 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Inverse Probability Treatment Weighting for Individual Treatment Effect Estimation
Mar 06, 2025Individual treatment effect (ITE) estimation is to evaluate the causal effects of treatment strategies on some important outcomes, which is a crucial problem in healthcare. Most existing ITE estimation methods are designed for centralized settings. However, in real-world clinical scenarios, the raw data are usually not shareable among hospitals due to the potential privacy and security risks, which makes the methods not applicable. In this work, we study the ITE estimation task in a federated setting, which allows us to harness the decentralized data from multiple hospitals. Due to the unavoidable confounding bias in the collected data, a model directly learned from it would be inaccurate. One well-known solution is Inverse Probability Treatment Weighting (IPTW), which uses the conditional probability of treatment given the covariates to re-weight each training example. Applying IPTW in a federated setting, however, is non-trivial. We found that even with a well-estimated conditional probability, the local model training step using each hospital's data alone would still suffer from confounding bias. To address this, we propose FED-IPTW, a novel algorithm to extend IPTW into a federated setting that enforces both global (over all the data) and local (within each hospital) decorrelation between covariates and treatments. We validated our approach on the task of comparing the treatment effects of mechanical ventilation on improving survival probability for patients with breadth difficulties in the intensive care unit (ICU). We conducted experiments on both synthetic and real-world eICU datasets and the results show that FED-IPTW outperform state-of-the-art methods on all the metrics on factual prediction and ITE estimation tasks, paving the way for personalized treatment strategy design in mechanical ventilation usage.
CLIP-UP: A Simple and Efficient Mixture-of-Experts CLIP Training Recipe with Sparse Upcycling
Feb 03, 2025



Mixture-of-Experts (MoE) models are crucial for scaling model capacity while controlling inference costs. While integrating MoE into multimodal models like CLIP improves performance, training these models is notoriously challenging and expensive. We propose CLIP-Upcycling (CLIP-UP), an efficient alternative training strategy that converts a pre-trained dense CLIP model into a sparse MoE architecture. Through extensive experimentation with various settings and auxiliary losses, we demonstrate that CLIP-UP significantly reduces training complexity and cost. Remarkably, our sparse CLIP B/16 model, trained with CLIP-UP, outperforms its dense counterpart by 7.2% and 6.6% on COCO and Flickr30k text-to-image Recall@1 benchmarks respectively. It even surpasses the larger CLIP L/14 model on this task while using only 30% of the inference FLOPs. We further demonstrate the generalizability of our training recipe across different scales, establishing sparse upcycling as a practical and scalable approach for building efficient, high-performance CLIP models.
Revisit Large-Scale Image-Caption Data in Pre-training Multimodal Foundation Models
Oct 03, 2024Recent advancements in multimodal models highlight the value of rewritten captions for improving performance, yet key challenges remain. For example, while synthetic captions often provide superior quality and image-text alignment, it is not clear whether they can fully replace AltTexts: the role of synthetic captions and their interaction with original web-crawled AltTexts in pre-training is still not well understood. Moreover, different multimodal foundation models may have unique preferences for specific caption formats, but efforts to identify the optimal captions for each model remain limited. In this work, we propose a novel, controllable, and scalable captioning pipeline designed to generate diverse caption formats tailored to various multimodal models. By examining Short Synthetic Captions (SSC) towards Dense Synthetic Captions (DSC+) as case studies, we systematically explore their effects and interactions with AltTexts across models such as CLIP, multimodal LLMs, and diffusion models. Our findings reveal that a hybrid approach that keeps both synthetic captions and AltTexts can outperform the use of synthetic captions alone, improving both alignment and performance, with each model demonstrating preferences for particular caption formats. This comprehensive analysis provides valuable insights into optimizing captioning strategies, thereby advancing the pre-training of multimodal foundation models.
Contrastive Localized Language-Image Pre-Training
Oct 03, 2024



