 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabels in Extremes: How Well Calibrated are Extreme Multi-label Classifiers?
Nov 06, 2024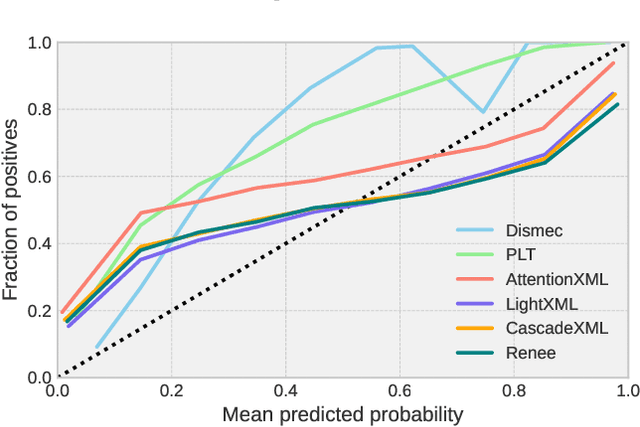


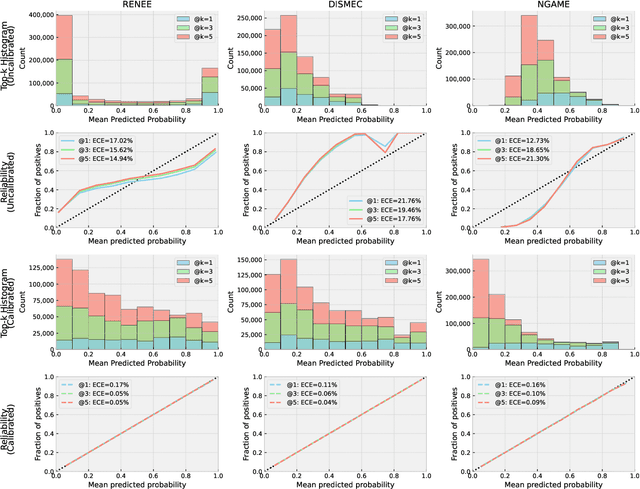
Extreme multilabel classification (XMLC) problems occur in settings such as related product recommendation, large-scale document tagging, or ad prediction, and are characterized by a label space that can span millions of possible labels. There are two implicit tasks that the classifier performs: \emph{Evaluating} each potential label for its expected worth, and then \emph{selecting} the best candidates. For the latter task, only the relative order of scores matters, and this is what is captured by the standard evaluation procedure in the XMLC literature. However, in many practical applications, it is important to have a good estimate of the actual probability of a label being relevant, e.g., to decide whether to pay the fee to be allowed to display the corresponding ad. To judge whether an extreme classifier is indeed suited to this task, one can look, for example, to whether it returns \emph{calibrated} probabilities, which has hitherto not been done in this field. Therefore, this paper aims to establish the current status quo of calibration in XMLC by providing a systematic evaluation, comprising nine models from four different model families across seven benchmark datasets. As naive application of Expected Calibration Error (ECE) leads to meaningless results in long-tailed XMC datasets, we instead introduce the notion of \emph{calibration@k} (e.g., ECE@k), which focusses on the top-$k$ probability mass, offering a more appropriate measure for evaluating probability calibration in XMLC scenarios. While we find that different models can exhibit widely varying reliability plots, we also show that post-training calibration via a computationally efficient isotonic regression method enhances model calibration without sacrificing prediction accuracy. Thus, the practitioner can choose the model family based on accuracy considerations, and leave calibration to isotonic regression.
Navigating Extremes: Dynamic Sparsity in Large Output Space
Nov 05, 2024In recent years, Dynamic Sparse Training (DST) has emerged as an alternative to post-training pruning for generating efficient models. In principle, DST allows for a more memory efficient training process, as it maintains sparsity throughout the entire training run. However, current DST implementations fail to capitalize on this in practice. Because sparse matrix multiplication is much less efficient than dense matrix multiplication on GPUs, most implementations simulate sparsity by masking weights. In this paper, we leverage recent advances in semi-structured sparse training to apply DST in the domain of classification with large output spaces, where memory-efficiency is paramount. With a label space of possibly millions of candidates, the classification layer alone will consume several gigabytes of memory. Switching from a dense to a fixed fan-in sparse layer updated with sparse evolutionary training (SET); however, severely hampers training convergence, especially at the largest label spaces. We find that poor gradient flow from the sparse classifier to the dense text encoder make it difficult to learn good input representations. By employing an intermediate layer or adding an auxiliary training objective, we recover most of the generalisation performance of the dense model. Overall, we demonstrate the applicability and practical benefits of DST in a challenging domain -- characterized by a highly skewed label distribution that differs substantially from typical DST benchmark datasets -- which enables end-to-end training with millions of labels on commodity hardware.
