 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpark Transformer: Reactivating Sparsity in FFN and Attention
Jun 07, 2025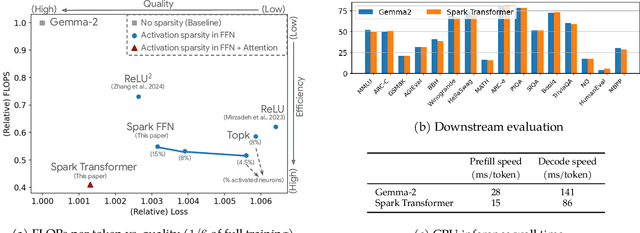
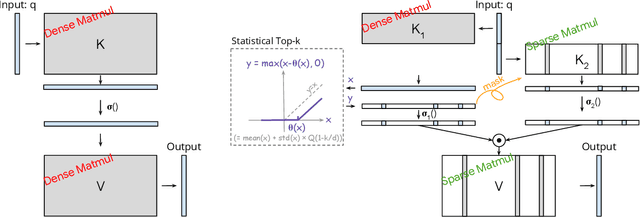
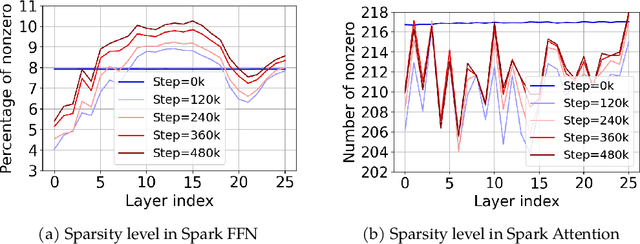
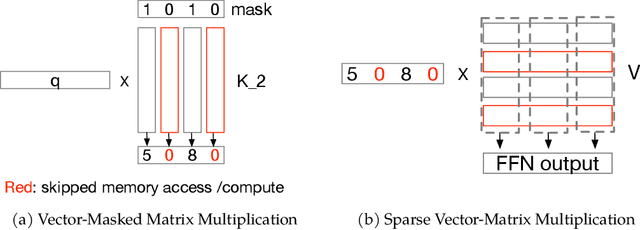
The discovery of the lazy neuron phenomenon in trained Transformers, where the vast majority of neurons in their feed-forward networks (FFN) are inactive for each token, has spurred tremendous interests in activation sparsity for enhancing large model efficiency. While notable progress has been made in translating such sparsity to wall-time benefits, modern Transformers have moved away from the ReLU activation function crucial to this phenomenon. Existing efforts on re-introducing activation sparsity often degrade model quality, increase parameter count, complicate or slow down training. Sparse attention, the application of sparse activation to the attention mechanism, often faces similar challenges. This paper introduces the Spark Transformer, a novel architecture that achieves a high level of activation sparsity in both FFN and the attention mechanism while maintaining model quality, parameter count, and standard training procedures. Our method realizes sparsity via top-k masking for explicit control over sparsity level. Crucially, we introduce statistical top-k, a hardware-accelerator-friendly, linear-time approximate algorithm that avoids costly sorting and mitigates significant training slowdown from standard top-$k$ operators. Furthermore, Spark Transformer reallocates existing FFN parameters and attention key embeddings to form a low-cost predictor for identifying activated entries. This design not only mitigates quality loss from enforced sparsity, but also enhances wall-time benefit. Pretrained with the Gemma-2 recipe, Spark Transformer demonstrates competitive performance on standard benchmarks while exhibiting significant sparsity: only 8% of FFN neurons are activated, and each token attends to a maximum of 256 tokens. This sparsity translates to a 2.5x reduction in FLOPs, leading to decoding wall-time speedups of up to 1.79x on CPU and 1.40x on GPU.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Compression Scaling Laws:Unifying Sparsity and Quantization
Feb 23, 2025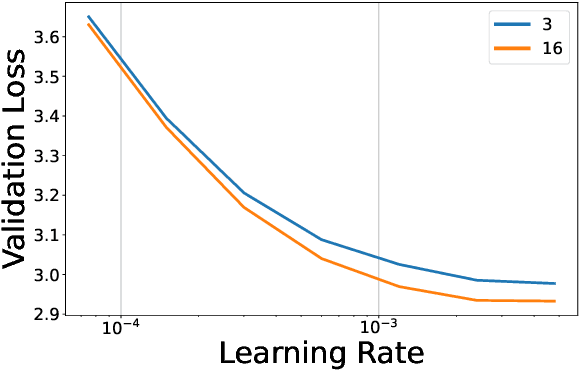
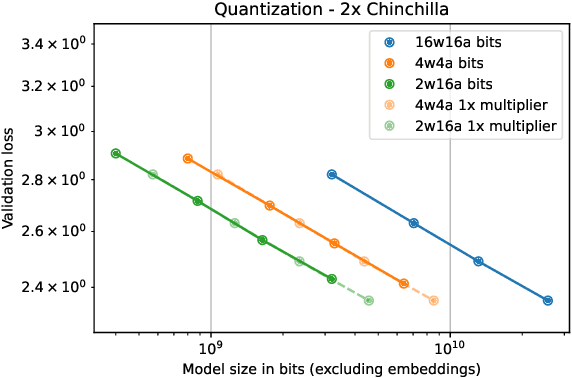
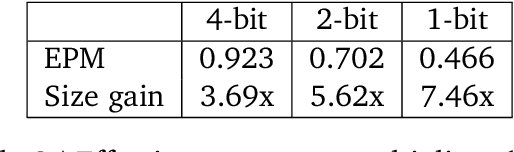
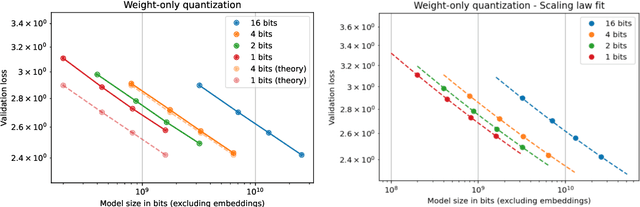
We investigate how different compression techniques -- such as weight and activation quantization, and weight sparsity -- affect the scaling behavior of large language models (LLMs) during pretraining. Building on previous work showing that weight sparsity acts as a constant multiplier on model size in scaling laws, we demonstrate that this "effective parameter" scaling pattern extends to quantization as well. Specifically, we establish that weight-only quantization achieves strong parameter efficiency multipliers, while full quantization of both weights and activations shows diminishing returns at lower bitwidths. Our results suggest that different compression techniques can be unified under a common scaling law framework, enabling principled comparison and combination of these methods.
Learning Parameter Sharing with Tensor Decompositions and Sparsity
Nov 14, 2024



