 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-UP: A Simple and Efficient Mixture-of-Experts CLIP Training Recipe with Sparse Upcycling
Feb 03, 2025



Mixture-of-Experts (MoE) models are crucial for scaling model capacity while controlling inference costs. While integrating MoE into multimodal models like CLIP improves performance, training these models is notoriously challenging and expensive. We propose CLIP-Upcycling (CLIP-UP), an efficient alternative training strategy that converts a pre-trained dense CLIP model into a sparse MoE architecture. Through extensive experimentation with various settings and auxiliary losses, we demonstrate that CLIP-UP significantly reduces training complexity and cost. Remarkably, our sparse CLIP B/16 model, trained with CLIP-UP, outperforms its dense counterpart by 7.2% and 6.6% on COCO and Flickr30k text-to-image Recall@1 benchmarks respectively. It even surpasses the larger CLIP L/14 model on this task while using only 30% of the inference FLOPs. We further demonstrate the generalizability of our training recipe across different scales, establishing sparse upcycling as a practical and scalable approach for building efficient, high-performance CLIP models.
Vartani Spellcheck -- Automatic Context-Sensitive Spelling Correction of OCR-generated Hindi Text Using BERT and Levenshtein Distance
Dec 14, 2020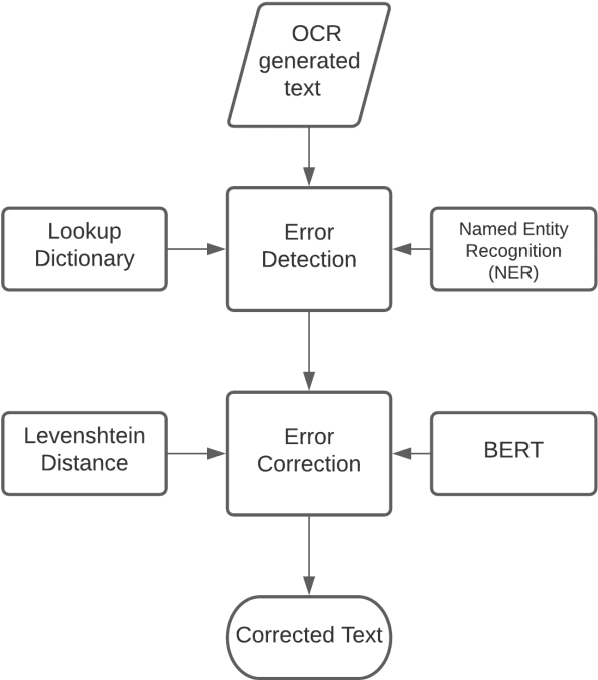
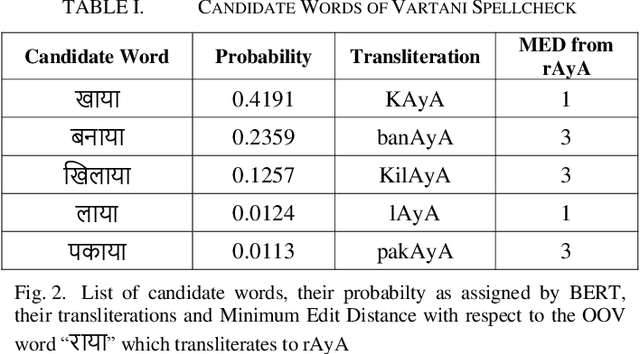
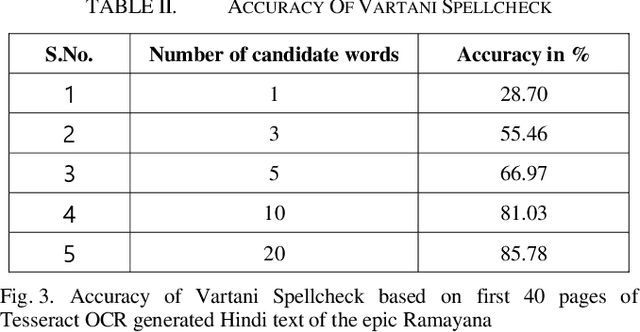
Traditional Optical Character Recognition (OCR) systems that generate text of highly inflectional Indic languages like Hindi tend to suffer from poor accuracy due to a wide alphabet set, compound characters and difficulty in segmenting characters in a word. Automatic spelling error detection and context-sensitive error correction can be used to improve accuracy by post-processing the text generated by these OCR systems. A majority of previously developed language models for error correction of Hindi spelling have been context-free. In this paper, we present Vartani Spellcheck - a context-sensitive approach for spelling correction of Hindi text using a state-of-the-art transformer - BERT in conjunction with the Levenshtein distance algorithm, popularly known as Edit Distance. We use a lookup dictionary and context-based named entity recognition (NER) for detection of possible spelling errors in the text. Our proposed technique has been tested on a large corpus of text generated by the widely used Tesseract OCR on the Hindi epic Ramayana. With an accuracy of 81%, the results show a significant improvement over some of the previously established context-sensitive error correction mechanisms for Hindi. We also explain how Vartani Spellcheck may be used for on-the-fly autocorrect suggestion during continuous typing in a text editor environment.
