 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePinCLIP: Large-scale Foundational Multimodal Representation at Pinterest
Mar 03, 2026While multi-modal Visual Language Models (VLMs) have demonstrated significant success across various domains, the integration of VLMs into recommendation and retrieval systems remains a challenge, due to issues like training objective discrepancies and serving efficiency bottlenecks. This paper introduces PinCLIP, a large-scale visual representation learning approach developed to enhance retrieval and ranking models at Pinterest by leveraging VLMs to learn image-text alignment. We propose a novel hybrid Vision Transformer architecture that utilizes a VLM backbone and a hybrid fusion mechanism to capture multi-modality content representation at varying granularities. Beyond standard image-to-text alignment objectives, we introduce a neighbor alignment objective to model the cross-fusion of multi-modal representations within the Pinterest Pin-Board graph. Offline evaluations show that PinCLIP outperforms state-of-the-art baselines, such as Qwen, by 20% in multi-modal retrieval tasks. Online A/B testing demonstrates significant business impact, including substantial engagement gains across all major surfaces in Pinterest. Notably, PinCLIP significantly addresses the "cold-start" problem, enhancing fresh content distribution with a 15% Repin increase in organic content and 8.7% higher click for new Ads.
Deep Reinforcement Learning for Ranking Utility Tuning in the Ad Recommender System at Pinterest
Sep 05, 2025



The ranking utility function in an ad recommender system, which linearly combines predictions of various business goals, plays a central role in balancing values across the platform, advertisers, and users. Traditional manual tuning, while offering simplicity and interpretability, often yields suboptimal results due to its unprincipled tuning objectives, the vast amount of parameter combinations, and its lack of personalization and adaptability to seasonality. In this work, we propose a general Deep Reinforcement Learning framework for Personalized Utility Tuning (DRL-PUT) to address the challenges of multi-objective optimization within ad recommender systems. Our key contributions include: 1) Formulating the problem as a reinforcement learning task: given the state of an ad request, we predict the optimal hyperparameters to maximize a pre-defined reward. 2) Developing an approach to directly learn an optimal policy model using online serving logs, avoiding the need to estimate a value function, which is inherently challenging due to the high variance and unbalanced distribution of immediate rewards. We evaluated DRL-PUT through an online A/B experiment in Pinterest's ad recommender system. Compared to the baseline manual utility tuning approach, DRL-PUT improved the click-through rate by 9.7% and the long click-through rate by 7.7% on the treated segment. We conducted a detailed ablation study on the impact of different reward definitions and analyzed the personalization aspect of the learned policy model.
OmniSage: Large Scale, Multi-Entity Heterogeneous Graph Representation Learning
May 01, 2025
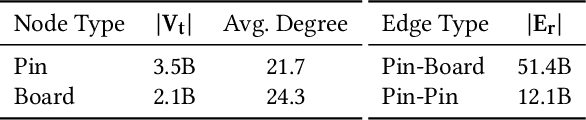
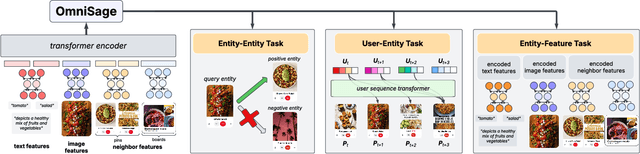

Representation learning, a task of learning latent vectors to represent entities, is a key task in improving search and recommender systems in web applications. Various representation learning methods have been developed, including graph-based approaches for relationships among entities, sequence-based methods for capturing the temporal evolution of user activities, and content-based models for leveraging text and visual content. However, the development of a unifying framework that integrates these diverse techniques to support multiple applications remains a significant challenge. This paper presents OmniSage, a large-scale representation framework that learns universal representations for a variety of applications at Pinterest. OmniSage integrates graph neural networks with content-based models and user sequence models by employing multiple contrastive learning tasks to effectively process graph data, user sequence data, and content signals. To support the training and inference of OmniSage, we developed an efficient infrastructure capable of supporting Pinterest graphs with billions of nodes. The universal representations generated by OmniSage have significantly enhanced user experiences on Pinterest, leading to an approximate 2.5% increase in sitewide repins (saves) across five applications. This paper highlights the impact of unifying representation learning methods, and we will open source the OmniSage code by the time of publication.
