 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling User Behavior With Interaction Networks for Spam Detection
Jul 21, 2022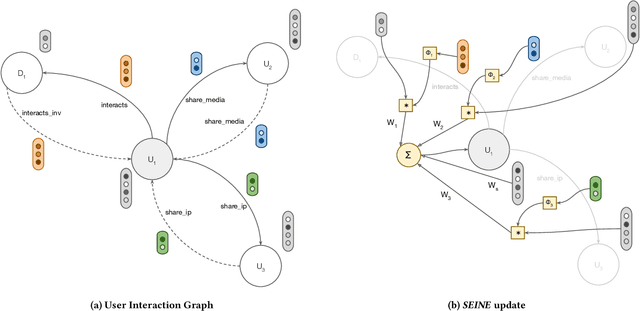
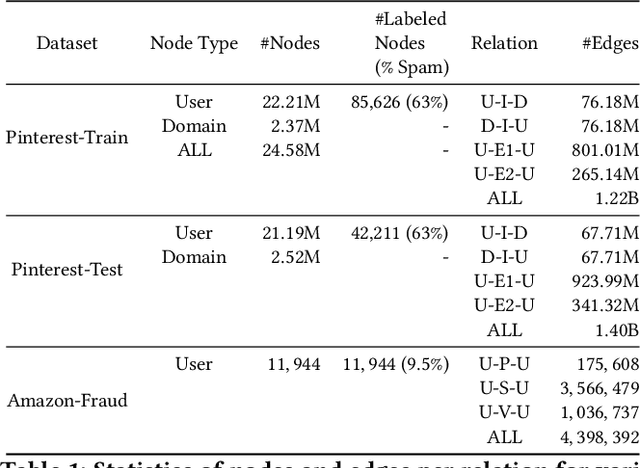
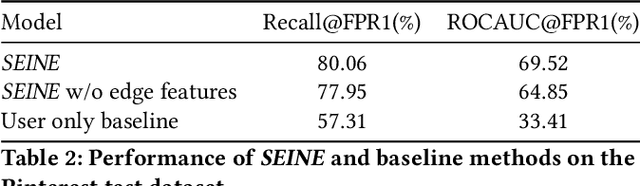
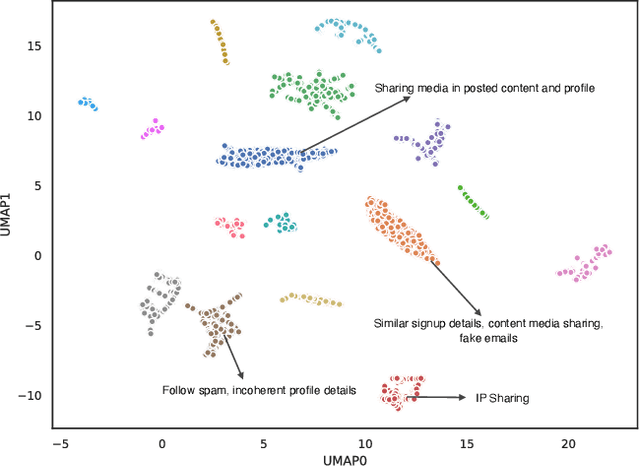
Spam is a serious problem plaguing web-scale digital platforms which facilitate user content creation and distribution. It compromises platform's integrity, performance of services like recommendation and search, and overall business. Spammers engage in a variety of abusive and evasive behavior which are distinct from non-spammers. Users' complex behavior can be well represented by a heterogeneous graph rich with node and edge attributes. Learning to identify spammers in such a graph for a web-scale platform is challenging because of its structural complexity and size. In this paper, we propose SEINE (Spam DEtection using Interaction NEtworks), a spam detection model over a novel graph framework. Our graph simultaneously captures rich users' details and behavior and enables learning on a billion-scale graph. Our model considers neighborhood along with edge types and attributes, allowing it to capture a wide range of spammers. SEINE, trained on a real dataset of tens of millions of nodes and billions of edges, achieves a high performance of 80% recall with 1% false positive rate. SEINE achieves comparable performance to the state-of-the-art techniques on a public dataset while being pragmatic to be used in a large-scale production system.
* 6 pages, 2 figures, accepted to SIGIR 2022
A multi-instance learning algorithm based on a stacked ensemble of lazy learners
Jul 10, 2014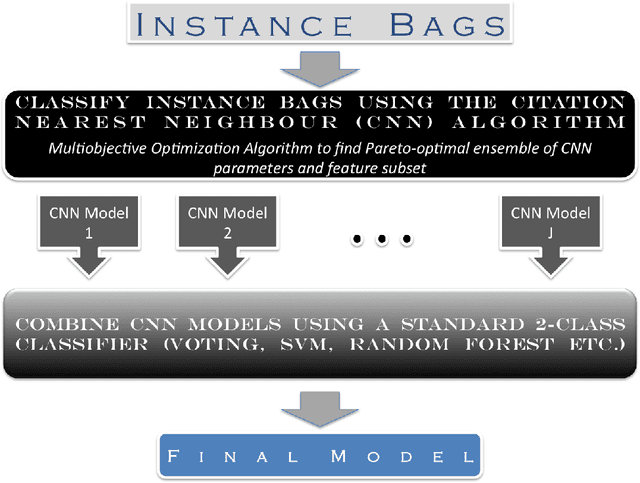


This document describes a novel learning algorithm that classifies "bags" of instances rather than individual instances. A bag is labeled positive if it contains at least one positive instance (which may or may not be specifically identified), and negative otherwise. This class of problems is known as multi-instance learning problems, and is useful in situations where the class label at an instance level may be unavailable or imprecise or difficult to obtain, or in situations where the problem is naturally posed as one of classifying instance groups. The algorithm described here is an ensemble-based method, wherein the members of the ensemble are lazy learning classifiers learnt using the Citation Nearest Neighbour method. Diversity among the ensemble members is achieved by optimizing their parameters using a multi-objective optimization method, with the objectives being to maximize Class 1 accuracy and minimize false positive rate. The method has been found to be effective on the Musk1 benchmark dataset.