 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPinRec: Unifying Generative Retrieval and Ranking at Pinterest Scale
May 29, 2026Modern recommendation systems predominantly train retrieval and ranking as separate models despite both increasingly relying on large transformers encoding the same user behavior data, duplicating parameters, compute, and serving cost. Prior work unifies the model architecture but not the full pipeline: input formats, training procedures, and serving stacks remain fragmented across stages. We present UniPinRec, which achieves full-stack unification of retrieval and ranking at Pinterest: one input format, one model, one training stage, deployed within existing serving infrastructure. A shared transformer encodes the user action sequence into candidate-independent representations that branch into retrieval (ANN dot-product) and ranking (cross-attention) via task-specific heads. Three ideas make this work: (1) Masked Action Modeling (MAM) eliminates interleaving, enabling weight sharing without doubling context length; (2) Blended training examples pair action sequences with feedview impression slates to satisfy both objectives jointly; (3) Cross-stage KV cache sharing reuses user-history computation from retrieval for ranking, reducing total FLOPs versus serving two independent models. Deployed in the Pinterest core surfaces, UniPinRec delivers approximately +1% online engagement lift while cutting end-to-end serving latency by 11.1% and lifting QPS by 63.6%. To our knowledge, this is the first full-stack unification of retrieval and ranking, covering inputs, model, training and serving, deployed in a production recommendation system.
OmniSage: Large Scale, Multi-Entity Heterogeneous Graph Representation Learning
May 01, 2025
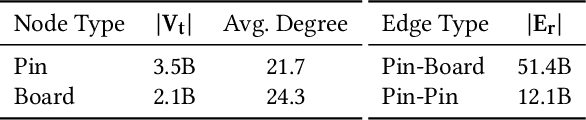
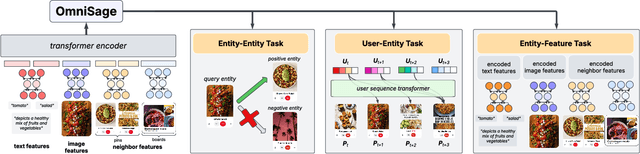

Representation learning, a task of learning latent vectors to represent entities, is a key task in improving search and recommender systems in web applications. Various representation learning methods have been developed, including graph-based approaches for relationships among entities, sequence-based methods for capturing the temporal evolution of user activities, and content-based models for leveraging text and visual content. However, the development of a unifying framework that integrates these diverse techniques to support multiple applications remains a significant challenge. This paper presents OmniSage, a large-scale representation framework that learns universal representations for a variety of applications at Pinterest. OmniSage integrates graph neural networks with content-based models and user sequence models by employing multiple contrastive learning tasks to effectively process graph data, user sequence data, and content signals. To support the training and inference of OmniSage, we developed an efficient infrastructure capable of supporting Pinterest graphs with billions of nodes. The universal representations generated by OmniSage have significantly enhanced user experiences on Pinterest, leading to an approximate 2.5% increase in sitewide repins (saves) across five applications. This paper highlights the impact of unifying representation learning methods, and we will open source the OmniSage code by the time of publication.
PinRec: Outcome-Conditioned, Multi-Token Generative Retrieval for Industry-Scale Recommendation Systems
Apr 09, 2025Generative retrieval methods utilize generative sequential modeling techniques, such as transformers, to generate candidate items for recommender systems. These methods have demonstrated promising results in academic benchmarks, surpassing traditional retrieval models like two-tower architectures. However, current generative retrieval methods lack the scalability required for industrial recommender systems, and they are insufficiently flexible to satisfy the multiple metric requirements of modern systems. This paper introduces PinRec, a novel generative retrieval model developed for applications at Pinterest. PinRec utilizes outcome-conditioned generation, enabling modelers to specify how to balance various outcome metrics, such as the number of saves and clicks, to effectively align with business goals and user exploration. Additionally, PinRec incorporates multi-token generation to enhance output diversity while optimizing generation. Our experiments demonstrate that PinRec can successfully balance performance, diversity, and efficiency, delivering a significant positive impact to users using generative models. This paper marks a significant milestone in generative retrieval, as it presents, to our knowledge, the first rigorous study on implementing generative retrieval at the scale of Pinterest.