A General Online Algorithm for Optimizing Complex Performance Metrics
Jun 20, 2024



We consider sequential maximization of performance metrics that are general functions of a confusion matrix of a classifier (such as precision, F-measure, or G-mean). Such metrics are, in general, non-decomposable over individual instances, making their optimization very challenging. While they have been extensively studied under different frameworks in the batch setting, their analysis in the online learning regime is very limited, with only a few distinguished exceptions. In this paper, we introduce and analyze a general online algorithm that can be used in a straightforward way with a variety of complex performance metrics in binary, multi-class, and multi-label classification problems. The algorithm's update and prediction rules are appealingly simple and computationally efficient without the need to store any past data. We show the algorithm attains $\mathcal{O}(\frac{\ln n}{n})$ regret for concave and smooth metrics and verify the efficiency of the proposed algorithm in empirical studies.
Zero-Shot Learning Over Large Output Spaces : Utilizing Indirect Knowledge Extraction from Large Language Models
Jun 13, 2024Extreme Multi-label Learning (XMC) is a task that allocates the most relevant labels for an instance from a predefined label set. Extreme Zero-shot XMC (EZ-XMC) is a special setting of XMC wherein no supervision is provided; only the instances (raw text of the document) and the predetermined label set are given. The scenario is designed to address cold-start problems in categorization and recommendation. Traditional state-of-the-art methods extract pseudo labels from the document title or segments. These labels from the document are used to train a zero-shot bi-encoder model. The main issue with these generated labels is their misalignment with the tagging task. In this work, we propose a framework to train a small bi-encoder model via the feedback from the large language model (LLM), the bi-encoder model encodes the document and labels into embeddings for retrieval. Our approach leverages the zero-shot ability of LLM to assess the correlation between labels and the document instead of using the low-quality labels extracted from the document itself. Our method also guarantees fast inference without the involvement of LLM. The performance of our approach outperforms the SOTA methods on various datasets while retaining a similar training time for large datasets.
UniDEC : Unified Dual Encoder and Classifier Training for Extreme Multi-Label Classification
May 04, 2024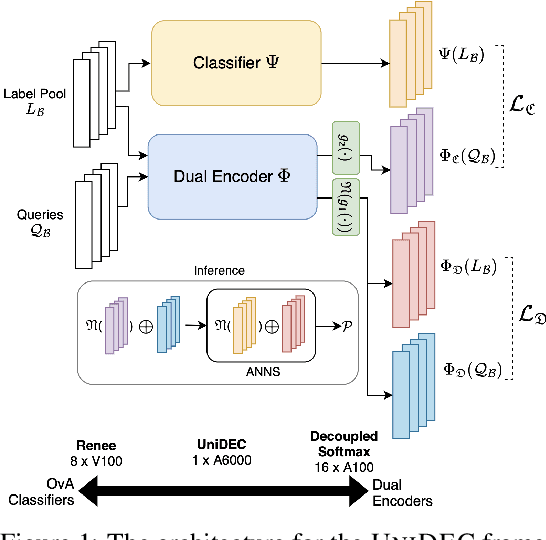
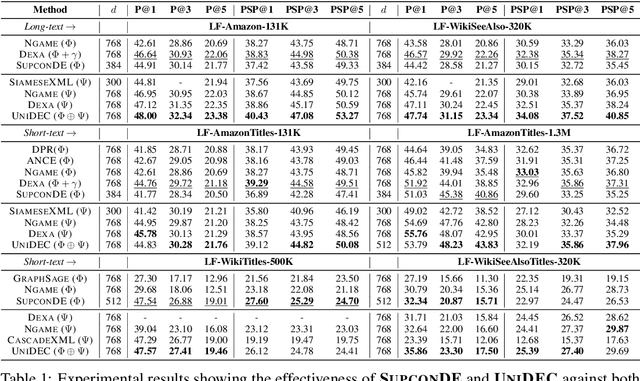
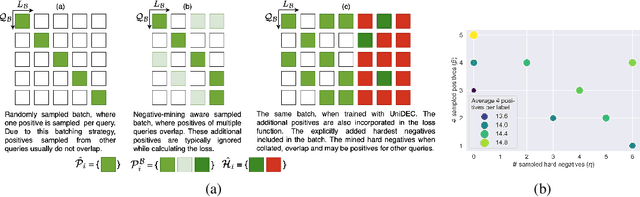
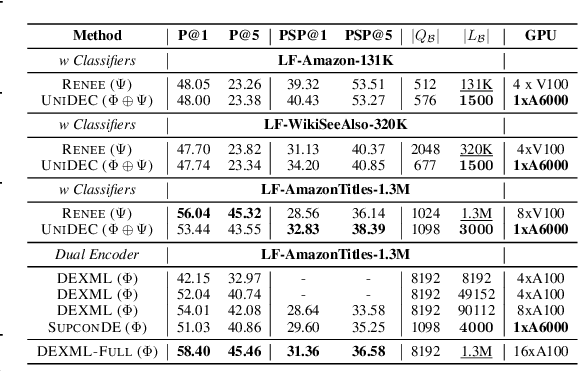
