 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Image-Level Morphological Trait Annotation for Organismal Images
Apr 02, 2026Morphological traits are physical characteristics of biological organisms that provide vital clues on how organisms interact with their environment. Yet extracting these traits remains a slow, expert-driven process, limiting their use in large-scale ecological studies. A major bottleneck is the absence of high-quality datasets linking biological images to trait-level annotations. In this work, we demonstrate that sparse autoencoders trained on foundation-model features yield monosemantic, spatially grounded neurons that consistently activate on meaningful morphological parts. Leveraging this property, we introduce a trait annotation pipeline that localizes salient regions and uses vision-language prompting to generate interpretable trait descriptions. Using this approach, we construct Bioscan-Traits, a dataset of 80K trait annotations spanning 19K insect images from BIOSCAN-5M. Human evaluation confirms the biological plausibility of the generated morphological descriptions. We assess design sensitivity through a comprehensive ablation study, systematically varying key design choices and measuring their impact on the quality of the resulting trait descriptions. By annotating traits with a modular pipeline rather than prohibitively expensive manual efforts, we offer a scalable way to inject biologically meaningful supervision into foundation models, enable large-scale morphological analyses, and bridge the gap between ecological relevance and machine-learning practicality.
* ICLR 2026
Explorer: Scaling Exploration-driven Web Trajectory Synthesis for Multimodal Web Agents
Feb 19, 2025Recent success in large multimodal models (LMMs) has sparked promising applications of agents capable of autonomously completing complex web tasks. While open-source LMM agents have made significant advances in offline evaluation benchmarks, their performance still falls substantially short of human-level capabilities in more realistic online settings. A key bottleneck is the lack of diverse and large-scale trajectory-level datasets across various domains, which are expensive to collect. In this paper, we address this challenge by developing a scalable recipe to synthesize the largest and most diverse trajectory-level dataset to date, containing over 94K successful multimodal web trajectories, spanning 49K unique URLs, 720K screenshots, and 33M web elements. In particular, we leverage extensive web exploration and refinement to obtain diverse task intents. The average cost is 28 cents per successful trajectory, making it affordable to a wide range of users in the community. Leveraging this dataset, we train Explorer, a multimodal web agent, and demonstrate strong performance on both offline and online web agent benchmarks such as Mind2Web-Live, Multimodal-Mind2Web, and MiniWob++. Additionally, our experiments highlight data scaling as a key driver for improving web agent capabilities. We hope this study makes state-of-the-art LMM-based agent research at a larger scale more accessible.
Fine-Tuning is Fine, if Calibrated
Sep 24, 2024



Fine-tuning is arguably the most straightforward way to tailor a pre-trained model (e.g., a foundation model) to downstream applications, but it also comes with the risk of losing valuable knowledge the model had learned in pre-training. For example, fine-tuning a pre-trained classifier capable of recognizing a large number of classes to master a subset of classes at hand is shown to drastically degrade the model's accuracy in the other classes it had previously learned. As such, it is hard to further use the fine-tuned model when it encounters classes beyond the fine-tuning data. In this paper, we systematically dissect the issue, aiming to answer the fundamental question, ''What has been damaged in the fine-tuned model?'' To our surprise, we find that the fine-tuned model neither forgets the relationship among the other classes nor degrades the features to recognize these classes. Instead, the fine-tuned model often produces more discriminative features for these other classes, even if they were missing during fine-tuning! {What really hurts the accuracy is the discrepant logit scales between the fine-tuning classes and the other classes}, implying that a simple post-processing calibration would bring back the pre-trained model's capability and at the same time unveil the feature improvement over all classes. We conduct an extensive empirical study to demonstrate the robustness of our findings and provide preliminary explanations underlying them, suggesting new directions for future theoretical analysis. Our code is available at https://github.com/OSU-MLB/Fine-Tuning-Is-Fine-If-Calibrated.