InteractRank: Personalized Web-Scale Search Pre-Ranking with Cross Interaction Features
Apr 09, 2025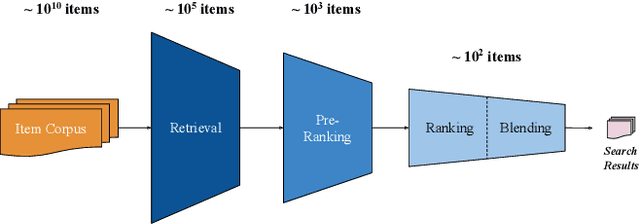

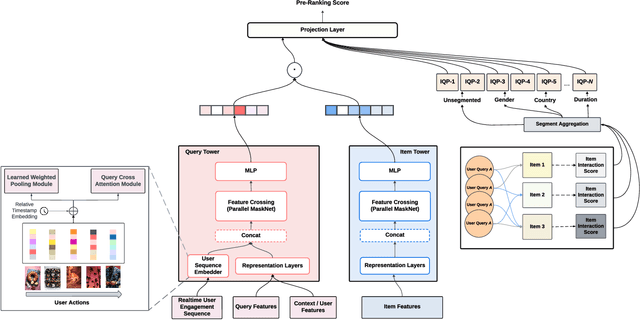
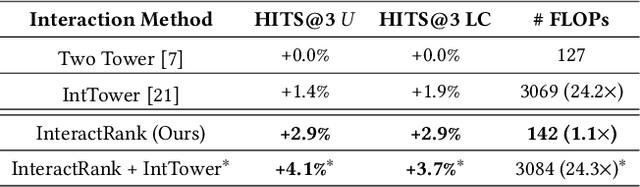
Modern search systems use a multi-stage architecture to deliver personalized results efficiently. Key stages include retrieval, pre-ranking, full ranking, and blending, which refine billions of items to top selections. The pre-ranking stage, vital for scoring and filtering hundreds of thousands of items down to a few thousand, typically relies on two tower models due to their computational efficiency, despite often lacking in capturing complex interactions. While query-item cross interaction features are paramount for full ranking, integrating them into pre-ranking models presents efficiency-related challenges. In this paper, we introduce InteractRank, a novel two tower pre-ranking model with robust cross interaction features used at Pinterest. By incorporating historical user engagement-based query-item interactions in the scoring function along with the two tower dot product, InteractRank significantly boosts pre-ranking performance with minimal latency and computation costs. In real-world A/B experiments at Pinterest, InteractRank improves the online engagement metric by 6.5% over a BM25 baseline and by 3.7% over a vanilla two tower baseline. We also highlight other components of InteractRank, like real-time user-sequence modeling, and analyze their contributions through offline ablation studies. The code for InteractRank is available at https://github.com/pinterest/atg-research/tree/main/InteractRank.
Hybrid Preference Optimization: Augmenting Direct Preference Optimization with Auxiliary Objectives
May 29, 2024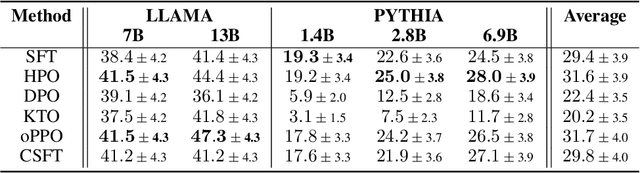
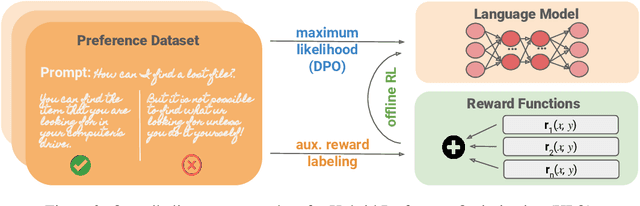

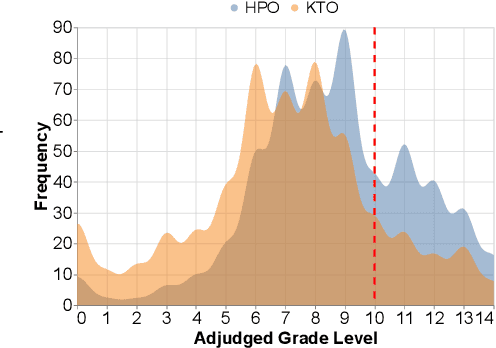
For aligning large language models (LLMs), prior work has leveraged reinforcement learning via human feedback (RLHF) or variations of direct preference optimization (DPO). While DPO offers a simpler framework based on maximum likelihood estimation, it compromises on the ability to tune language models to easily maximize non-differentiable and non-binary objectives according to the LLM designer's preferences (e.g., using simpler language or minimizing specific kinds of harmful content). These may neither align with user preferences nor even be able to be captured tractably by binary preference data. To leverage the simplicity and performance of DPO with the generalizability of RL, we propose a hybrid approach between DPO and RLHF. With a simple augmentation to the implicit reward decomposition of DPO, we allow for tuning LLMs to maximize a set of arbitrary auxiliary rewards using offline RL. The proposed method, Hybrid Preference Optimization (HPO), shows the ability to effectively generalize to both user preferences and auxiliary designer objectives, while preserving alignment performance across a range of challenging benchmarks and model sizes.
