 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnubhuti -- An annotated dataset for emotional analysis of Bengali short stories
Oct 06, 2020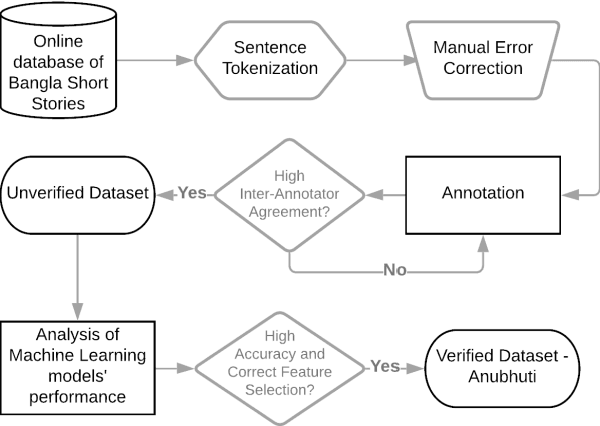
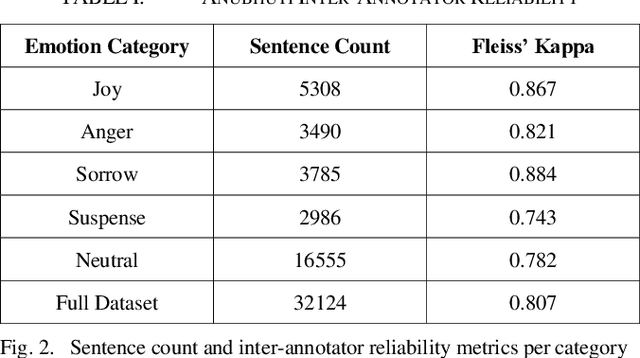
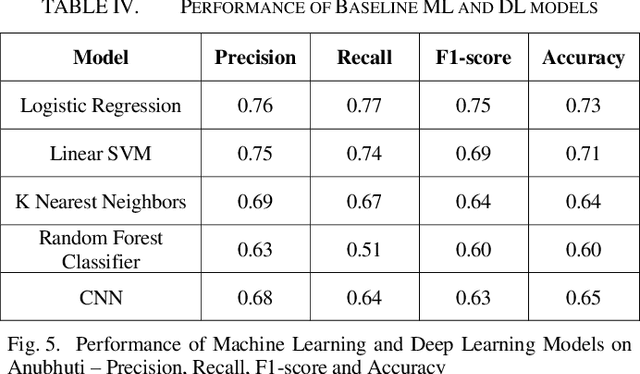
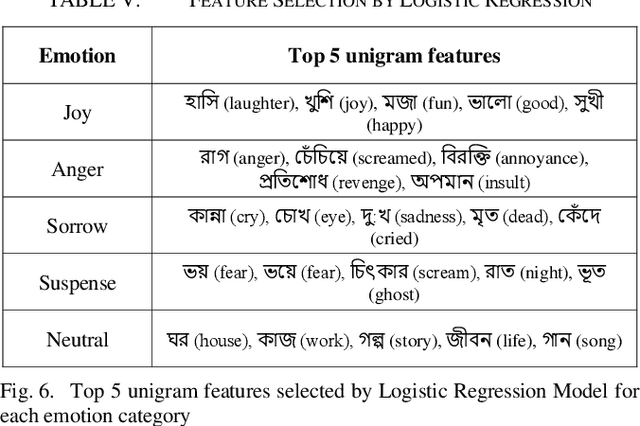
Thousands of short stories and articles are being written in many different languages all around the world today. Bengali, or Bangla, is the second highest spoken language in India after Hindi and is the national language of the country of Bangladesh. This work reports in detail the creation of Anubhuti -- the first and largest text corpus for analyzing emotions expressed by writers of Bengali short stories. We explain the data collection methods, the manual annotation process and the resulting high inter-annotator agreement of the dataset due to the linguistic expertise of the annotators and the clear methodology of labelling followed. We also address some of the challenges faced in the collection of raw data and annotation process of a low resource language like Bengali. We have verified the performance of our dataset with baseline Machine Learning as well as a Deep Learning model for emotion classification and have found that these standard models have a high accuracy and relevant feature selection on Anubhuti. In addition, we also explain how this dataset can be of interest to linguists and data analysts to study the flow of emotions as expressed by writers of Bengali literature.