 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabels in Extremes: How Well Calibrated are Extreme Multi-label Classifiers?
Nov 06, 2024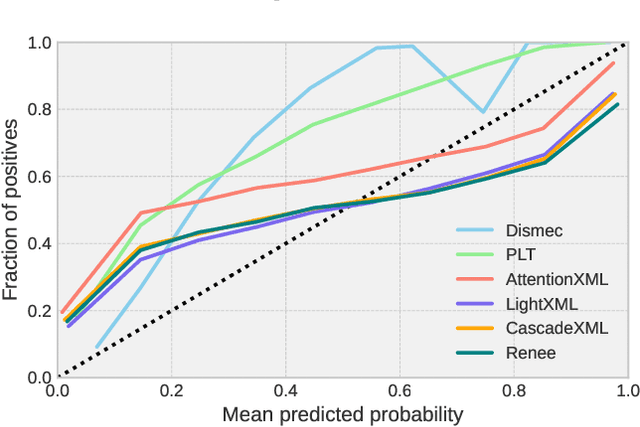


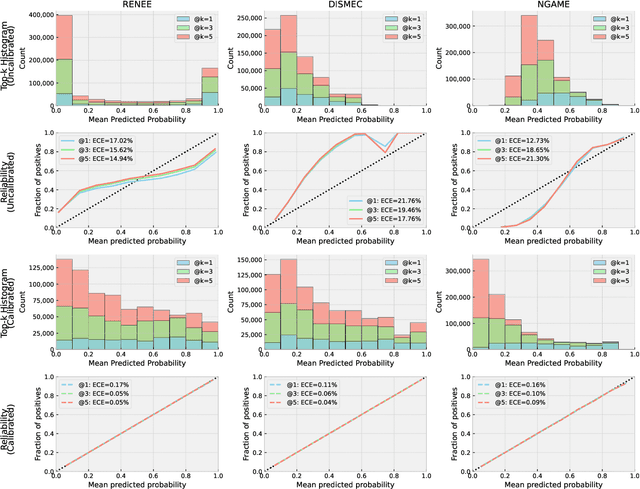
Extreme multilabel classification (XMLC) problems occur in settings such as related product recommendation, large-scale document tagging, or ad prediction, and are characterized by a label space that can span millions of possible labels. There are two implicit tasks that the classifier performs: \emph{Evaluating} each potential label for its expected worth, and then \emph{selecting} the best candidates. For the latter task, only the relative order of scores matters, and this is what is captured by the standard evaluation procedure in the XMLC literature. However, in many practical applications, it is important to have a good estimate of the actual probability of a label being relevant, e.g., to decide whether to pay the fee to be allowed to display the corresponding ad. To judge whether an extreme classifier is indeed suited to this task, one can look, for example, to whether it returns \emph{calibrated} probabilities, which has hitherto not been done in this field. Therefore, this paper aims to establish the current status quo of calibration in XMLC by providing a systematic evaluation, comprising nine models from four different model families across seven benchmark datasets. As naive application of Expected Calibration Error (ECE) leads to meaningless results in long-tailed XMC datasets, we instead introduce the notion of \emph{calibration@k} (e.g., ECE@k), which focusses on the top-$k$ probability mass, offering a more appropriate measure for evaluating probability calibration in XMLC scenarios. While we find that different models can exhibit widely varying reliability plots, we also show that post-training calibration via a computationally efficient isotonic regression method enhances model calibration without sacrificing prediction accuracy. Thus, the practitioner can choose the model family based on accuracy considerations, and leave calibration to isotonic regression.