Contrastive Language-Image Pre-training (CLIP) has been a celebrated method for training vision encoders to generate image/text representations facilitating various applications. Recently, CLIP has been widely adopted as the vision backbone of multimodal large language models (MLLMs) to connect image inputs for language interactions. The success of CLIP as a vision-language foundation model relies on aligning web-crawled noisy text annotations at image levels. Nevertheless, such criteria may become insufficient for downstream tasks in need of fine-grained vision representations, especially when region-level understanding is demanding for MLLMs. In this paper, we improve the localization capability of CLIP with several advances. We propose a pre-training method called Contrastive Localized Language-Image Pre-training (CLOC) by complementing CLIP with region-text contrastive loss and modules. We formulate a new concept, promptable embeddings, of which the encoder produces image embeddings easy to transform into region representations given spatial hints. To support large-scale pre-training, we design a visually-enriched and spatially-localized captioning framework to effectively generate region-text pseudo-labels at scale. By scaling up to billions of annotated images, CLOC enables high-quality regional embeddings for image region recognition and retrieval tasks, and can be a drop-in replacement of CLIP to enhance MLLMs, especially on referring and grounding tasks.
MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
Sep 30, 2024
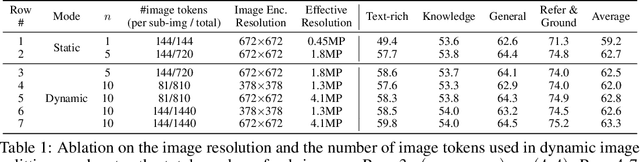

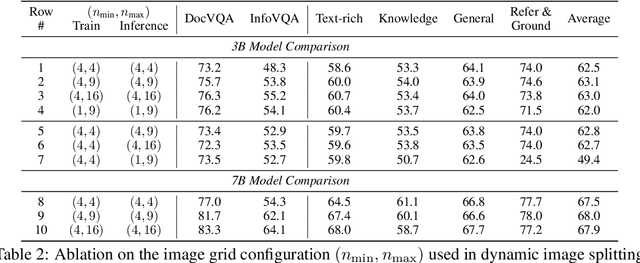
We present MM1.5, a new family of multimodal large language models (MLLMs) designed to enhance capabilities in text-rich image understanding, visual referring and grounding, and multi-image reasoning. Building upon the MM1 architecture, MM1.5 adopts a data-centric approach to model training, systematically exploring the impact of diverse data mixtures across the entire model training lifecycle. This includes high-quality OCR data and synthetic captions for continual pre-training, as well as an optimized visual instruction-tuning data mixture for supervised fine-tuning. Our models range from 1B to 30B parameters, encompassing both dense and mixture-of-experts (MoE) variants, and demonstrate that careful data curation and training strategies can yield strong performance even at small scales (1B and 3B). Additionally, we introduce two specialized variants: MM1.5-Video, designed for video understanding, and MM1.5-UI, tailored for mobile UI understanding. Through extensive empirical studies and ablations, we provide detailed insights into the training processes and decisions that inform our final designs, offering valuable guidance for future research in MLLM development.
Fine-Tuning is Fine, if Calibrated
Sep 24, 2024



Fine-tuning is arguably the most straightforward way to tailor a pre-trained model (e.g., a foundation model) to downstream applications, but it also comes with the risk of losing valuable knowledge the model had learned in pre-training. For example, fine-tuning a pre-trained classifier capable of recognizing a large number of classes to master a subset of classes at hand is shown to drastically degrade the model's accuracy in the other classes it had previously learned. As such, it is hard to further use the fine-tuned model when it encounters classes beyond the fine-tuning data. In this paper, we systematically dissect the issue, aiming to answer the fundamental question, ''What has been damaged in the fine-tuned model?'' To our surprise, we find that the fine-tuned model neither forgets the relationship among the other classes nor degrades the features to recognize these classes. Instead, the fine-tuned model often produces more discriminative features for these other classes, even if they were missing during fine-tuning! {What really hurts the accuracy is the discrepant logit scales between the fine-tuning classes and the other classes}, implying that a simple post-processing calibration would bring back the pre-trained model's capability and at the same time unveil the feature improvement over all classes. We conduct an extensive empirical study to demonstrate the robustness of our findings and provide preliminary explanations underlying them, suggesting new directions for future theoretical analysis. Our code is available at https://github.com/OSU-MLB/Fine-Tuning-Is-Fine-If-Calibrated.
Lessons Learned from a Unifying Empirical Study of Parameter-Efficient Transfer Learning (PETL) in Visual Recognition
Sep 24, 2024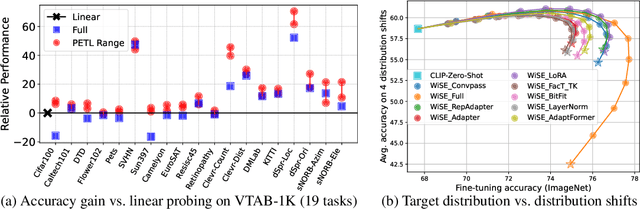
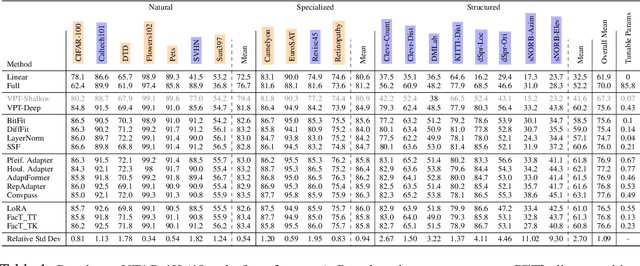


