 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractRank: Personalized Web-Scale Search Pre-Ranking with Cross Interaction Features
Apr 09, 2025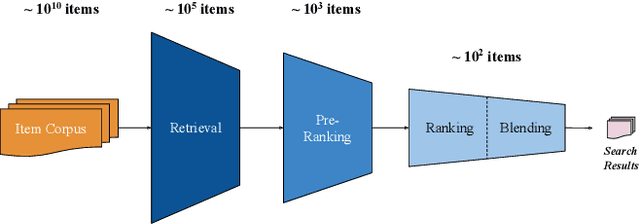

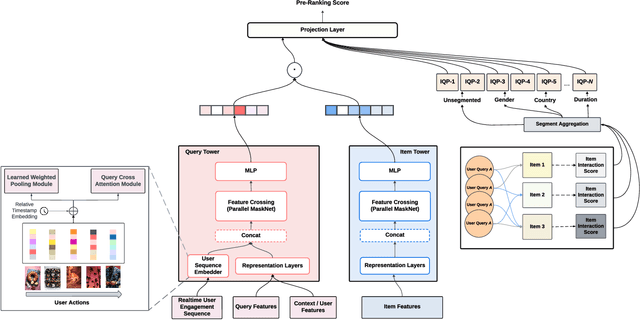
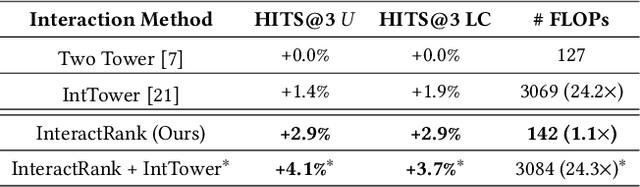
Modern search systems use a multi-stage architecture to deliver personalized results efficiently. Key stages include retrieval, pre-ranking, full ranking, and blending, which refine billions of items to top selections. The pre-ranking stage, vital for scoring and filtering hundreds of thousands of items down to a few thousand, typically relies on two tower models due to their computational efficiency, despite often lacking in capturing complex interactions. While query-item cross interaction features are paramount for full ranking, integrating them into pre-ranking models presents efficiency-related challenges. In this paper, we introduce InteractRank, a novel two tower pre-ranking model with robust cross interaction features used at Pinterest. By incorporating historical user engagement-based query-item interactions in the scoring function along with the two tower dot product, InteractRank significantly boosts pre-ranking performance with minimal latency and computation costs. In real-world A/B experiments at Pinterest, InteractRank improves the online engagement metric by 6.5% over a BM25 baseline and by 3.7% over a vanilla two tower baseline. We also highlight other components of InteractRank, like real-time user-sequence modeling, and analyze their contributions through offline ablation studies. The code for InteractRank is available at https://github.com/pinterest/atg-research/tree/main/InteractRank.
When Do Neural Nets Outperform Boosted Trees on Tabular Data?
May 04, 2023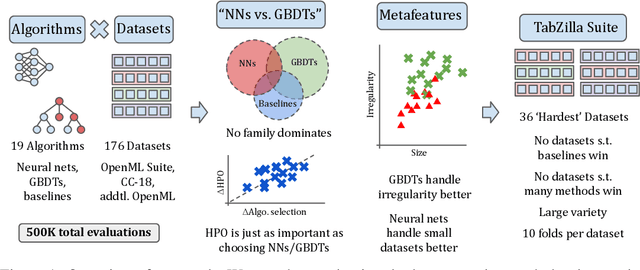