Extreme Multi-label Classification (XMC) involves predicting a subset of relevant labels from an extremely large label space, given an input query and labels with textual features. Models developed for this problem have conventionally used modular approach with (i) a Dual Encoder (DE) to embed the queries and label texts, (ii) a One-vs-All classifier to rerank the shortlisted labels mined through meta-classifier training. While such methods have shown empirical success, we observe two key uncharted aspects, (i) DE training typically uses only a single positive relation even for datasets which offer more, (ii) existing approaches fixate on using only OvA reduction of the multi-label problem. This work aims to explore these aspects by proposing UniDEC, a novel end-to-end trainable framework which trains the dual encoder and classifier in together in a unified fashion using a multi-class loss. For the choice of multi-class loss, the work proposes a novel pick-some-label (PSL) reduction of the multi-label problem with leverages multiple (in come cases, all) positives. The proposed framework achieves state-of-the-art results on a single GPU, while achieving on par results with respect to multi-GPU SOTA methods on various XML benchmark datasets, all while using 4-16x lesser compute and being practically scalable even beyond million label scale datasets.
Learning label-label correlations in Extreme Multi-label Classification via Label Features
May 03, 2024
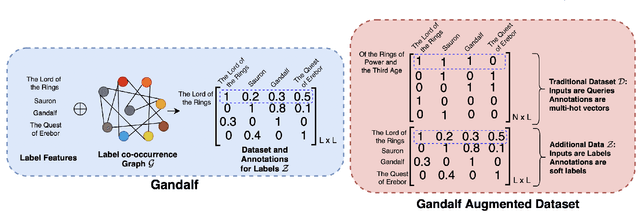
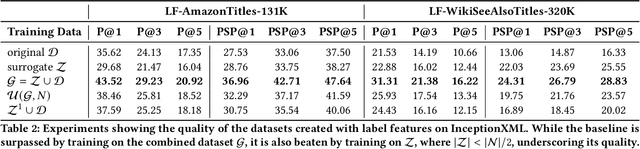
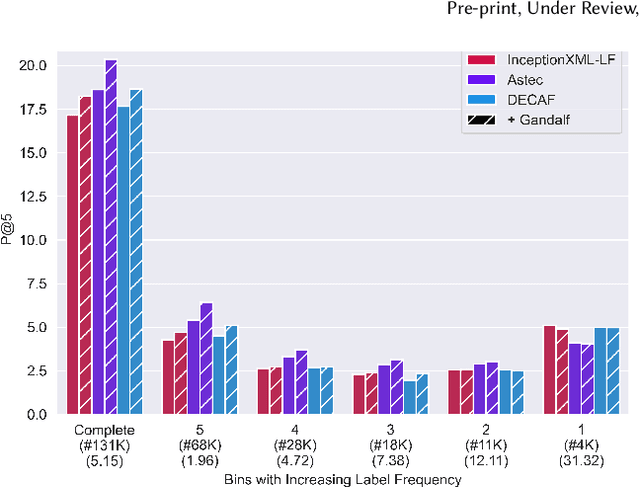
Extreme Multi-label Text Classification (XMC) involves learning a classifier that can assign an input with a subset of most relevant labels from millions of label choices. Recent works in this domain have increasingly focused on a symmetric problem setting where both input instances and label features are short-text in nature. Short-text XMC with label features has found numerous applications in areas such as query-to-ad-phrase matching in search ads, title-based product recommendation, prediction of related searches. In this paper, we propose Gandalf, a novel approach which makes use of a label co-occurrence graph to leverage label features as additional data points to supplement the training distribution. By exploiting the characteristics of the short-text XMC problem, it leverages the label features to construct valid training instances, and uses the label graph for generating the corresponding soft-label targets, hence effectively capturing the label-label correlations. Surprisingly, models trained on these new training instances, although being less than half of the original dataset, can outperform models trained on the original dataset, particularly on the PSP@k metric for tail labels. With this insight, we aim to train existing XMC algorithms on both, the original and new training instances, leading to an average 5% relative improvements for 6 state-of-the-art algorithms across 4 benchmark datasets consisting of up to 1.3M labels. Gandalf can be applied in a plug-and-play manner to various methods and thus forwards the state-of-the-art in the domain, without incurring any additional computational overheads.