Parameter-efficient transfer learning (PETL) has attracted significant attention lately, due to the increasing size of pre-trained models and the need to fine-tune (FT) them for superior downstream performance. This community-wide enthusiasm has sparked a plethora of new methods. Nevertheless, a systematic study to understand their performance and suitable application scenarios is lacking, leaving questions like when to apply PETL and which method to use largely unanswered. In this paper, we conduct a unifying empirical study of representative PETL methods in the context of Vision Transformers. We systematically tune their hyper-parameters to fairly compare their accuracy on downstream tasks. Our study not only offers a valuable user guide but also unveils several new insights. First, if tuned carefully, different PETL methods can obtain quite similar accuracy in the low-shot benchmark VTAB-1K. This includes simple methods like FT the bias terms that were reported inferior. Second, though with similar accuracy, we find that PETL methods make different mistakes and high-confidence predictions, likely due to their different inductive biases. Such an inconsistency (or complementariness) opens up the opportunity for ensemble methods, and we make preliminary attempts at this. Third, going beyond the commonly used low-shot tasks, we find that PETL is also useful in many-shot regimes -- it achieves comparable and sometimes better accuracy than full FT, using much fewer learnable parameters. Last but not least, we investigate PETL's ability to preserve a pre-trained model's robustness to distribution shifts (e.g., a CLIP backbone). Perhaps not surprisingly, PETL methods outperform full FT alone. However, with weight-space ensembles, the fully FT model can achieve a better balance between downstream and out-of-distribution performance, suggesting a future research direction for PETL.
FedNE: Surrogate-Assisted Federated Neighbor Embedding for Dimensionality Reduction
Sep 17, 2024



Federated learning (FL) has rapidly evolved as a promising paradigm that enables collaborative model training across distributed participants without exchanging their local data. Despite its broad applications in fields such as computer vision, graph learning, and natural language processing, the development of a data projection model that can be effectively used to visualize data in the context of FL is crucial yet remains heavily under-explored. Neighbor embedding (NE) is an essential technique for visualizing complex high-dimensional data, but collaboratively learning a joint NE model is difficult. The key challenge lies in the objective function, as effective visualization algorithms like NE require computing loss functions among pairs of data. In this paper, we introduce \textsc{FedNE}, a novel approach that integrates the \textsc{FedAvg} framework with the contrastive NE technique, without any requirements of shareable data. To address the lack of inter-client repulsion which is crucial for the alignment in the global embedding space, we develop a surrogate loss function that each client learns and shares with each other. Additionally, we propose a data-mixing strategy to augment the local data, aiming to relax the problems of invisible neighbors and false neighbors constructed by the local $k$NN graphs. We conduct comprehensive experiments on both synthetic and real-world datasets. The results demonstrate that our \textsc{FedNE} can effectively preserve the neighborhood data structures and enhance the alignment in the global embedding space compared to several baseline methods.
SlowFast-LLaVA: A Strong Training-Free Baseline for Video Large Language Models
Jul 22, 2024