Tabular data is one of the most commonly used types of data in machine learning. Despite recent advances in neural nets (NNs) for tabular data, there is still an active discussion on whether or not NNs generally outperform gradient-boosted decision trees (GBDTs) on tabular data, with several recent works arguing either that GBDTs consistently outperform NNs on tabular data, or vice versa. In this work, we take a step back and ask, 'does it matter?' We conduct the largest tabular data analysis to date, by comparing 19 algorithms across 176 datasets, and we find that the 'NN vs. GBDT' debate is overemphasized: for a surprisingly high number of datasets, either the performance difference between GBDTs and NNs is negligible, or light hyperparameter tuning on a GBDT is more important than selecting the best algorithm. Next, we analyze 965 metafeatures to determine what properties of a dataset make NNs or GBDTs better-suited to perform well. For example, we find that GBDTs are much better than NNs at handling skewed feature distributions, heavy-tailed feature distributions, and other forms of dataset irregularities. Our insights act as a guide for practitioners to decide whether or not they need to run a neural net to reach top performance on their dataset. Our codebase and all raw results are available at https://github.com/naszilla/tabzilla.
On the Generalizability and Predictability of Recommender Systems
Jun 23, 2022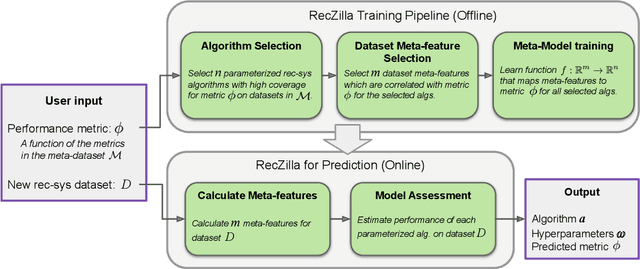
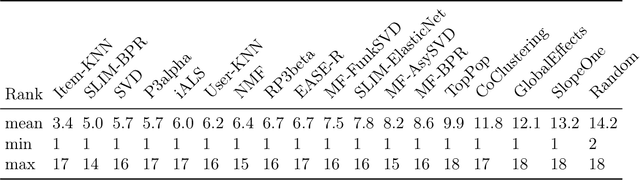
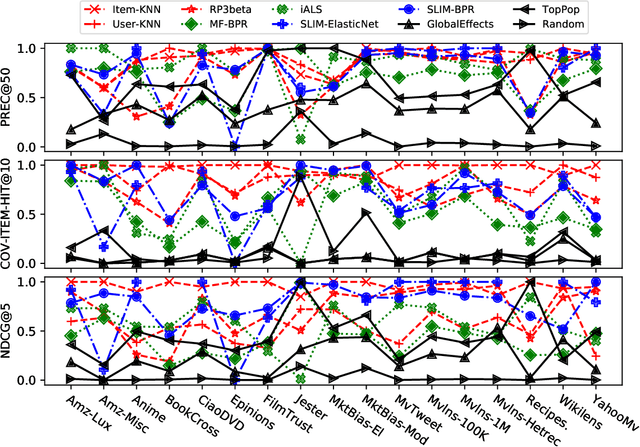

