 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseOpt: Addressing Normalization-induced Gradient Skew in Sparse Training
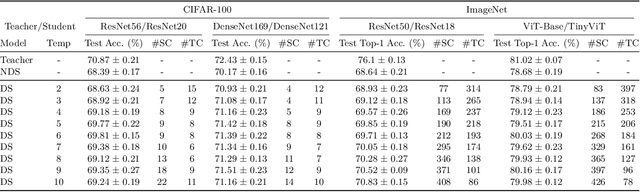
May 26, 2026Dynamic Sparse Training (DST) methods train neural networks by maintaining sparsity while dynamically adapting the network topology. Despite the promise of reduced computation, DST methods converge significantly slower than dense training, often requiring comparable training time to achieve similar accuracy. We demonstrate both analytically and empirically that Batch Normalization (BN) adversely affects sparse training, and propose SparseOpt, a sparsity-aware optimizer, to address this. Experiments on ResNet models across CIFAR-100 and ImageNet demonstrate consistently faster convergence and improved generalization with our proposed method. Our work highlights the limitations of current normalization layers in sparse training and provides the first systematic study of the interaction between Batch Normalization, sparse layers, and DST, taking a significant step toward making DST practically competitive with dense training.
Reducing Hallucinations in LLMs via Factuality-Aware Preference Learning
Jan 06, 2026Preference alignment methods such as RLHF and Direct Preference Optimization (DPO) improve instruction following, but they can also reinforce hallucinations when preference judgments reward fluency and confidence over factual correctness. We introduce F-DPO (Factuality-aware Direct Preference Optimization), a simple extension of DPO that uses only binary factuality labels. F-DPO (i) applies a label-flipping transformation that corrects misordered preference pairs so the chosen response is never less factual than the rejected one, and (ii) adds a factuality-aware margin that emphasizes pairs with clear correctness differences, while reducing to standard DPO when both responses share the same factuality. We construct factuality-aware preference data by augmenting DPO pairs with binary factuality indicators and synthetic hallucinated variants. Across seven open-weight LLMs (1B-14B), F-DPO consistently improves factuality and reduces hallucination rates relative to both base models and standard DPO. On Qwen3-8B, F-DPO reduces hallucination rates by five times (from 0.424 to 0.084) while improving factuality scores by 50 percent (from 5.26 to 7.90). F-DPO also generalizes to out-of-distribution benchmarks: on TruthfulQA, Qwen2.5-14B achieves plus 17 percent MC1 accuracy (0.500 to 0.585) and plus 49 percent MC2 accuracy (0.357 to 0.531). F-DPO requires no auxiliary reward model, token-level annotations, or multi-stage training.
Sparse Training from Random Initialization: Aligning Lottery Ticket Masks using Weight Symmetry
May 08, 2025The Lottery Ticket Hypothesis (LTH) suggests there exists a sparse LTH mask and weights that achieve the same generalization performance as the dense model while using significantly fewer parameters. However, finding a LTH solution is computationally expensive, and a LTH sparsity mask does not generalize to other random weight initializations. Recent work has suggested that neural networks trained from random initialization find solutions within the same basin modulo permutation, and proposes a method to align trained models within the same loss basin. We hypothesize that misalignment of basins is the reason why LTH masks do not generalize to new random initializations and propose permuting the LTH mask to align with the new optimization basin when performing sparse training from a different random init. We empirically show a significant increase in generalization when sparse training from random initialization with the permuted mask as compared to using the non-permuted LTH mask, on multiple datasets (CIFAR-10, CIFAR-100 and ImageNet) and models (VGG11, ResNet20 and ResNet50).
Learning Parameter Sharing with Tensor Decompositions and Sparsity
Nov 14, 2024



Large neural networks achieve remarkable performance, but their size hinders deployment on resource-constrained devices. While various compression techniques exist, parameter sharing remains relatively unexplored. This paper introduces Fine-grained Parameter Sharing (FiPS), a novel algorithm that leverages the relationship between parameter sharing, tensor decomposition, and sparsity to efficiently compress large vision transformer models. FiPS employs a shared base and sparse factors to represent shared neurons across multi-layer perception (MLP) modules. Shared parameterization is initialized via Singular Value Decomposition (SVD) and optimized by minimizing block-wise reconstruction error. Experiments demonstrate that FiPS compresses DeiT-B and Swin-L MLPs to 25-40% of their original parameter count while maintaining accuracy within 1 percentage point of the original models.