PinRec: Outcome-Conditioned, Multi-Token Generative Retrieval for Industry-Scale Recommendation Systems
Apr 09, 2025Generative retrieval methods utilize generative sequential modeling techniques, such as transformers, to generate candidate items for recommender systems. These methods have demonstrated promising results in academic benchmarks, surpassing traditional retrieval models like two-tower architectures. However, current generative retrieval methods lack the scalability required for industrial recommender systems, and they are insufficiently flexible to satisfy the multiple metric requirements of modern systems. This paper introduces PinRec, a novel generative retrieval model developed for applications at Pinterest. PinRec utilizes outcome-conditioned generation, enabling modelers to specify how to balance various outcome metrics, such as the number of saves and clicks, to effectively align with business goals and user exploration. Additionally, PinRec incorporates multi-token generation to enhance output diversity while optimizing generation. Our experiments demonstrate that PinRec can successfully balance performance, diversity, and efficiency, delivering a significant positive impact to users using generative models. This paper marks a significant milestone in generative retrieval, as it presents, to our knowledge, the first rigorous study on implementing generative retrieval at the scale of Pinterest.
Rethinking Personalized Ranking at Pinterest: An End-to-End Approach
Sep 18, 2022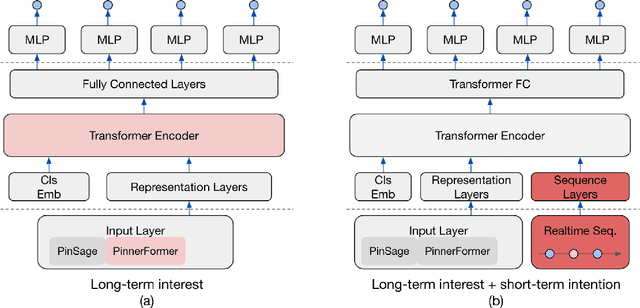
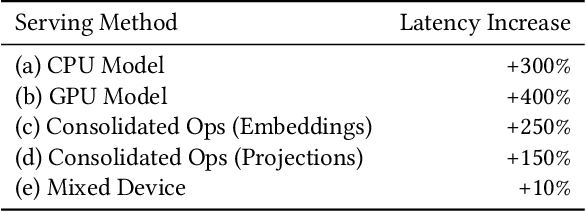
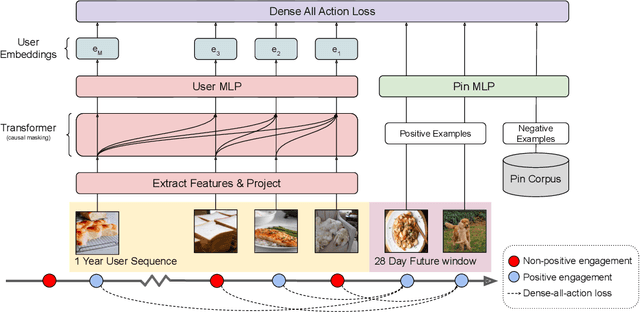

In this work, we present our journey to revolutionize the personalized recommendation engine through end-to-end learning from raw user actions. We encode user's long-term interest in Pinner- Former, a user embedding optimized for long-term future actions via a new dense all-action loss, and capture user's short-term intention by directly learning from the real-time action sequences. We conducted both offline and online experiments to validate the performance of the new model architecture, and also address the challenge of serving such a complex model using mixed CPU/GPU setup in production. The proposed system has been deployed in production at Pinterest and has delivered significant online gains across organic and Ads applications.