Anubhuti -- An annotated dataset for emotional analysis of Bengali short stories
Oct 06, 2020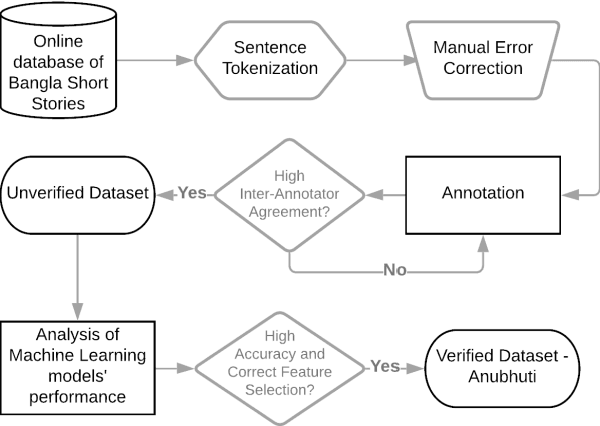
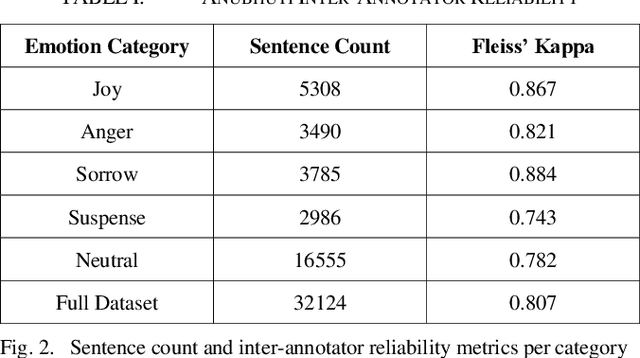
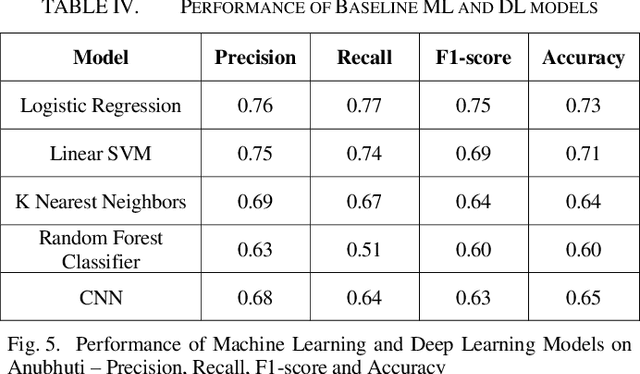
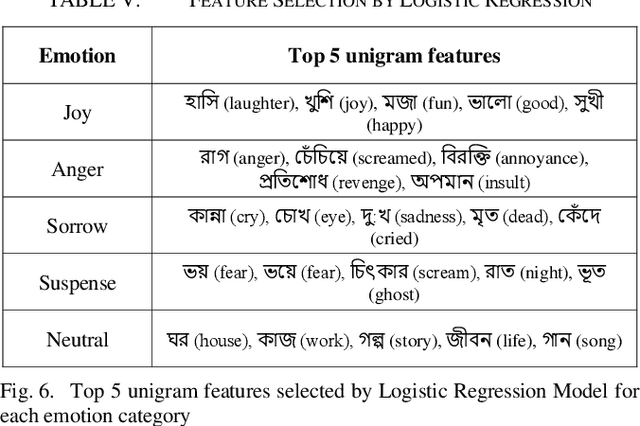
Thousands of short stories and articles are being written in many different languages all around the world today. Bengali, or Bangla, is the second highest spoken language in India after Hindi and is the national language of the country of Bangladesh. This work reports in detail the creation of Anubhuti -- the first and largest text corpus for analyzing emotions expressed by writers of Bengali short stories. We explain the data collection methods, the manual annotation process and the resulting high inter-annotator agreement of the dataset due to the linguistic expertise of the annotators and the clear methodology of labelling followed. We also address some of the challenges faced in the collection of raw data and annotation process of a low resource language like Bengali. We have verified the performance of our dataset with baseline Machine Learning as well as a Deep Learning model for emotion classification and have found that these standard models have a high accuracy and relevant feature selection on Anubhuti. In addition, we also explain how this dataset can be of interest to linguists and data analysts to study the flow of emotions as expressed by writers of Bengali literature.