Bringing Back the Context: Camera Trap Species Identification as Link Prediction on Multimodal Knowledge Graphs
Jan 08, 2024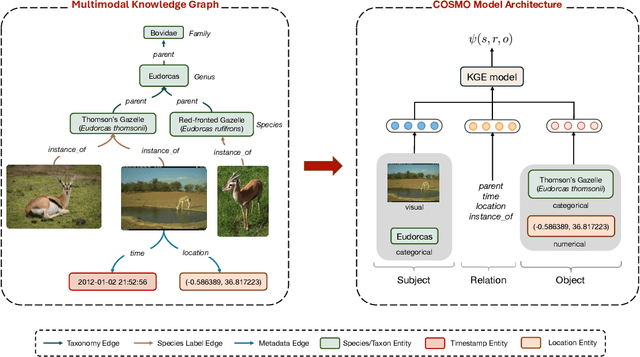
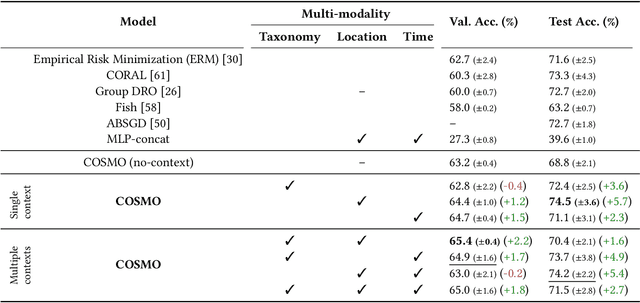
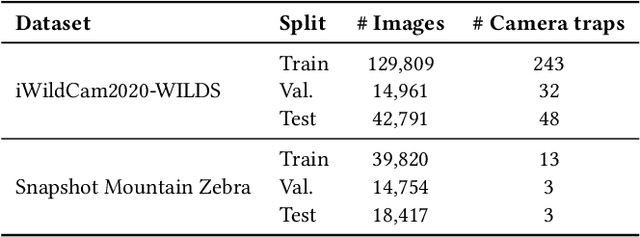
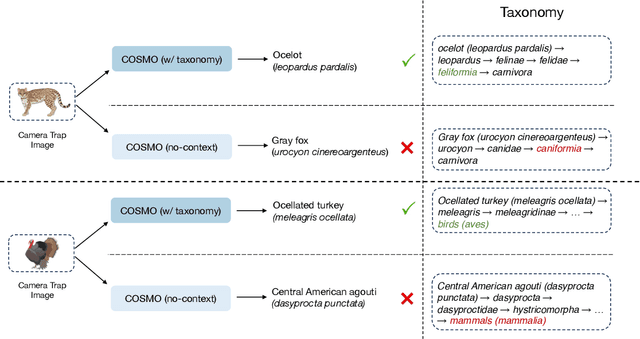
Camera traps are valuable tools in animal ecology for biodiversity monitoring and conservation. However, challenges like poor generalization to deployment at new unseen locations limit their practical application. Images are naturally associated with heterogeneous forms of context possibly in different modalities. In this work, we leverage the structured context associated with the camera trap images to improve out-of-distribution generalization for the task of species identification in camera traps. For example, a photo of a wild animal may be associated with information about where and when it was taken, as well as structured biology knowledge about the animal species. While typically overlooked by existing work, bringing back such context offers several potential benefits for better image understanding, such as addressing data scarcity and enhancing generalization. However, effectively integrating such heterogeneous context into the visual domain is a challenging problem. To address this, we propose a novel framework that reformulates species classification as link prediction in a multimodal knowledge graph (KG). This framework seamlessly integrates various forms of multimodal context for visual recognition. We apply this framework for out-of-distribution species classification on the iWildCam2020-WILDS and Snapshot Mountain Zebra datasets and achieve competitive performance with state-of-the-art approaches. Furthermore, our framework successfully incorporates biological taxonomy for improved generalization and enhances sample efficiency for recognizing under-represented species.