Modeling User Behavior With Interaction Networks for Spam Detection
Jul 21, 2022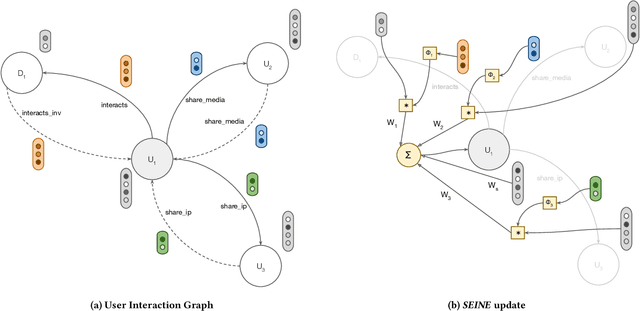
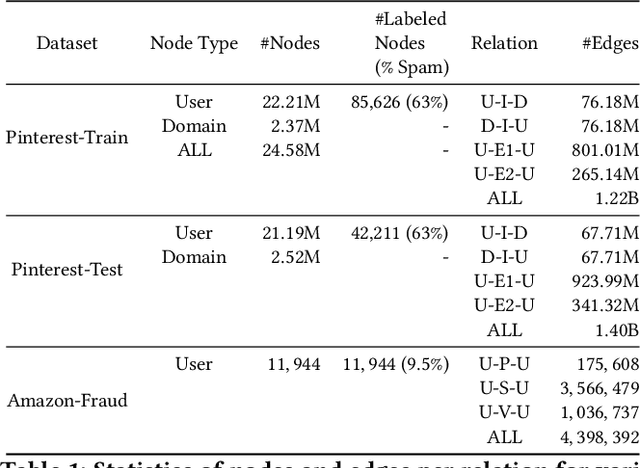
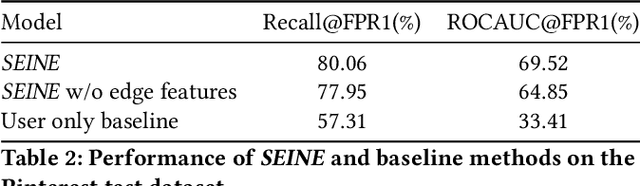
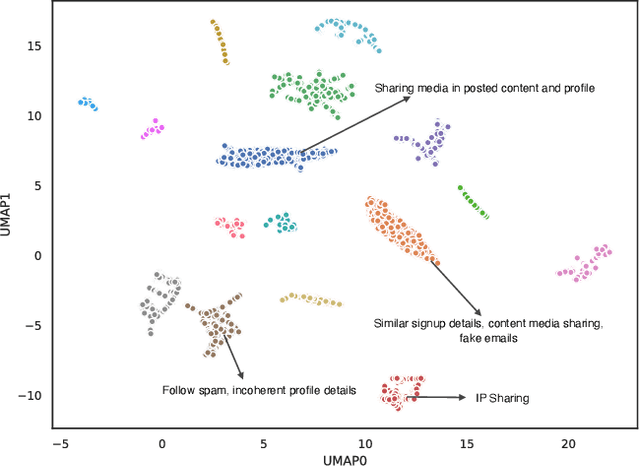
Spam is a serious problem plaguing web-scale digital platforms which facilitate user content creation and distribution. It compromises platform's integrity, performance of services like recommendation and search, and overall business. Spammers engage in a variety of abusive and evasive behavior which are distinct from non-spammers. Users' complex behavior can be well represented by a heterogeneous graph rich with node and edge attributes. Learning to identify spammers in such a graph for a web-scale platform is challenging because of its structural complexity and size. In this paper, we propose SEINE (Spam DEtection using Interaction NEtworks), a spam detection model over a novel graph framework. Our graph simultaneously captures rich users' details and behavior and enables learning on a billion-scale graph. Our model considers neighborhood along with edge types and attributes, allowing it to capture a wide range of spammers. SEINE, trained on a real dataset of tens of millions of nodes and billions of edges, achieves a high performance of 80% recall with 1% false positive rate. SEINE achieves comparable performance to the state-of-the-art techniques on a public dataset while being pragmatic to be used in a large-scale production system.
* 6 pages, 2 figures, accepted to SIGIR 2022
ItemSage: Learning Product Embeddings for Shopping Recommendations at Pinterest
May 24, 2022

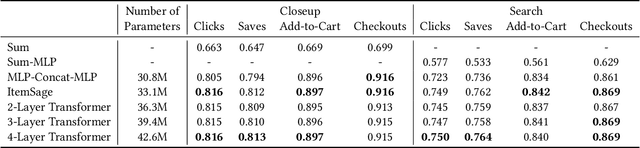
Learned embeddings for products are an important building block for web-scale e-commerce recommendation systems. At Pinterest, we build a single set of product embeddings called ItemSage to provide relevant recommendations in all shopping use cases including user, image and search based recommendations. This approach has led to significant improvements in engagement and conversion metrics, while reducing both infrastructure and maintenance cost. While most prior work focuses on building product embeddings from features coming from a single modality, we introduce a transformer-based architecture capable of aggregating information from both text and image modalities and show that it significantly outperforms single modality baselines. We also utilize multi-task learning to make ItemSage optimized for several engagement types, leading to a candidate generation system that is efficient for all of the engagement objectives of the end-to-end recommendation system. Extensive offline experiments are conducted to illustrate the effectiveness of our approach and results from online A/B experiments show substantial gains in key business metrics (up to +7% gross merchandise value/user and +11% click volume).