PinnerSage: Multi-Modal User Embedding Framework for Recommendations at Pinterest
Jul 07, 2020

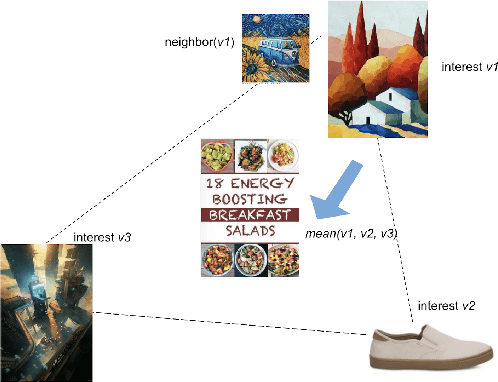

Latent user representations are widely adopted in the tech industry for powering personalized recommender systems. Most prior work infers a single high dimensional embedding to represent a user, which is a good starting point but falls short in delivering a full understanding of the user's interests. In this work, we introduce PinnerSage, an end-to-end recommender system that represents each user via multi-modal embeddings and leverages this rich representation of users to provides high quality personalized recommendations. PinnerSage achieves this by clustering users' actions into conceptually coherent clusters with the help of a hierarchical clustering method (Ward) and summarizes the clusters via representative pins (Medoids) for efficiency and interpretability. PinnerSage is deployed in production at Pinterest and we outline the several design decisions that makes it run seamlessly at a very large scale. We conduct several offline and online A/B experiments to show that our method significantly outperforms single embedding methods.
* 10 pages, 7 figures
Hierarchical Temporal Convolutional Networks for Dynamic Recommender Systems
Apr 10, 2019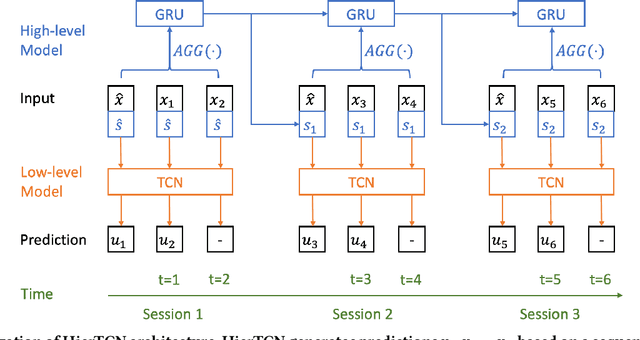
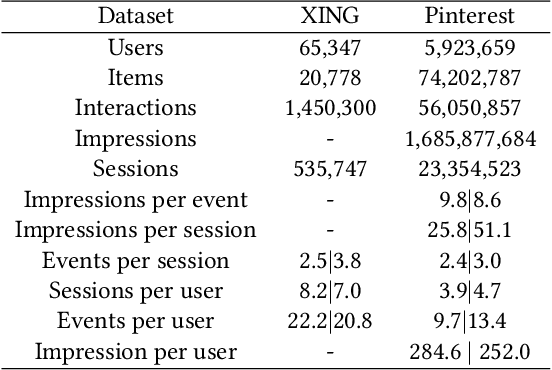
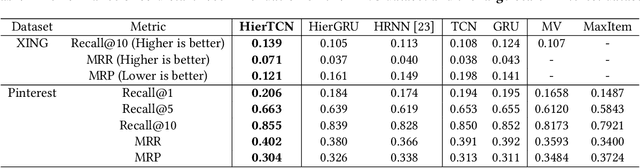
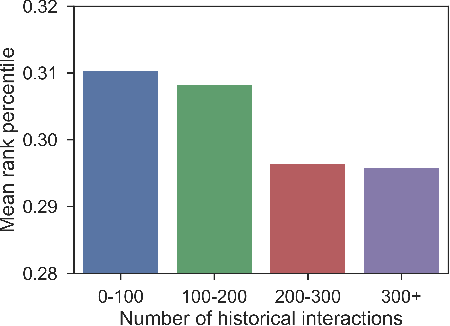
Recommender systems that can learn from cross-session data to dynamically predict the next item a user will choose are crucial for online platforms. However, existing approaches often use out-of-the-box sequence models which are limited by speed and memory consumption, are often infeasible for production environments, and usually do not incorporate cross-session information, which is crucial for effective recommendations. Here we propose Hierarchical Temporal Convolutional Networks (HierTCN), a hierarchical deep learning architecture that makes dynamic recommendations based on users' sequential multi-session interactions with items. HierTCN is designed for web-scale systems with billions of items and hundreds of millions of users. It consists of two levels of models: The high-level model uses Recurrent Neural Networks (RNN) to aggregate users' evolving long-term interests across different sessions, while the low-level model is implemented with Temporal Convolutional Networks (TCN), utilizing both the long-term interests and the short-term interactions within sessions to predict the next interaction. We conduct extensive experiments on a public XING dataset and a large-scale Pinterest dataset that contains 6 million users with 1.6 billion interactions. We show that HierTCN is 2.5x faster than RNN-based models and uses 90% less data memory compared to TCN-based models. We further develop an effective data caching scheme and a queue-based mini-batch generator, enabling our model to be trained within 24 hours on a single GPU. Our model consistently outperforms state-of-the-art dynamic recommendation methods, with up to 18% improvement in recall and 10% in mean reciprocal rank.