 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Can Disaggregation Go? A Design-Space Exploration of Attention-FFN Disaggregation for Efficient MoE LLM Serving
May 27, 2026Modern large language model (LLM) inference has progressively disaggregated to keep pace with growing model sizes and tight TTFT and TPOT service-level objectives: from chunked-prefill aggregation, to prefill-decode (P/D) disaggregation, and most recently to operator-level Attention-FFN Disaggregation (AFD). This trend is especially important for mixture-of-experts (MoE) models, where memory-bound attention, compute-intensive expert FFNs, and MoE dispatch/combine communication create distinct resource demands. AFD further exposes this heterogeneity by placing attention and MoE-FFN execution on separate GPU groups. Each level of disaggregation deepens the scheduling design space across workload characteristics, resource allocation, and interconnect topology, raising the central question: when does each level actually pay off? We systematically characterize this trade-off for MoE inference across realistic workloads spanning input/output sequence lengths, prefix-KV reuse, and per-user latency constraints. Using chunked-prefill and P/D disaggregation as baselines, we study the benefits and limits of AFD at scale through a framework that fuses on-device kernel measurements with high-fidelity network simulation. Under strict TTFT/TPOT SLOs, AFD sustains around 4k tokens/s of system throughput on DeepSeek-V3.2 across chat, coding, and agentic-coding workloads, where non-AFD deployments are infeasible. We distill concrete takeaways for jointly optimizing throughput and interactivity, including how to partition attention and FFN across GPUs as a function of workload and model architecture, providing design principles for current rack- and cluster-scale deployments as well as future disaggregated AI infrastructure.
Understanding and Optimizing Multi-Stage AI Inference Pipelines
Apr 16, 2025The rapid evolution of Large Language Models (LLMs) has driven the need for increasingly sophisticated inference pipelines and hardware platforms. Modern LLM serving extends beyond traditional prefill-decode workflows, incorporating multi-stage processes such as Retrieval Augmented Generation (RAG), key-value (KV) cache retrieval, dynamic model routing, and multi step reasoning. These stages exhibit diverse computational demands, requiring distributed systems that integrate GPUs, ASICs, CPUs, and memory-centric architectures. However, existing simulators lack the fidelity to model these heterogeneous, multi-engine workflows, limiting their ability to inform architectural decisions. To address this gap, we introduce HERMES, a Heterogeneous Multi-stage LLM inference Execution Simulator. HERMES models diverse request stages; including RAG, KV retrieval, reasoning, prefill, and decode across complex hardware hierarchies. HERMES supports heterogeneous clients executing multiple models concurrently unlike prior frameworks while incorporating advanced batching strategies and multi-level memory hierarchies. By integrating real hardware traces with analytical modeling, HERMES captures critical trade-offs such as memory bandwidth contention, inter-cluster communication latency, and batching efficiency in hybrid CPU-accelerator deployments. Through case studies, we explore the impact of reasoning stages on end-to-end latency, optimal batching strategies for hybrid pipelines, and the architectural implications of remote KV cache retrieval. HERMES empowers system designers to navigate the evolving landscape of LLM inference, providing actionable insights into optimizing hardware-software co-design for next-generation AI workloads.
Progressive Gradient Flow for Robust N:M Sparsity Training in Transformers
Feb 07, 2024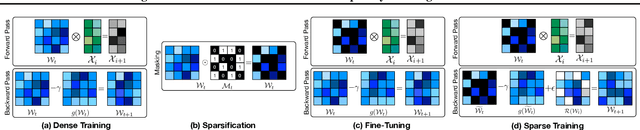