* 9 pages, 5 figures
MultiBiSage: A Web-Scale Recommendation System Using Multiple Bipartite Graphs at Pinterest
May 21, 2022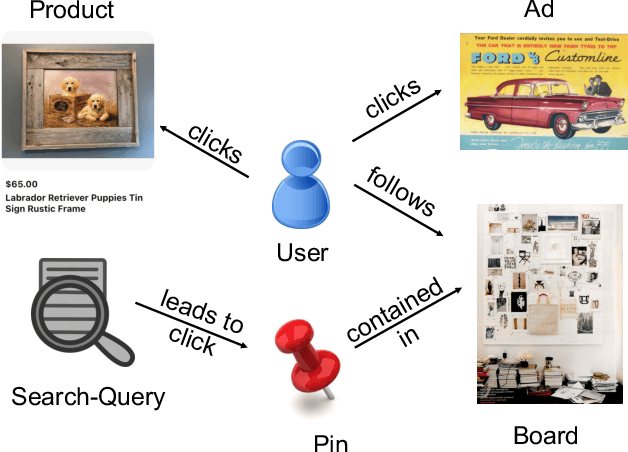

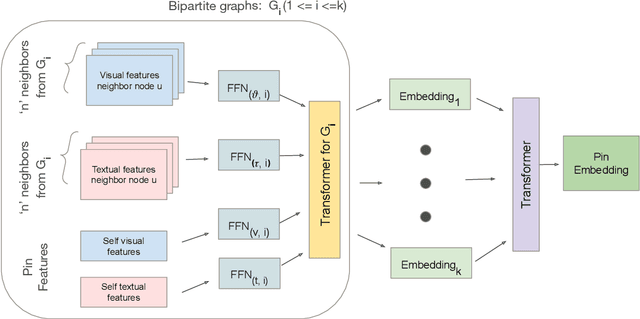
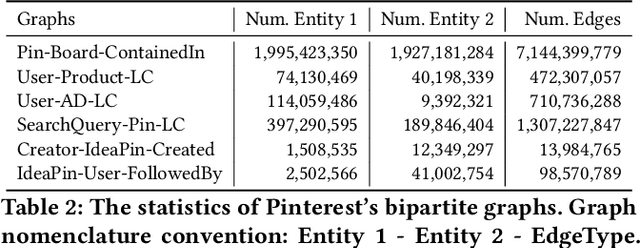
Graph Convolutional Networks (GCN) can efficiently integrate graph structure and node features to learn high-quality node embeddings. These embeddings can then be used for several tasks such as recommendation and search. At Pinterest, we have developed and deployed PinSage, a data-efficient GCN that learns pin embeddings from the Pin-Board graph. The Pin-Board graph contains pin and board entities and the graph captures the pin belongs to a board interaction. However, there exist several entities at Pinterest such as users, idea pins, creators, and there exist heterogeneous interactions among these entities such as add-to-cart, follow, long-click. In this work, we show that training deep learning models on graphs that captures these diverse interactions would result in learning higher-quality pin embeddings than training PinSage on only the Pin-Board graph. To that end, we model the diverse entities and their diverse interactions through multiple bipartite graphs and propose a novel data-efficient MultiBiSage model. MultiBiSage can capture the graph structure of multiple bipartite graphs to learn high-quality pin embeddings. We take this pragmatic approach as it allows us to utilize the existing infrastructure developed at Pinterest -- such as Pixie system that can perform optimized random-walks on billion node graphs, along with existing training and deployment workflows. We train MultiBiSage on six bipartite graphs including our Pin-Board graph. Our offline metrics show that MultiBiSage significantly outperforms the deployed latest version of PinSage on multiple user engagement metrics.