Navigating Extremes: Dynamic Sparsity in Large Output Space
Nov 05, 2024



In recent years, Dynamic Sparse Training (DST) has emerged as an alternative to post-training pruning for generating efficient models. In principle, DST allows for a more memory efficient training process, as it maintains sparsity throughout the entire training run. However, current DST implementations fail to capitalize on this in practice. Because sparse matrix multiplication is much less efficient than dense matrix multiplication on GPUs, most implementations simulate sparsity by masking weights. In this paper, we leverage recent advances in semi-structured sparse training to apply DST in the domain of classification with large output spaces, where memory-efficiency is paramount. With a label space of possibly millions of candidates, the classification layer alone will consume several gigabytes of memory. Switching from a dense to a fixed fan-in sparse layer updated with sparse evolutionary training (SET); however, severely hampers training convergence, especially at the largest label spaces. We find that poor gradient flow from the sparse classifier to the dense text encoder make it difficult to learn good input representations. By employing an intermediate layer or adding an auxiliary training objective, we recover most of the generalisation performance of the dense model. Overall, we demonstrate the applicability and practical benefits of DST in a challenging domain -- characterized by a highly skewed label distribution that differs substantially from typical DST benchmark datasets -- which enables end-to-end training with millions of labels on commodity hardware.
Zero-Shot Learning Over Large Output Spaces : Utilizing Indirect Knowledge Extraction from Large Language Models
Jun 13, 2024Extreme Multi-label Learning (XMC) is a task that allocates the most relevant labels for an instance from a predefined label set. Extreme Zero-shot XMC (EZ-XMC) is a special setting of XMC wherein no supervision is provided; only the instances (raw text of the document) and the predetermined label set are given. The scenario is designed to address cold-start problems in categorization and recommendation. Traditional state-of-the-art methods extract pseudo labels from the document title or segments. These labels from the document are used to train a zero-shot bi-encoder model. The main issue with these generated labels is their misalignment with the tagging task. In this work, we propose a framework to train a small bi-encoder model via the feedback from the large language model (LLM), the bi-encoder model encodes the document and labels into embeddings for retrieval. Our approach leverages the zero-shot ability of LLM to assess the correlation between labels and the document instead of using the low-quality labels extracted from the document itself. Our method also guarantees fast inference without the involvement of LLM. The performance of our approach outperforms the SOTA methods on various datasets while retaining a similar training time for large datasets.
Thinking Hallucination for Video Captioning
Sep 28, 2022
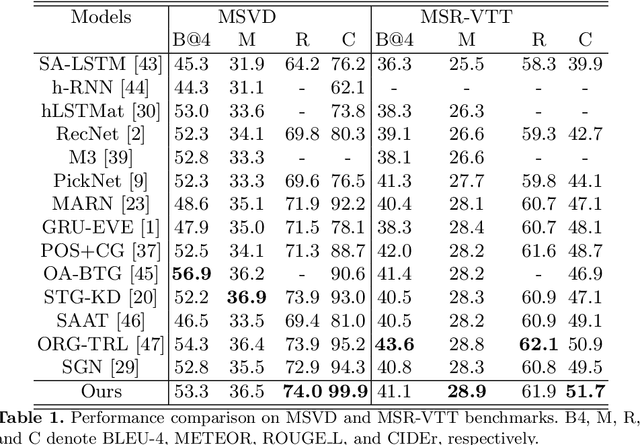
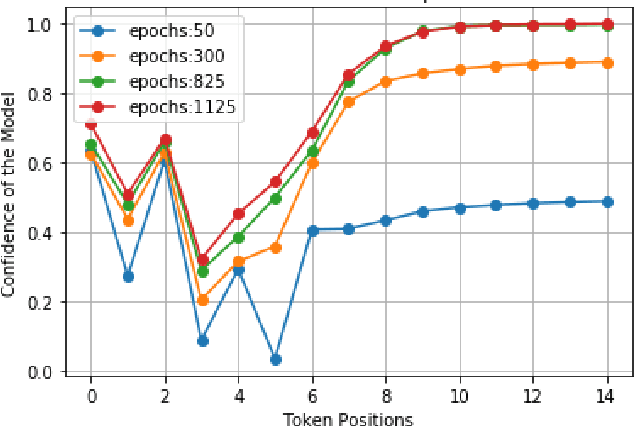
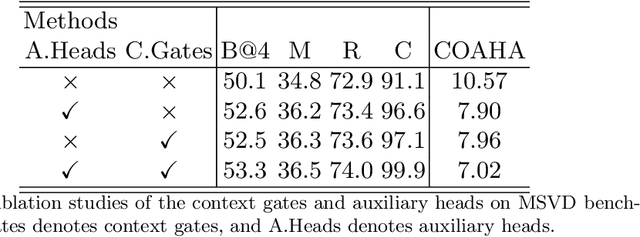