Holistic Transfer: Towards Non-Disruptive Fine-Tuning with Partial Target Data
Nov 02, 2023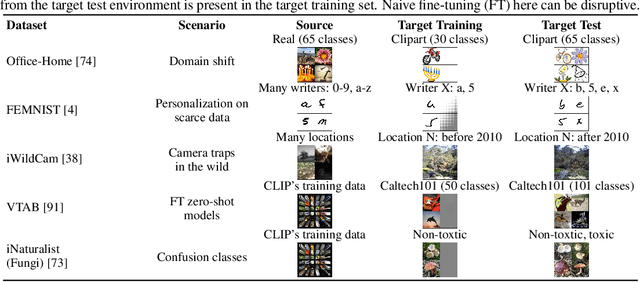
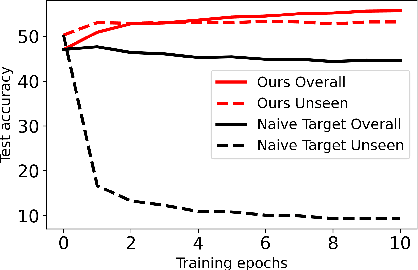
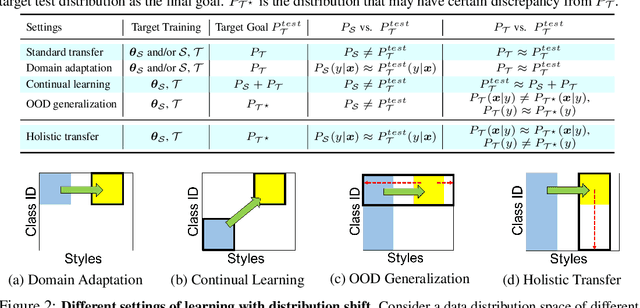
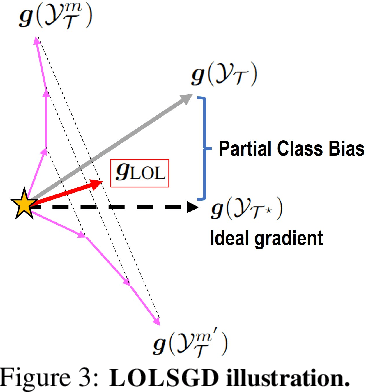
We propose a learning problem involving adapting a pre-trained source model to the target domain for classifying all classes that appeared in the source data, using target data that covers only a partial label space. This problem is practical, as it is unrealistic for the target end-users to collect data for all classes prior to adaptation. However, it has received limited attention in the literature. To shed light on this issue, we construct benchmark datasets and conduct extensive experiments to uncover the inherent challenges. We found a dilemma -- on the one hand, adapting to the new target domain is important to claim better performance; on the other hand, we observe that preserving the classification accuracy of classes missing in the target adaptation data is highly challenging, let alone improving them. To tackle this, we identify two key directions: 1) disentangling domain gradients from classification gradients, and 2) preserving class relationships. We present several effective solutions that maintain the accuracy of the missing classes and enhance the overall performance, establishing solid baselines for holistic transfer of pre-trained models with partial target data.
Diversifying Joint Vision-Language Tokenization Learning
Jun 15, 2023Building joint representations across images and text is an essential step for tasks such as Visual Question Answering and Video Question Answering. In this work, we find that the representations must not only jointly capture features from both modalities but should also be diverse for better generalization performance. To this end, we propose joint vision-language representation learning by diversifying the tokenization learning process, enabling tokens that are sufficiently disentangled from each other to be learned from both modalities. We observe that our approach outperforms the baseline models in a majority of settings and is competitive with state-of-the-art methods.