We propose SlowFast-LLaVA (or SF-LLaVA for short), a training-free video large language model (LLM) that can jointly capture the detailed spatial semantics and long-range temporal context without exceeding the token budget of commonly used LLMs. This is realized by using a two-stream SlowFast design of inputs for Video LLMs to aggregate features from sampled video frames in an effective way. Specifically, the Slow pathway extracts features at a low frame rate while keeping as many spatial details as possible (e.g., with 24x24 tokens), and the Fast pathway operates on a high frame rate but uses a larger spatial pooling stride (e.g., downsampling 6x) to focus on the motion cues. As a result, this design allows us to adequately capture both spatial and temporal features that are beneficial for understanding details along the video. Experimental results show that SF-LLaVA outperforms existing training-free methods on a wide range of video tasks. On some benchmarks, it achieves comparable or even better performance compared to state-of-the-art Video LLMs that are fine-tuned on video datasets.
Jigsaw Game: Federated Clustering
Jul 17, 2024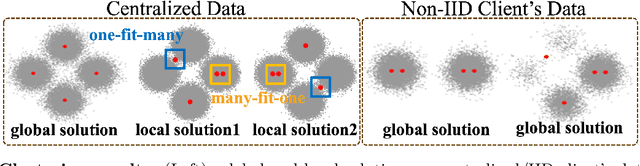
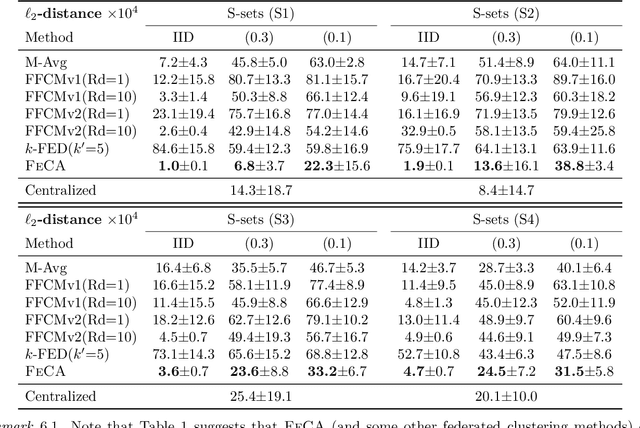
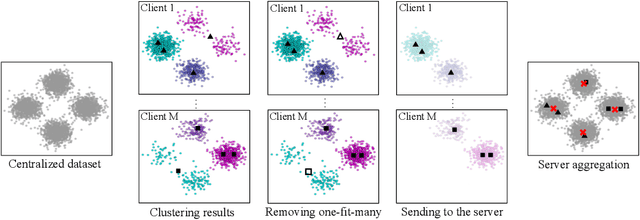
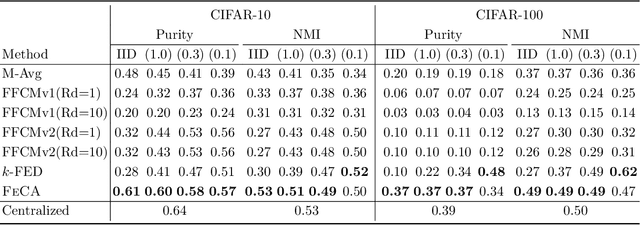
Federated learning has recently garnered significant attention, especially within the domain of supervised learning. However, despite the abundance of unlabeled data on end-users, unsupervised learning problems such as clustering in the federated setting remain underexplored. In this paper, we investigate the federated clustering problem, with a focus on federated k-means. We outline the challenge posed by its non-convex objective and data heterogeneity in the federated framework. To tackle these challenges, we adopt a new perspective by studying the structures of local solutions in k-means and propose a one-shot algorithm called FeCA (Federated Centroid Aggregation). FeCA adaptively refines local solutions on clients, then aggregates these refined solutions to recover the global solution of the entire dataset in a single round. We empirically demonstrate the robustness of FeCA under various federated scenarios on both synthetic and real-world data. Additionally, we extend FeCA to representation learning and present DeepFeCA, which combines DeepCluster and FeCA for unsupervised feature learning in the federated setting.