Navigating Extremes: Dynamic Sparsity in Large Output Space
Nov 05, 2024



In recent years, Dynamic Sparse Training (DST) has emerged as an alternative to post-training pruning for generating efficient models. In principle, DST allows for a more memory efficient training process, as it maintains sparsity throughout the entire training run. However, current DST implementations fail to capitalize on this in practice. Because sparse matrix multiplication is much less efficient than dense matrix multiplication on GPUs, most implementations simulate sparsity by masking weights. In this paper, we leverage recent advances in semi-structured sparse training to apply DST in the domain of classification with large output spaces, where memory-efficiency is paramount. With a label space of possibly millions of candidates, the classification layer alone will consume several gigabytes of memory. Switching from a dense to a fixed fan-in sparse layer updated with sparse evolutionary training (SET); however, severely hampers training convergence, especially at the largest label spaces. We find that poor gradient flow from the sparse classifier to the dense text encoder make it difficult to learn good input representations. By employing an intermediate layer or adding an auxiliary training objective, we recover most of the generalisation performance of the dense model. Overall, we demonstrate the applicability and practical benefits of DST in a challenging domain -- characterized by a highly skewed label distribution that differs substantially from typical DST benchmark datasets -- which enables end-to-end training with millions of labels on commodity hardware.
What is Left After Distillation? How Knowledge Transfer Impacts Fairness and Bias
Oct 10, 2024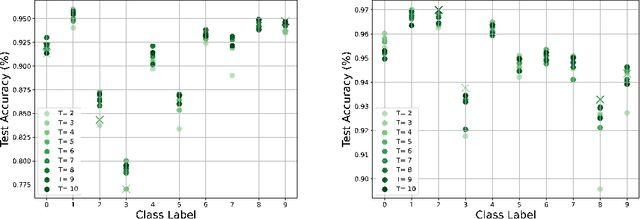
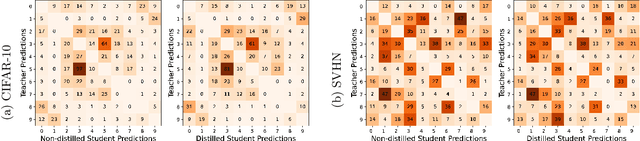
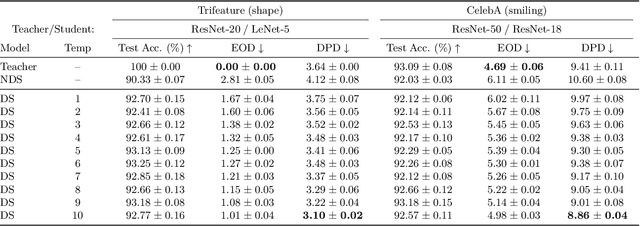
Knowledge Distillation is a commonly used Deep Neural Network compression method, which often maintains overall generalization performance. However, we show that even for balanced image classification datasets, such as CIFAR-100, Tiny ImageNet and ImageNet, as many as 41% of the classes are statistically significantly affected by distillation when comparing class-wise accuracy (i.e. class bias) between a teacher/distilled student or distilled student/non-distilled student model. Changes in class bias are not necessarily an undesirable outcome when considered outside of the context of a model's usage. Using two common fairness metrics, Demographic Parity Difference (DPD) and Equalized Odds Difference (EOD) on models trained with the CelebA, Trifeature, and HateXplain datasets, our results suggest that increasing the distillation temperature improves the distilled student model's fairness -- for DPD, the distilled student even surpasses the fairness of the teacher model at high temperatures. This study highlights the uneven effects of Knowledge Distillation on certain classes and its potentially significant role in fairness, emphasizing that caution is warranted when using distilled models for sensitive application domains.
Trustworthy and Responsible AI for Human-Centric Autonomous Decision-Making Systems
Sep 02, 2024Artificial Intelligence (AI) has paved the way for revolutionary decision-making processes, which if harnessed appropriately, can contribute to advancements in various sectors, from healthcare to economics. However, its black box nature presents significant ethical challenges related to bias and transparency. AI applications are hugely impacted by biases, presenting inconsistent and unreliable findings, leading to significant costs and consequences, highlighting and perpetuating inequalities and unequal access to resources. Hence, developing safe, reliable, ethical, and Trustworthy AI systems is essential. Our team of researchers working with Trustworthy and Responsible AI, part of the Transdisciplinary Scholarship Initiative within the University of Calgary, conducts research on Trustworthy and Responsible AI, including fairness, bias mitigation, reproducibility, generalization, interpretability, and authenticity. In this paper, we review and discuss the intricacies of AI biases, definitions, methods of detection and mitigation, and metrics for evaluating bias. We also discuss open challenges with regard to the trustworthiness and widespread application of AI across diverse domains of human-centric decision making, as well as guidelines to foster Responsible and Trustworthy AI models.