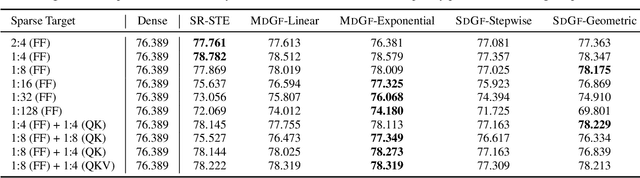
N:M Structured sparsity has garnered significant interest as a result of relatively modest overhead and improved efficiency. Additionally, this form of sparsity holds considerable appeal for reducing the memory footprint owing to their modest representation overhead. There have been efforts to develop training recipes for N:M structured sparsity, they primarily focus on low-sparsity regions ($\sim$50\%). Nonetheless, performance of models trained using these approaches tends to decline when confronted with high-sparsity regions ($>$80\%). In this work, we study the effectiveness of existing sparse training recipes at \textit{high-sparsity regions} and argue that these methods fail to sustain the model quality on par with low-sparsity regions. We demonstrate that the significant factor contributing to this disparity is the presence of elevated levels of induced noise in the gradient magnitudes. To mitigate this undesirable effect, we employ decay mechanisms to progressively restrict the flow of gradients towards pruned elements. Our approach improves the model quality by up to 2$\%$ and 5$\%$ in vision and language models at high sparsity regime, respectively. We also evaluate the trade-off between model accuracy and training compute cost in terms of FLOPs. At iso-training FLOPs, our method yields better performance compared to conventional sparse training recipes, exhibiting an accuracy improvement of up to 2$\%$. The source code is available at https://github.com/abhibambhaniya/progressive_gradient_flow_nm_sparsity.
Subgraph Stationary Hardware-Software Inference Co-Design
Jun 21, 2023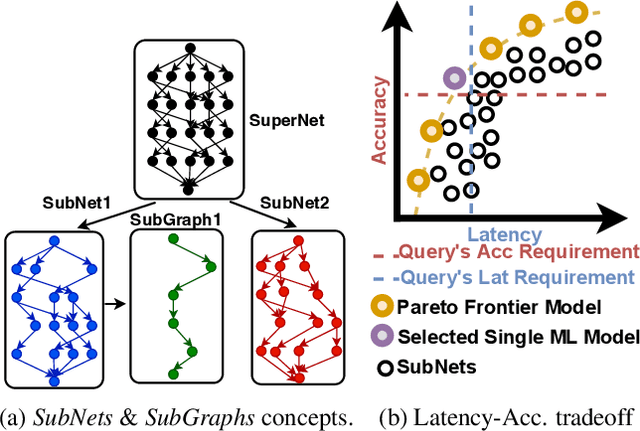



A growing number of applications depend on Machine Learning (ML) functionality and benefits from both higher quality ML predictions and better timeliness (latency) at the same time. A growing body of research in computer architecture, ML, and systems software literature focuses on reaching better latency-accuracy tradeoffs for ML models. Efforts include compression, quantization, pruning, early-exit models, mixed DNN precision, as well as ML inference accelerator designs that minimize latency and energy, while preserving delivered accuracy. All of them, however, yield improvements for a single static point in the latency-accuracy tradeoff space. We make a case for applications that operate in dynamically changing deployment scenarios, where no single static point is optimal. We draw on a recently proposed weight-shared SuperNet mechanism to enable serving a stream of queries that uses (activates) different SubNets within this weight-shared construct. This creates an opportunity to exploit the inherent temporal locality with our proposed SubGraph Stationary (SGS) optimization. We take a hardware-software co-design approach with a real implementation of SGS in SushiAccel and the implementation of a software scheduler SushiSched controlling which SubNets to serve and what to cache in real-time. Combined, they are vertically integrated into SUSHI-an inference serving stack. For the stream of queries, SUSHI yields up to 25% improvement in latency, 0.98% increase in served accuracy. SUSHI can achieve up to 78.7% off-chip energy savings.
VEGETA: Vertically-Integrated Extensions for Sparse/Dense GEMM Tile Acceleration on CPUs
Feb 23, 2023



Deep Learning (DL) acceleration support in CPUs has recently gained a lot of traction, with several companies (Arm, Intel, IBM) announcing products with specialized matrix engines accessible via GEMM instructions. CPUs are pervasive and need to handle diverse requirements across DL workloads running in edge/HPC/cloud platforms. Therefore, as DL workloads embrace sparsity to reduce the computations and memory size of models, it is also imperative for CPUs to add support for sparsity to avoid under-utilization of the dense matrix engine and inefficient usage of the caches and registers. This work presents VEGETA, a set of ISA and microarchitecture extensions over dense matrix engines to support flexible structured sparsity for CPUs, enabling programmable support for diverse DL models with varying degrees of sparsity. Compared to the state-of-the-art (SOTA) dense matrix engine in CPUs, a VEGETA engine provides 1.09x, 2.20x, 3.74x, and 3.28x speed-ups when running 4:4 (dense), 2:4, 1:4, and unstructured (95%) sparse DNN layers.
COMET: A Comprehensive Cluster Design Methodology for Distributed Deep Learning Training
Nov 30, 2022Modern Deep Learning (DL) models have grown to sizes requiring massive clusters of specialized, high-end nodes to train. Designing such clusters to maximize both performance and utilization to amortize their steep cost is a challenging task requiring careful balance of compute, memory, and network resources. Moreover, a plethora of each model's tuning knobs drastically affect the performance, with optimal values often depending on the underlying cluster's characteristics, which necessitates a complex cluster-workload co-design process. To facilitate the design space exploration of such massive DL training clusters, we introduce COMET a holistic cluster design methodology and workflow to jointly study the impact of parallelization strategies and key cluster resource provisioning on the performance of distributed DL training. We develop a step-by-step process to establish a reusable and flexible methodology, and demonstrate its application with a case study of training a Transformer-1T model on a cluster of variable compute, memory, and network resources. Our case study demonstrates COMET's utility in identifying promising architectural optimization directions and guiding system designers in configuring key model and cluster parameters.