A Retrieve-and-Read Framework for Knowledge Graph Link Prediction
Dec 19, 2022Knowledge graph (KG) link prediction aims to infer new facts based on existing facts in the KG. Recent studies have shown that using the graph neighborhood of a node via graph neural networks (GNNs) provides more useful information compared to just using the query information. Conventional GNNs for KG link prediction follow the standard message-passing paradigm on the entire KG, which leads to over-smoothing of representations and also limits their scalability. On a large scale, it becomes computationally expensive to aggregate useful information from the entire KG for inference. To address the limitations of existing KG link prediction frameworks, we propose a novel retrieve-and-read framework, which first retrieves a relevant subgraph context for the query and then jointly reasons over the context and the query with a high-capacity reader. As part of our exemplar instantiation for the new framework, we propose a novel Transformer-based GNN as the reader, which incorporates graph-based attention structure and cross-attention between query and context for deep fusion. This design enables the model to focus on salient context information relevant to the query. Empirical results on two standard KG link prediction datasets demonstrate the competitive performance of the proposed method.
Knowledge Base Question Answering: A Semantic Parsing Perspective
Sep 18, 2022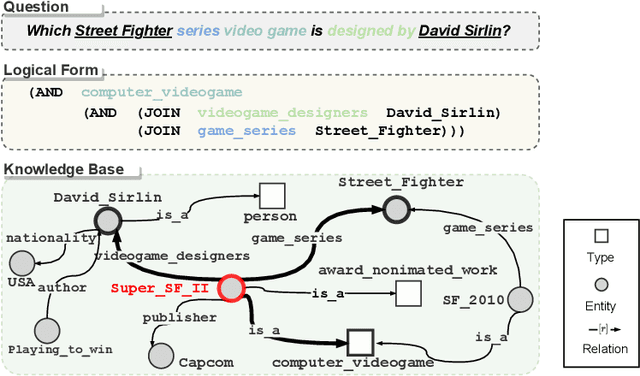
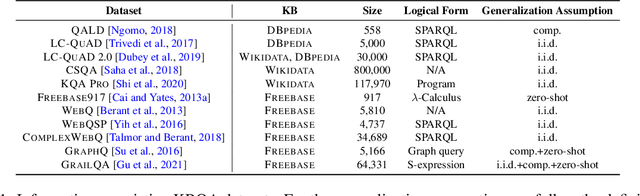

Recent advances in deep learning have greatly propelled the research on semantic parsing. Improvement has since been made in many downstream tasks, including natural language interface to web APIs, text-to-SQL generation, among others. However, despite the close connection shared with these tasks, research on question answering over knowledge bases (KBQA) has comparatively been progressing slowly. We identify and attribute this to two unique challenges of KBQA, schema-level complexity and fact-level complexity. In this survey, we situate KBQA in the broader literature of semantic parsing and give a comprehensive account of how existing KBQA approaches attempt to address the unique challenges. Regardless of the unique challenges, we argue that we can still take much inspiration from the literature of semantic parsing, which has been overlooked by existing research on KBQA. Based on our discussion, we can better understand the bottleneck of current KBQA research and shed light on promising directions for KBQA to keep up with the literature of semantic parsing, particularly in the era of pre-trained language models.