Large neural networks achieve remarkable performance, but their size hinders deployment on resource-constrained devices. While various compression techniques exist, parameter sharing remains relatively unexplored. This paper introduces Fine-grained Parameter Sharing (FiPS), a novel algorithm that leverages the relationship between parameter sharing, tensor decomposition, and sparsity to efficiently compress large vision transformer models. FiPS employs a shared base and sparse factors to represent shared neurons across multi-layer perception (MLP) modules. Shared parameterization is initialized via Singular Value Decomposition (SVD) and optimized by minimizing block-wise reconstruction error. Experiments demonstrate that FiPS compresses DeiT-B and Swin-L MLPs to 25-40% of their original parameter count while maintaining accuracy within 1 percentage point of the original models.
Towards Optimal Adapter Placement for Efficient Transfer Learning
Oct 21, 2024



Parameter-efficient transfer learning (PETL) aims to adapt pre-trained models to new downstream tasks while minimizing the number of fine-tuned parameters. Adapters, a popular approach in PETL, inject additional capacity into existing networks by incorporating low-rank projections, achieving performance comparable to full fine-tuning with significantly fewer parameters. This paper investigates the relationship between the placement of an adapter and its performance. We observe that adapter location within a network significantly impacts its effectiveness, and that the optimal placement is task-dependent. To exploit this observation, we introduce an extended search space of adapter connections, including long-range and recurrent adapters. We demonstrate that even randomly selected adapter placements from this expanded space yield improved results, and that high-performing placements often correlate with high gradient rank. Our findings reveal that a small number of strategically placed adapters can match or exceed the performance of the common baseline of adding adapters in every block, opening a new avenue for research into optimal adapter placement strategies.
Progressive Gradient Flow for Robust N:M Sparsity Training in Transformers
Feb 07, 2024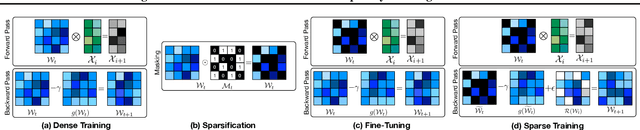