Consistent algorithms for multi-label classification with macro-at-$k$ metrics
Jan 29, 2024We consider the optimization of complex performance metrics in multi-label classification under the population utility framework. We mainly focus on metrics linearly decomposable into a sum of binary classification utilities applied separately to each label with an additional requirement of exactly $k$ labels predicted for each instance. These "macro-at-$k$" metrics possess desired properties for extreme classification problems with long tail labels. Unfortunately, the at-$k$ constraint couples the otherwise independent binary classification tasks, leading to a much more challenging optimization problem than standard macro-averages. We provide a statistical framework to study this problem, prove the existence and the form of the optimal classifier, and propose a statistically consistent and practical learning algorithm based on the Frank-Wolfe method. Interestingly, our main results concern even more general metrics being non-linear functions of label-wise confusion matrices. Empirical results provide evidence for the competitive performance of the proposed approach.
Generalized test utilities for long-tail performance in extreme multi-label classification
Nov 09, 2023Extreme multi-label classification (XMLC) is the task of selecting a small subset of relevant labels from a very large set of possible labels. As such, it is characterized by long-tail labels, i.e., most labels have very few positive instances. With standard performance measures such as precision@k, a classifier can ignore tail labels and still report good performance. However, it is often argued that correct predictions in the tail are more interesting or rewarding, but the community has not yet settled on a metric capturing this intuitive concept. The existing propensity-scored metrics fall short on this goal by confounding the problems of long-tail and missing labels. In this paper, we analyze generalized metrics budgeted "at k" as an alternative solution. To tackle the challenging problem of optimizing these metrics, we formulate it in the expected test utility (ETU) framework, which aims at optimizing the expected performance on a fixed test set. We derive optimal prediction rules and construct computationally efficient approximations with provable regret guarantees and robustness against model misspecification. Our algorithm, based on block coordinate ascent, scales effortlessly to XMLC problems and obtains promising results in terms of long-tail performance.