While other areas of machine learning have seen more and more automation, designing a high-performing recommender system still requires a high level of human effort. Furthermore, recent work has shown that modern recommender system algorithms do not always improve over well-tuned baselines. A natural follow-up question is, "how do we choose the right algorithm for a new dataset and performance metric?" In this work, we start by giving the first large-scale study of recommender system approaches by comparing 18 algorithms and 100 sets of hyperparameters across 85 datasets and 315 metrics. We find that the best algorithms and hyperparameters are highly dependent on the dataset and performance metric, however, there are also strong correlations between the performance of each algorithm and various meta-features of the datasets. Motivated by these findings, we create RecZilla, a meta-learning approach to recommender systems that uses a model to predict the best algorithm and hyperparameters for new, unseen datasets. By using far more meta-training data than prior work, RecZilla is able to substantially reduce the level of human involvement when faced with a new recommender system application. We not only release our code and pretrained RecZilla models, but also all of our raw experimental results, so that practitioners can train a RecZilla model for their desired performance metric: https://github.com/naszilla/reczilla.
Synthetic Benchmarks for Scientific Research in Explainable Machine Learning
Jun 23, 2021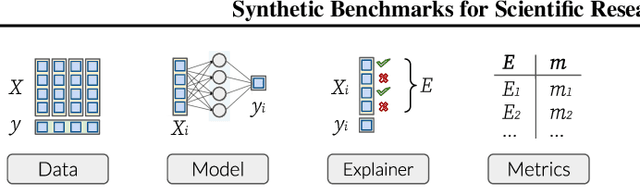
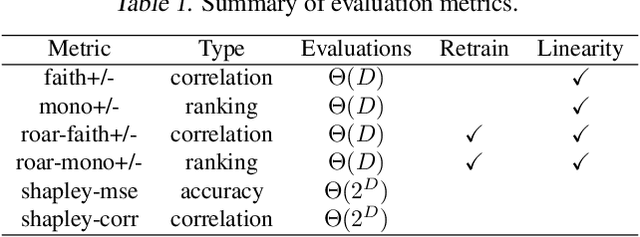
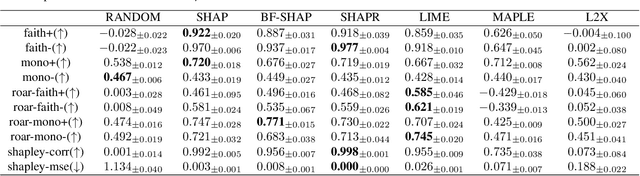
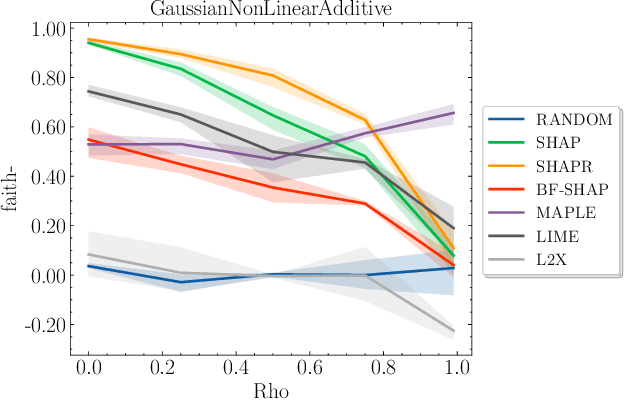
As machine learning models grow more complex and their applications become more high-stakes, tools for explaining model predictions have become increasingly important. Despite the widespread use of explainability techniques, evaluating and comparing different feature attribution methods remains challenging: evaluations ideally require human studies, and empirical evaluation metrics are often computationally prohibitive on real-world datasets. In this work, we address this issue by releasing XAI-Bench: a suite of synthetic datasets along with a library for benchmarking feature attribution algorithms. Unlike real-world datasets, synthetic datasets allow the efficient computation of conditional expected values that are needed to evaluate ground-truth Shapley values and other metrics. The synthetic datasets we release offer a wide variety of parameters that can be configured to simulate real-world data. We demonstrate the power of our library by benchmarking popular explainability techniques across several evaluation metrics and identifying failure modes for popular explainers. The efficiency of our library will help bring new explainability methods from development to deployment.
Bonsai - Diverse and Shallow Trees for Extreme Multi-label Classification
Apr 17, 2019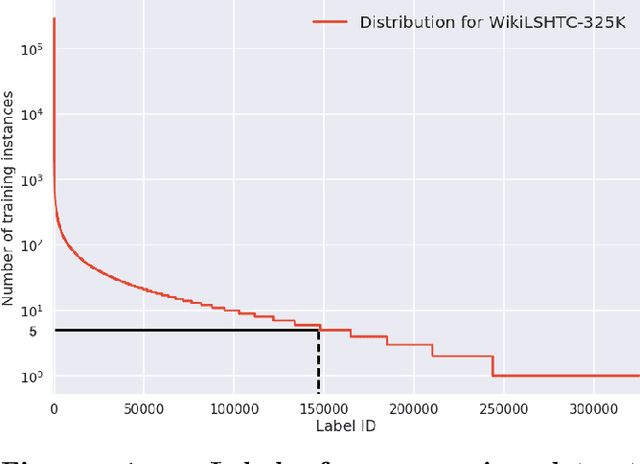

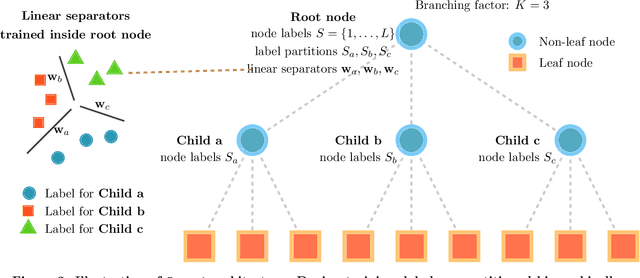

Extreme multi-label classification refers to supervised multi-label learning involving hundreds of thousand or even millions of labels. In this paper, we develop a shallow tree-based algorithm, called Bonsai, which promotes diversity of the label space and easily scales to millions of labels. Bonsai relaxes the two main constraints of the recently proposed tree-based algorithm, Parabel, which partitions labels at each tree node into exactly two child nodes, and imposes label balanced-ness between these nodes. Instead, Bonsai encourages diversity in the partitioning process by (i) allowing a much larger fan-out at each node, and (ii) maintaining the diversity of the label set further by enabling potentially imbalanced partitioning. By allowing such flexibility, it achieves the best of both worlds - fast training of tree-based methods, and prediction accuracy better than Parabel, and at par with one-vs-rest methods. As a result, Bonsai outperforms state-of-the-art one-vs-rest methods such as DiSMEC in terms of prediction accuracy, while being orders of magnitude faster to train. The code for \bonsai is available at https://github.com/xmc-aalto/bonsai.