N:M Structured sparsity has garnered significant interest as a result of relatively modest overhead and improved efficiency. Additionally, this form of sparsity holds considerable appeal for reducing the memory footprint owing to their modest representation overhead. There have been efforts to develop training recipes for N:M structured sparsity, they primarily focus on low-sparsity regions ($\sim$50\%). Nonetheless, performance of models trained using these approaches tends to decline when confronted with high-sparsity regions ($>$80\%). In this work, we study the effectiveness of existing sparse training recipes at \textit{high-sparsity regions} and argue that these methods fail to sustain the model quality on par with low-sparsity regions. We demonstrate that the significant factor contributing to this disparity is the presence of elevated levels of induced noise in the gradient magnitudes. To mitigate this undesirable effect, we employ decay mechanisms to progressively restrict the flow of gradients towards pruned elements. Our approach improves the model quality by up to 2$\%$ and 5$\%$ in vision and language models at high sparsity regime, respectively. We also evaluate the trade-off between model accuracy and training compute cost in terms of FLOPs. At iso-training FLOPs, our method yields better performance compared to conventional sparse training recipes, exhibiting an accuracy improvement of up to 2$\%$. The source code is available at https://github.com/abhibambhaniya/progressive_gradient_flow_nm_sparsity.
Scaling Laws for Sparsely-Connected Foundation Models
Sep 15, 2023We explore the impact of parameter sparsity on the scaling behavior of Transformers trained on massive datasets (i.e., "foundation models"), in both vision and language domains. In this setting, we identify the first scaling law describing the relationship between weight sparsity, number of non-zero parameters, and amount of training data, which we validate empirically across model and data scales; on ViT/JFT-4B and T5/C4. These results allow us to characterize the "optimal sparsity", the sparsity level which yields the best performance for a given effective model size and training budget. For a fixed number of non-zero parameters, we identify that the optimal sparsity increases with the amount of data used for training. We also extend our study to different sparsity structures (such as the hardware-friendly n:m pattern) and strategies (such as starting from a pretrained dense model). Our findings shed light on the power and limitations of weight sparsity across various parameter and computational settings, offering both theoretical understanding and practical implications for leveraging sparsity towards computational efficiency improvements.
Dynamic Sparse Training with Structured Sparsity
May 03, 2023



DST methods achieve state-of-the-art results in sparse neural network training, matching the generalization of dense models while enabling sparse training and inference. Although the resulting models are highly sparse and theoretically cheaper to train, achieving speedups with unstructured sparsity on real-world hardware is challenging. In this work we propose a DST method to learn a variant of structured N:M sparsity, the acceleration of which in general is commonly supported in commodity hardware. Furthermore, we motivate with both a theoretical analysis and empirical results, the generalization performance of our specific N:M sparsity (constant fan-in), present a condensed representation with a reduced parameter and memory footprint, and demonstrate reduced inference time compared to dense models with a naive PyTorch CPU implementation of the condensed representation Our source code is available at https://github.com/calgaryml/condensed-sparsity
JaxPruner: A concise library for sparsity research
May 02, 2023


This paper introduces JaxPruner, an open-source JAX-based pruning and sparse training library for machine learning research. JaxPruner aims to accelerate research on sparse neural networks by providing concise implementations of popular pruning and sparse training algorithms with minimal memory and latency overhead. Algorithms implemented in JaxPruner use a common API and work seamlessly with the popular optimization library Optax, which, in turn, enables easy integration with existing JAX based libraries. We demonstrate this ease of integration by providing examples in four different codebases: Scenic, t5x, Dopamine and FedJAX and provide baseline experiments on popular benchmarks.
The Dormant Neuron Phenomenon in Deep Reinforcement Learning
Feb 24, 2023

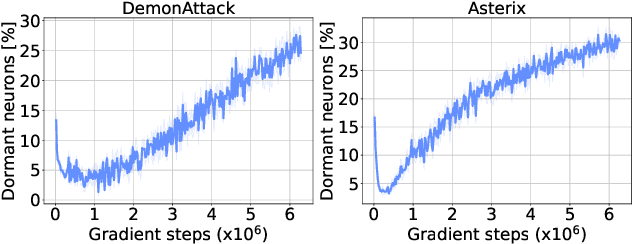

In this work we identify the dormant neuron phenomenon in deep reinforcement learning, where an agent's network suffers from an increasing number of inactive neurons, thereby affecting network expressivity. We demonstrate the presence of this phenomenon across a variety of algorithms and environments, and highlight its effect on learning. To address this issue, we propose a simple and effective method (ReDo) that Recycles Dormant neurons throughout training. Our experiments demonstrate that ReDo maintains the expressive power of networks by reducing the number of dormant neurons and results in improved performance.