Towards Memory-Efficient Training for Extremely Large Output Spaces -- Learning with 500k Labels on a Single Commodity GPU
Jun 06, 2023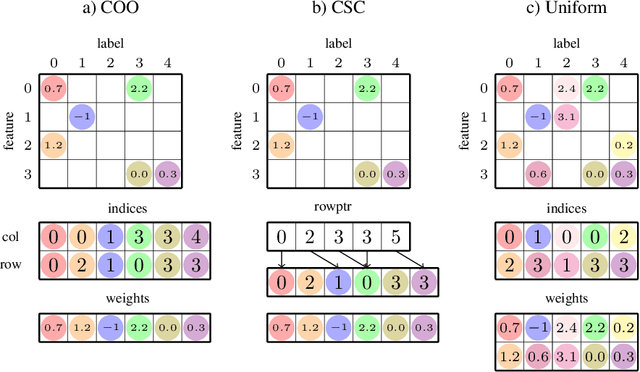
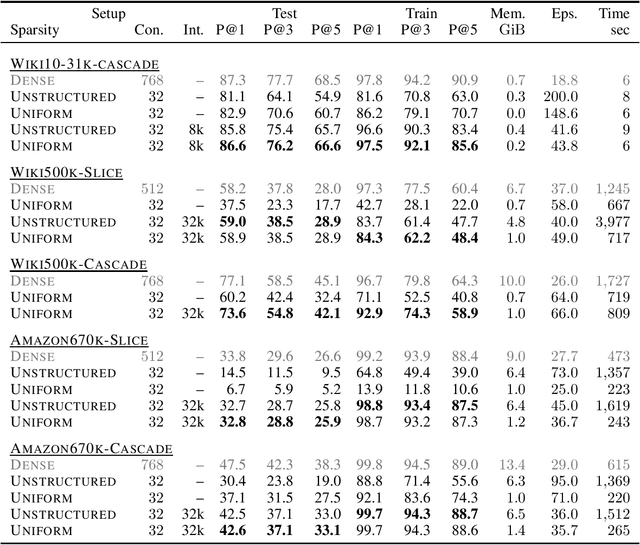
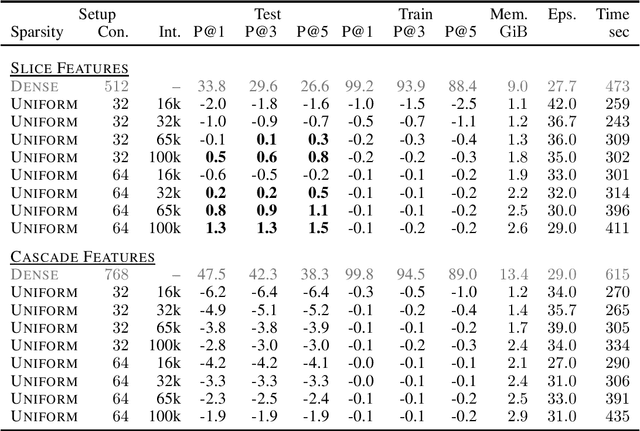
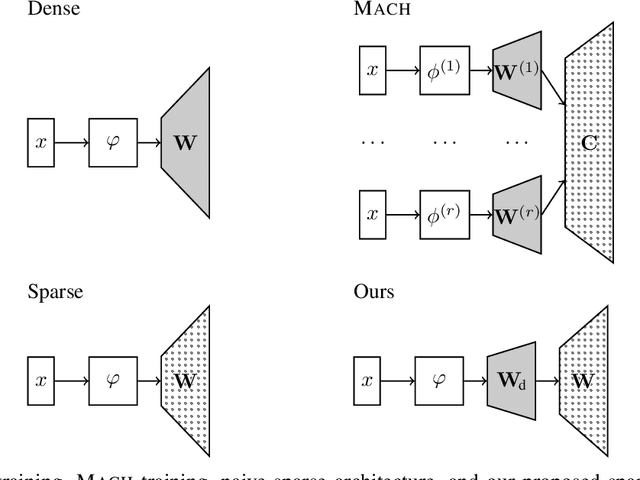
In classification problems with large output spaces (up to millions of labels), the last layer can require an enormous amount of memory. Using sparse connectivity would drastically reduce the memory requirements, but as we show below, it can result in much diminished predictive performance of the model. Fortunately, we found that this can be mitigated by introducing a penultimate layer of intermediate size. We further demonstrate that one can constrain the connectivity of the sparse layer to be uniform, in the sense that each output neuron will have the exact same number of incoming connections. This allows for efficient implementations of sparse matrix multiplication and connection redistribution on GPU hardware. Via a custom CUDA implementation, we show that the proposed approach can scale to datasets with 670,000 labels on a single commodity GPU with only 4GB memory.
CascadeXML: Rethinking Transformers for End-to-end Multi-resolution Training in Extreme Multi-label Classification
Oct 29, 2022Extreme Multi-label Text Classification (XMC) involves learning a classifier that can assign an input with a subset of most relevant labels from millions of label choices. Recent approaches, such as XR-Transformer and LightXML, leverage a transformer instance to achieve state-of-the-art performance. However, in this process, these approaches need to make various trade-offs between performance and computational requirements. A major shortcoming, as compared to the Bi-LSTM based AttentionXML, is that they fail to keep separate feature representations for each resolution in a label tree. We thus propose CascadeXML, an end-to-end multi-resolution learning pipeline, which can harness the multi-layered architecture of a transformer model for attending to different label resolutions with separate feature representations. CascadeXML significantly outperforms all existing approaches with non-trivial gains obtained on benchmark datasets consisting of up to three million labels. Code for CascadeXML will be made publicly available at \url{https://github.com/xmc-aalto/cascadexml}.