 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabels in Extremes: How Well Calibrated are Extreme Multi-label Classifiers?
Paper and Code
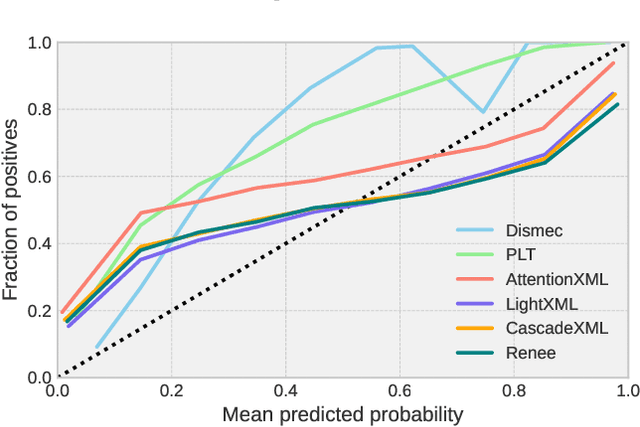


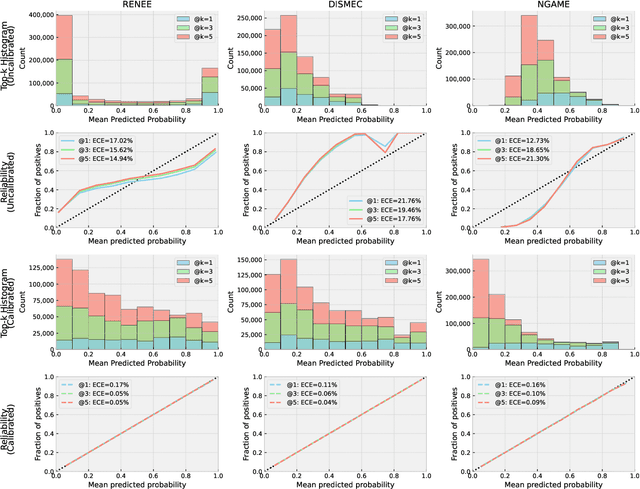
Extreme multilabel classification (XMLC) problems occur in settings such as related product recommendation, large-scale document tagging, or ad prediction, and are characterized by a label space that can span millions of possible labels. There are two implicit tasks that the classifier performs: \emph{Evaluating} each potential label for its expected worth, and then \emph{selecting} the best candidates. For the latter task, only the relative order of scores matters, and this is what is captured by the standard evaluation procedure in the XMLC literature. However, in many practical applications, it is important to have a good estimate of the actual probability of a label being relevant, e.g., to decide whether to pay the fee to be allowed to display the corresponding ad. To judge whether an extreme classifier is indeed suited to this task, one can look, for example, to whether it returns \emph{calibrated} probabilities, which has hitherto not been done in this field. Therefore, this paper aims to establish the current status quo of calibration in XMLC by providing a systematic evaluation, comprising nine models from four different model families across seven benchmark datasets. As naive application of Expected Calibration Error (ECE) leads to meaningless results in long-tailed XMC datasets, we instead introduce the notion of \emph{calibration@k} (e.g., ECE@k), which focusses on the top-$k$ probability mass, offering a more appropriate measure for evaluating probability calibration in XMLC scenarios. While we find that different models can exhibit widely varying reliability plots, we also show that post-training calibration via a computationally efficient isotonic regression method enhances model calibration without sacrificing prediction accuracy. Thus, the practitioner can choose the model family based on accuracy considerations, and leave calibration to isotonic regression.