With the advent of rich visual representations and pre-trained language models, video captioning has seen continuous improvement over time. Despite the performance improvement, video captioning models are prone to hallucination. Hallucination refers to the generation of highly pathological descriptions that are detached from the source material. In video captioning, there are two kinds of hallucination: object and action hallucination. Instead of endeavoring to learn better representations of a video, in this work, we investigate the fundamental sources of the hallucination problem. We identify three main factors: (i) inadequate visual features extracted from pre-trained models, (ii) improper influences of source and target contexts during multi-modal fusion, and (iii) exposure bias in the training strategy. To alleviate these problems, we propose two robust solutions: (a) the introduction of auxiliary heads trained in multi-label settings on top of the extracted visual features and (b) the addition of context gates, which dynamically select the features during fusion. The standard evaluation metrics for video captioning measures similarity with ground truth captions and do not adequately capture object and action relevance. To this end, we propose a new metric, COAHA (caption object and action hallucination assessment), which assesses the degree of hallucination. Our method achieves state-of-the-art performance on the MSR-Video to Text (MSR-VTT) and the Microsoft Research Video Description Corpus (MSVD) datasets, especially by a massive margin in CIDEr score.
A Joint Cross-Attention Model for Audio-Visual Fusion in Dimensional Emotion Recognition
Apr 04, 2022
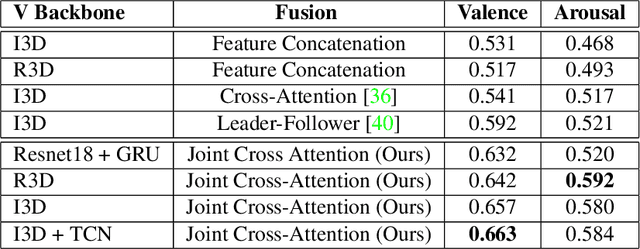
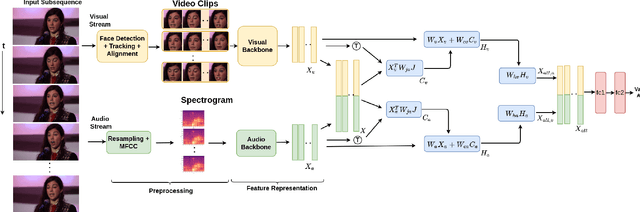
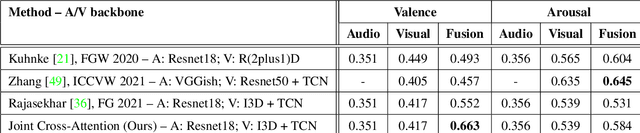
Multimodal emotion recognition has recently gained much attention since it can leverage diverse and complementary relationships over multiple modalities (e.g., audio, visual, biosignals, etc.), and can provide some robustness to noisy modalities. Most state-of-the-art methods for audio-visual (A-V) fusion rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complementary nature of A-V modalities. In this paper, we focus on dimensional emotion recognition based on the fusion of facial and vocal modalities extracted from videos. Specifically, we propose a joint cross-attention model that relies on the complementary relationships to extract the salient features across A-V modalities, allowing for accurate prediction of continuous values of valence and arousal. The proposed fusion model efficiently leverages the inter-modal relationships, while reducing the heterogeneity between the features. In particular, it computes the cross-attention weights based on correlation between the combined feature representation and individual modalities. By deploying the combined A-V feature representation into the cross-attention module, the performance of our fusion module improves significantly over the vanilla cross-attention module. Experimental results on validation-set videos from the AffWild2 dataset indicate that our proposed A-V fusion model provides a cost-effective solution that can outperform state-of-the-art approaches. The code is available on GitHub: https://github.com/praveena2j/JointCrossAttentional-AV-Fusion.