Meta-GCN: A Dynamically Weighted Loss Minimization Method for Dealing with the Data Imbalance in Graph Neural Networks
Jun 24, 2024Although many real-world applications, such as disease prediction, and fault detection suffer from class imbalance, most existing graph-based classification methods ignore the skewness of the distribution of classes; therefore, tend to be biased towards the majority class(es). Conventional methods typically tackle this problem through the assignment of weights to each one of the class samples based on a function of their loss, which can lead to over-fitting on outliers. In this paper, we propose a meta-learning algorithm, named Meta-GCN, for adaptively learning the example weights by simultaneously minimizing the unbiased meta-data set loss and optimizing the model weights through the use of a small unbiased meta-data set. Through experiments, we have shown that Meta-GCN outperforms state-of-the-art frameworks and other baselines in terms of accuracy, the area under the receiver operating characteristic (AUC-ROC) curve, and macro F1-Score for classification tasks on two different datasets.
Dynamic Sparse Training with Structured Sparsity
May 03, 2023



DST methods achieve state-of-the-art results in sparse neural network training, matching the generalization of dense models while enabling sparse training and inference. Although the resulting models are highly sparse and theoretically cheaper to train, achieving speedups with unstructured sparsity on real-world hardware is challenging. In this work we propose a DST method to learn a variant of structured N:M sparsity, the acceleration of which in general is commonly supported in commodity hardware. Furthermore, we motivate with both a theoretical analysis and empirical results, the generalization performance of our specific N:M sparsity (constant fan-in), present a condensed representation with a reduced parameter and memory footprint, and demonstrate reduced inference time compared to dense models with a naive PyTorch CPU implementation of the condensed representation Our source code is available at https://github.com/calgaryml/condensed-sparsity
Bounding generalization error with input compression: An empirical study with infinite-width networks
Jul 19, 2022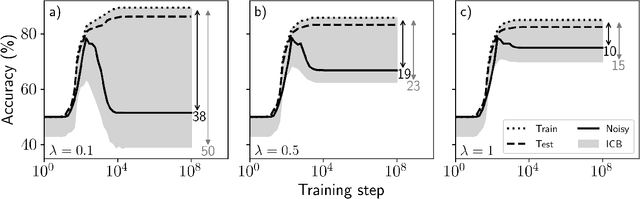

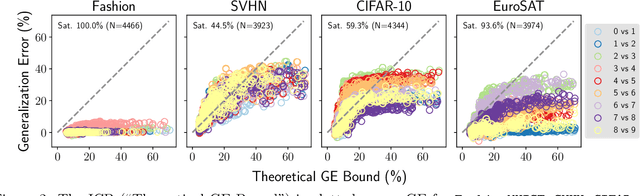
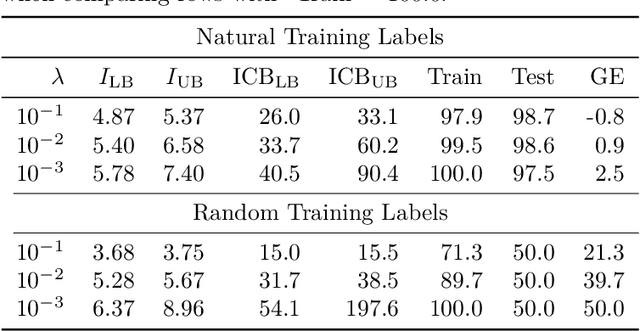
Estimating the Generalization Error (GE) of Deep Neural Networks (DNNs) is an important task that often relies on availability of held-out data. The ability to better predict GE based on a single training set may yield overarching DNN design principles to reduce a reliance on trial-and-error, along with other performance assessment advantages. In search of a quantity relevant to GE, we investigate the Mutual Information (MI) between the input and final layer representations, using the infinite-width DNN limit to bound MI. An existing input compression-based GE bound is used to link MI and GE. To the best of our knowledge, this represents the first empirical study of this bound. In our attempt to empirically falsify the theoretical bound, we find that it is often tight for best-performing models. Furthermore, it detects randomization of training labels in many cases, reflects test-time perturbation robustness, and works well given only few training samples. These results are promising given that input compression is broadly applicable where MI can be estimated with confidence.