We claim we can find such questions in search engine logs, which is surprising because most question-intent queries are indeed factoid. We present Researchy Questions, a dataset of search engine queries tediously filtered to be non-factoid, ``decompositional'' and multi-perspective. We show that users spend a lot of ``effort'' on these questions in terms of signals like clicks and session length, and that they are also challenging for GPT-4. We also show that ``slow thinking'' answering techniques, like decomposition into sub-questions shows benefit over answering directly. We release $\sim$ 100k Researchy Questions, along with the Clueweb22 URLs that were clicked.
Orca-Math: Unlocking the potential of SLMs in Grade School Math
Feb 16, 2024Mathematical word problem-solving has long been recognized as a complex task for small language models (SLMs). A recent study hypothesized that the smallest model size, needed to achieve over 80% accuracy on the GSM8K benchmark, is 34 billion parameters. To reach this level of performance with smaller models, researcher often train SLMs to generate Python code or use tools to help avoid calculation errors. Additionally, they employ ensembling, where outputs of up to 100 model runs are combined to arrive at a more accurate result. Result selection is done using consensus, majority vote or a separate a verifier model used in conjunction with the SLM. Ensembling provides a substantial boost in accuracy but at a significant cost increase with multiple calls to the model (e.g., Phi-GSM uses top-48 to boost the performance from 68.2 to 81.5). In this work, we present Orca-Math, a 7-billion-parameter SLM based on the Mistral-7B, which achieves 86.81% on GSM8k without the need for multiple model calls or the use of verifiers, code execution or any other external tools. Our approach has the following key elements: (1) A high quality synthetic dataset of 200K math problems created using a multi-agent setup where agents collaborate to create the data, (2) An iterative learning techniques that enables the SLM to practice solving problems, receive feedback on its solutions and learn from preference pairs incorporating the SLM solutions and the feedback. When trained with Supervised Fine-Tuning alone, Orca-Math achieves 81.50% on GSM8k pass@1 metric. With iterative preference learning, Orca-Math achieves 86.81% pass@1. Orca-Math surpasses the performance of significantly larger models such as LLAMA-2-70B, WizardMath-70B, Gemini-Pro, ChatGPT-3.5. It also significantly outperforms other smaller models while using much smaller data (hundreds of thousands vs. millions of problems).