OmniSearchSage: Multi-Task Multi-Entity Embeddings for Pinterest Search
Apr 25, 2024



In this paper, we present OmniSearchSage, a versatile and scalable system for understanding search queries, pins, and products for Pinterest search. We jointly learn a unified query embedding coupled with pin and product embeddings, leading to an improvement of $>8\%$ relevance, $>7\%$ engagement, and $>5\%$ ads CTR in Pinterest's production search system. The main contributors to these gains are improved content understanding, better multi-task learning, and real-time serving. We enrich our entity representations using diverse text derived from image captions from a generative LLM, historical engagement, and user-curated boards. Our multitask learning setup produces a single search query embedding in the same space as pin and product embeddings and compatible with pre-existing pin and product embeddings. We show the value of each feature through ablation studies, and show the effectiveness of a unified model compared to standalone counterparts. Finally, we share how these embeddings have been deployed across the Pinterest search stack, from retrieval to ranking, scaling to serve $300k$ requests per second at low latency. Our implementation of this work is available at https://github.com/pinterest/atg-research/tree/main/omnisearchsage.
Exploring intra-task relations to improve meta-learning algorithms
Dec 27, 2023Meta-learning has emerged as an effective methodology to model several real-world tasks and problems due to its extraordinary effectiveness in the low-data regime. There are many scenarios ranging from the classification of rare diseases to language modelling of uncommon languages where the availability of large datasets is rare. Similarly, for more broader scenarios like self-driving, an autonomous vehicle needs to be trained to handle every situation well. This requires training the ML model on a variety of tasks with good quality data. But often times, we find that the data distribution across various tasks is skewed, i.e.the data follows a long-tail distribution. This leads to the model performing well on some tasks and not performing so well on others leading to model robustness issues. Meta-learning has recently emerged as a potential learning paradigm which can effectively learn from one task and generalize that learning to unseen tasks. In this study, we aim to exploit external knowledge of task relations to improve training stability via effective mini-batching of tasks. We hypothesize that selecting a diverse set of tasks in a mini-batch will lead to a better estimate of the full gradient and hence will lead to a reduction of noise in training.
Detecting anxiety from short clips of free-form speech
Dec 23, 2023



Barriers to accessing mental health assessments including cost and stigma continues to be an impediment in mental health diagnosis and treatment. Machine learning approaches based on speech samples could help in this direction. In this work, we develop machine learning solutions to diagnose anxiety disorders from audio journals of patients. We work on a novel anxiety dataset (provided through collaboration with Kintsugi Mindful Wellness Inc.) and experiment with several models of varying complexity utilizing audio, text and a combination of multiple modalities. We show that the multi-modal and audio embeddings based approaches achieve good performance in the task achieving an AUC ROC score of 0.68-0.69.
Exploring Graph Based Approaches for Author Name Disambiguation
Dec 12, 2023In many applications, such as scientific literature management, researcher search, social network analysis and etc, Name Disambiguation (aiming at disambiguating WhoIsWho) has been a challenging problem. In addition, the growth of scientific literature makes the problem more difficult and urgent. Although name disambiguation has been extensively studied in academia and industry, the problem has not been solved well due to the clutter of data and the complexity of the same name scenario. In this work, we aim to explore models that can perform the task of name disambiguation using the network structure that is intrinsic to the problem and present an analysis of the models.