A Systematic Investigation of KB-Text Embedding Alignment at Scale
Jun 03, 2021
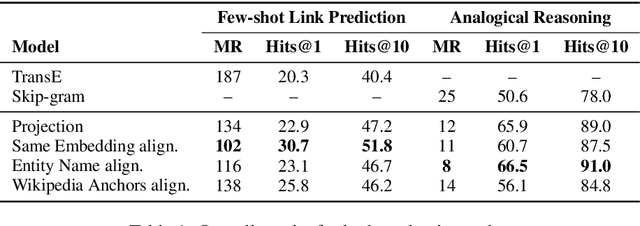
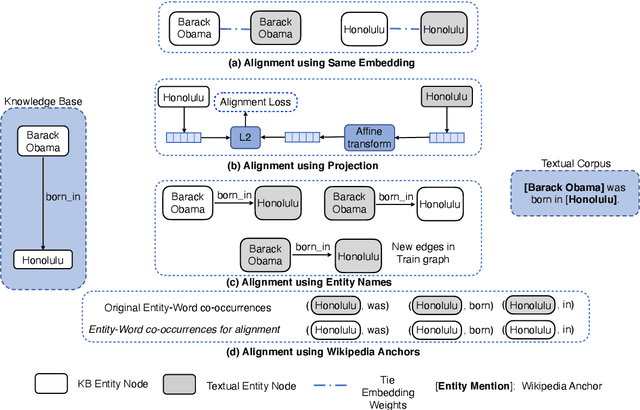
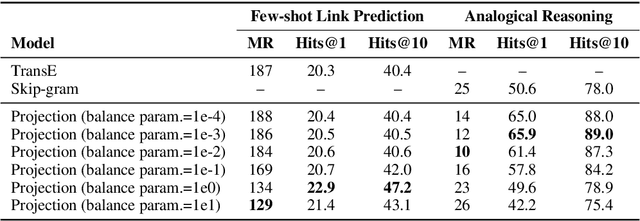
Knowledge bases (KBs) and text often contain complementary knowledge: KBs store structured knowledge that can support long range reasoning, while text stores more comprehensive and timely knowledge in an unstructured way. Separately embedding the individual knowledge sources into vector spaces has demonstrated tremendous successes in encoding the respective knowledge, but how to jointly embed and reason with both knowledge sources to fully leverage the complementary information is still largely an open problem. We conduct a large-scale, systematic investigation of aligning KB and text embeddings for joint reasoning. We set up a novel evaluation framework with two evaluation tasks, few-shot link prediction and analogical reasoning, and evaluate an array of KB-text embedding alignment methods. We also demonstrate how such alignment can infuse textual information into KB embeddings for more accurate link prediction on emerging entities and events, using COVID-19 as a case study.
Learning Sparse Mixture of Experts for Visual Question Answering
Sep 19, 2019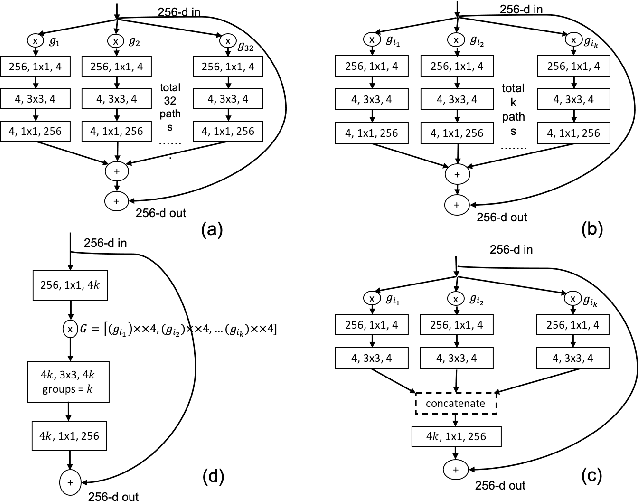
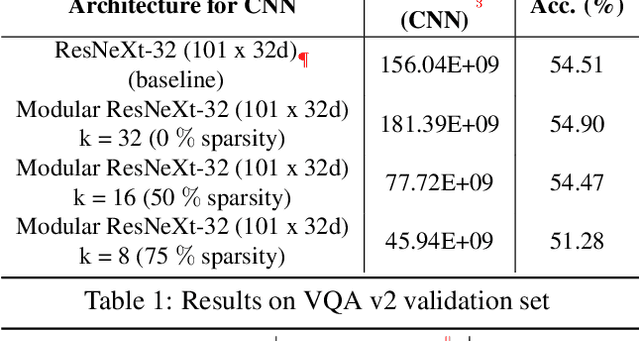

There has been a rapid progress in the task of Visual Question Answering with improved model architectures. Unfortunately, these models are usually computationally intensive due to their sheer size which poses a serious challenge for deployment. We aim to tackle this issue for the specific task of Visual Question Answering (VQA). A Convolutional Neural Network (CNN) is an integral part of the visual processing pipeline of a VQA model (assuming the CNN is trained along with entire VQA model). In this project, we propose an efficient and modular neural architecture for the VQA task with focus on the CNN module. Our experiments demonstrate that a sparsely activated CNN based VQA model achieves comparable performance to a standard CNN based VQA model architecture.