PinnerFormer: Sequence Modeling for User Representation at Pinterest
May 09, 2022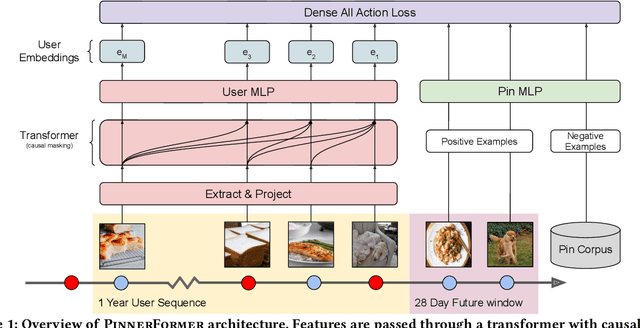
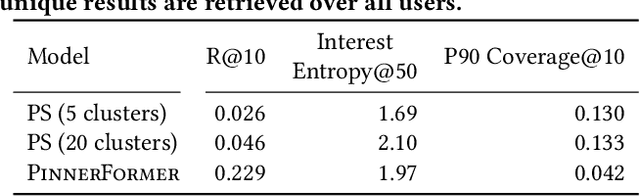
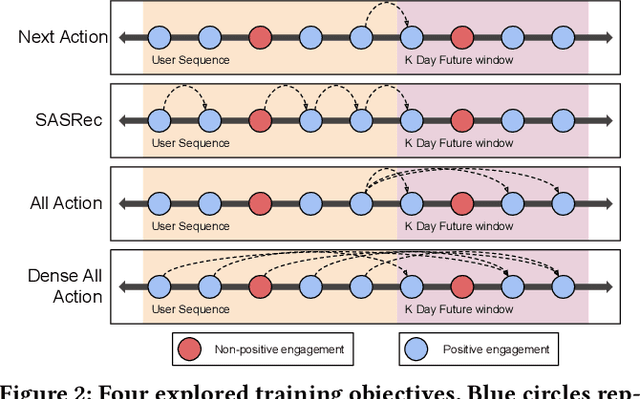
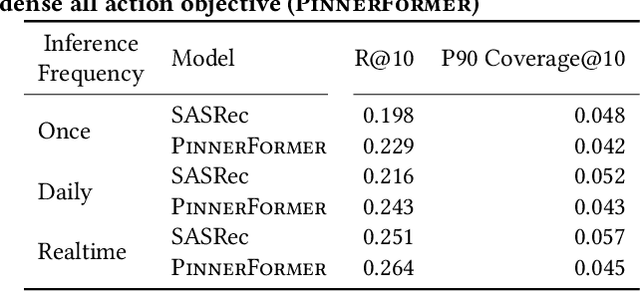
Sequential models have become increasingly popular in powering personalized recommendation systems over the past several years. These approaches traditionally model a user's actions on a website as a sequence to predict the user's next action. While theoretically simplistic, these models are quite challenging to deploy in production, commonly requiring streaming infrastructure to reflect the latest user activity and potentially managing mutable data for encoding a user's hidden state. Here we introduce PinnerFormer, a user representation trained to predict a user's future long-term engagement using a sequential model of a user's recent actions. Unlike prior approaches, we adapt our modeling to a batch infrastructure via our new dense all-action loss, modeling long-term future actions instead of next action prediction. We show that by doing so, we significantly close the gap between batch user embeddings that are generated once a day and realtime user embeddings generated whenever a user takes an action. We describe our design decisions via extensive offline experimentation and ablations and validate the efficacy of our approach in A/B experiments showing substantial improvements in Pinterest's user retention and engagement when comparing PinnerFormer against our previous user representation. PinnerFormer is deployed in production as of Fall 2021.
PinnerSage: Multi-Modal User Embedding Framework for Recommendations at Pinterest
Jul 07, 2020

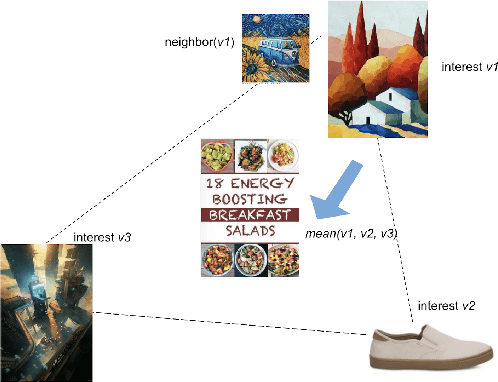

Latent user representations are widely adopted in the tech industry for powering personalized recommender systems. Most prior work infers a single high dimensional embedding to represent a user, which is a good starting point but falls short in delivering a full understanding of the user's interests. In this work, we introduce PinnerSage, an end-to-end recommender system that represents each user via multi-modal embeddings and leverages this rich representation of users to provides high quality personalized recommendations. PinnerSage achieves this by clustering users' actions into conceptually coherent clusters with the help of a hierarchical clustering method (Ward) and summarizes the clusters via representative pins (Medoids) for efficiency and interpretability. PinnerSage is deployed in production at Pinterest and we outline the several design decisions that makes it run seamlessly at a very large scale. We conduct several offline and online A/B experiments to show that our method significantly outperforms single embedding methods.
* 10 pages, 7 figures