Modeling User Behavior With Interaction Networks for Spam Detection
Jul 21, 2022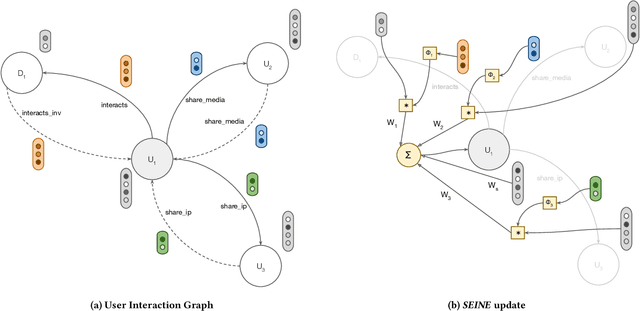
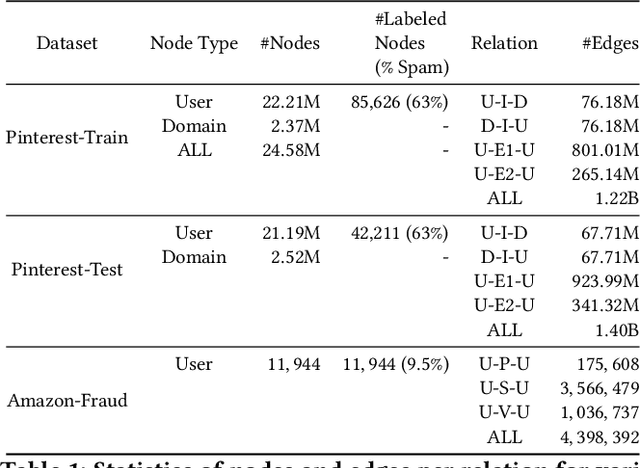
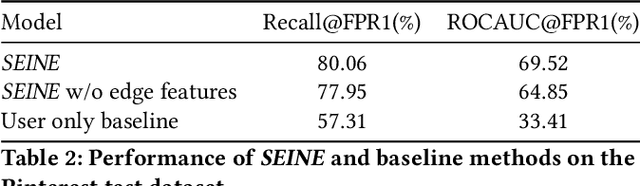
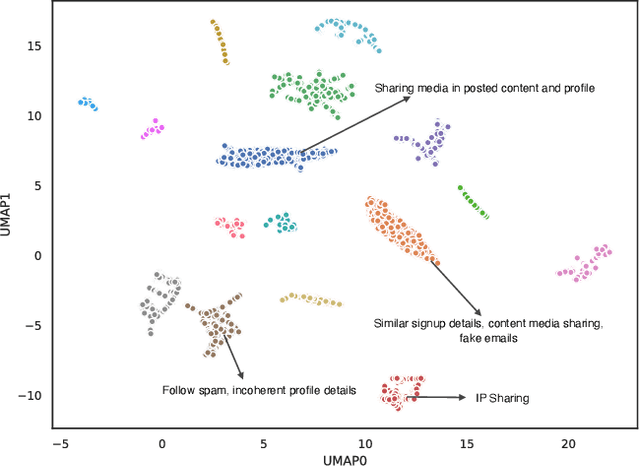
Spam is a serious problem plaguing web-scale digital platforms which facilitate user content creation and distribution. It compromises platform's integrity, performance of services like recommendation and search, and overall business. Spammers engage in a variety of abusive and evasive behavior which are distinct from non-spammers. Users' complex behavior can be well represented by a heterogeneous graph rich with node and edge attributes. Learning to identify spammers in such a graph for a web-scale platform is challenging because of its structural complexity and size. In this paper, we propose SEINE (Spam DEtection using Interaction NEtworks), a spam detection model over a novel graph framework. Our graph simultaneously captures rich users' details and behavior and enables learning on a billion-scale graph. Our model considers neighborhood along with edge types and attributes, allowing it to capture a wide range of spammers. SEINE, trained on a real dataset of tens of millions of nodes and billions of edges, achieves a high performance of 80% recall with 1% false positive rate. SEINE achieves comparable performance to the state-of-the-art techniques on a public dataset while being pragmatic to be used in a large-scale production system.
* 6 pages, 2 figures, accepted to SIGIR 2022